之前写过一篇博客,OpenGL管线(用经典管线代说着色器内部),说的主要是OpenGL的经典管线。大家都知道,现代OpenGL已经弃用(从OpenGL 3.0开始)经典管线功能(glBegin,变换矩阵,光照,雾,纹理坐标自动生成,等),这些功能可以在需要时由着色器实现。现代OpenGL分为core profile和compatibility profile两个版本(文献[1]Appendix D p682),core profile不包含任何弃用功能,而compatibility profile不删除任何功能,本文要讲的是OpenGL core profile。
所谓OpenGL管线(OpenGL pipeline),就是指OpenGL的渲染过程,即从输入数据到最终产生渲染结果数据所经过的通路及所经受的处理,本文详细解释这一过程。除了讲解OpenGL管线,本文还将解释如何使用OpenGL API实现这些管线功能,也即应用程序如何和着色器(shader,用OpenGL shading language,GLSL编写)接口,这包括应用程序和着色器以及着色器之间如何通信。
在正式进入OpenGL管线之前我们先来看看有关OpenGL Context(OpenGL上下文环境)的问题,在使用OpenGL之前必须先创建OpenGL Context,并将此OpenGL Context “make current”(线程的current context)。OpenGL标准并不定义如何创建OpenGL Context,这个任务由其他标准定义,如GLX(linux)、WGL(windows)、EGL(一般在移动设备上用),可以选择创建core profile或compatibility profile,一个GLX的例子请见这里的87-134行。如果创建的是core profile OpenGL context,调用如glBegin()等兼容API将产生GL_INVALID_OPERATION错误(用glGetError()查询)。我们可能希望当我们使用兼容API时(如glBegin()),编译器能够提示编译错误而不是运行时产生OpenGL错误,可以包含"glcorearb.h"这个头文件,并"#define __gl_h_"来屏蔽"<GL/gl.h>"(__gl_h_为<GL/gl.h>的包含守卫宏,可能因实现差异而不同)。
(本博文地址:http://www.cnblogs.com/liangliangh/p/4765645.html,转载版本将得不到作者维护,另欢迎读者指出文中错误,请直接博客后面留言)
OpenGL的执行模型(Execution Model,参考文献[1]2.1 p8) 可以用Client-Server(客户机-服务器)模型来解释:
- Client即我们的OpenGL应用程序(program/application),Server即OpenGL引擎(姑且叫引擎吧),Client(应用程序)通过调用OpenGL API来签发(issue)OpenGL命令(OpenGL command),这些命令由Server(OpenGL引擎,在不至混淆的情况下也称OpenGL或GL)来执行;
- OpenGL(Server)在GPU上执行命令,其处理的数据缓存(buffer、texture等)一般存在于显存(video memory)中,这些缓存可以从应用程序(Client)拷贝数据,也可以拷贝到应用程序;
- OpenGL由固定管线功能部分(fixed function stages)和可编程部分(programmable stages)组成,可编程部分即着色器(shader),用GLSL(OpenGL OpenGL Shading Language,OpenGL着色语言)进行着色器编程;
- 应用程序和OpenGL可以在也可以不在同一台计算机上执行,即Client和Server是网络透明的(network transparent)。一个网络渲染的例子是通过Windows远程桌面在远程计算机上启动OpenGL程序,应用程序在远程计算机执行,而OpenGL命令在本地计算机执行(将几何数据而不是将渲染结果图像通过网络传输)。当Client和Server位于同一台计算机上时,也称GPU为Device,CPU为Host,Device、Host这两个术语通常在用GPU进行通用计算时使用。如无特别说明本文讲解的都是本地渲染的情况;
- OpenGL命令执行的结果是影响OpenGL状态(由OpenGL context保存,包括OpenGL数据缓存)或影响帧缓存;
- 应用程序和OpenGL命令的执行通常是异步的,OpenGL API调用返回并不说明OpenGL执行完了相应命令,但OpenGL保证按签发命令的顺序执行相应命令,至少保证结果和按串行执行的结果是一致的(即一个命令已经对OpenGL状态或帧缓存产生了影响再执行下一条命令),但实际执行过程可能并不如此。存在OpenGL API用于控制应用程序(CPU)和OpenGL(GPU)之间的同步以及和异步相关的查询,此时将OpenGL命令序列看做命令流(command stream)是方便的。同步的典型例子是:glFlush()强制发出所有OpenGL命令并在此函数返回后的有限时间内执行完这些OpenGL命令,glFinish()等待直到此函数之前的OpenGL命令执行完毕才返回;
- 数据绑定(data binding)发生在OpenGL命令调用时,即应用通过OpenGL API传送给OpenGL的数据在API调用时解释,并在调用返回时完成。典型的例子是通过指针指向的数据给OpenGL传送数据(如glBufferData()),在此API调用返回后修改指针指向的数据将不再对OpenGL状态产生影响;
- OpenGL的对象(objects)可以被多个Context共享(参考文献[1]chapter5 p50),此时的对象删除、同步等操作要复杂一些。如无特别说明本文讲解的都是单Context的无共享的情况。
在有了Client-Server相关概念后,下一章我们概览OpenGL管线。
下图摘自文献[3] p8,图中棕色线条是我加入的,表示此阶段为可选。
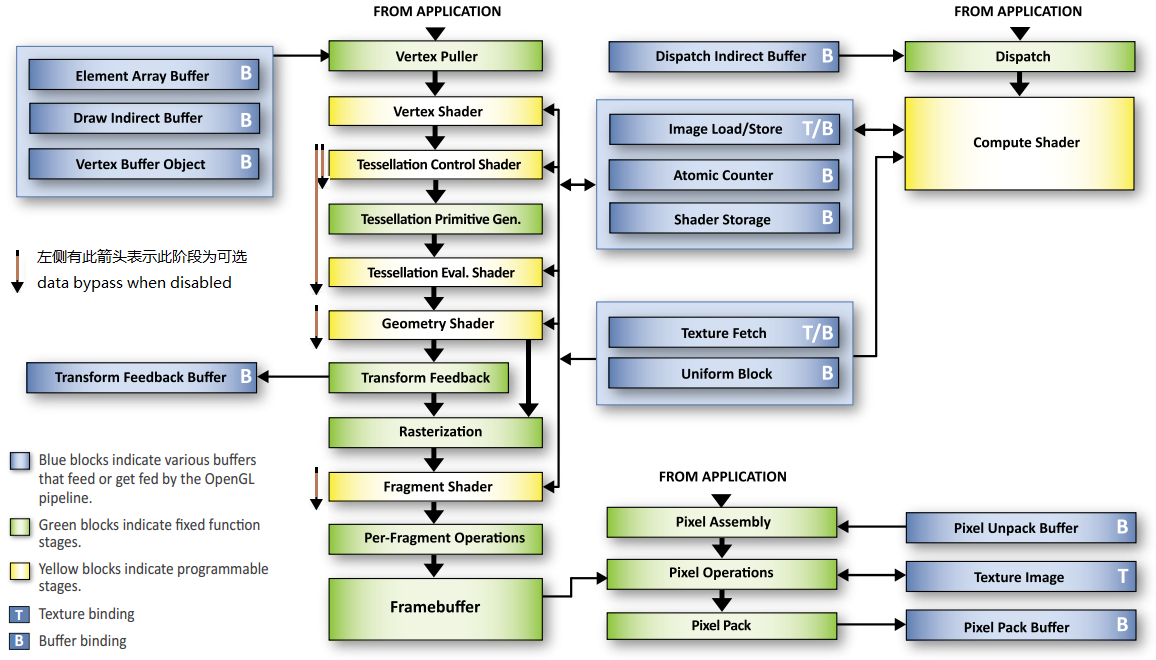
首先解释一下这个图,图中的蓝色框表示数据缓存(data buffers),其右侧字母B为Buffer(缓存),字母T为Texture(纹理),绿色框为固定管线功能(fixed function stages),黄色框为可编程部分(programmable stages)即着色器。图中的箭头表示数据流的方向,例如,看中间的蓝色框,shader可以读和写“Shader Storage” buffer,但只能读“Uniform Block”buffer,当然,应用程序可以读和写任何buffer和texture。一般来说,并不把Compute Shader(计算着色器)当作管线的一部分,它执行通用计算,计算的结果可以用于渲染,Compute Shader是可选的。
从Vertex Puller(顶点拉取)到Framebuffer(帧缓存)的管线中,除了Vertex Shader(顶点着色器)是必须提供之外,其他shader均是可选的,如上图中我用酱色标注的部分,如果没有提供相应shader,数据将不经过加工之间通过。注意Tessellation Control Shader(TCS,细分控制着色器)到Tessellation Evaluation Shader(TES,细分求值着色器)这整个Tessellation(曲面细分)过程是可选的,在Tessellation过程中TCS是可选的,即TCS只能伴随TES存在(否则会报运行时错误,后面细说)。Vertex Shader不可选是因为管线至少要包含一个着色器,而其他着色器存在的前提是存在Vertex Shader(文献[1]7.3 p90),从语义上来说,Vertex Shader定义了整个管线的输入数据。
管线中的每个阶段其输入为上一阶段的输出,其输出作为下一阶段的输入,Vertex Shader的输入和应用程序的顶点属性数据接口,Fragment Shader的输出和帧缓存的颜色缓存接口,互相对接的接口其内容和格式要一致。固定管线功能阶段需要的一些特定输入输出由着色器的内置输出输入变量定义,下图摘自文献[3] p10:

这里,粗略的解释管线各个部分所做的处理,这里说的“管线”在不作特别说明的情况下指从Vertex Puller到Framebuffer:
- Vertex Puller(顶点拉取):管线从供给顶点数据开始。顶点数据中的每个顶点有可任意定义的若干属性,如位置、颜色、纹理坐标等,顶点属性数据存于Vertex Buffer(glBindBuffer( GL_ARRAY_BUFFER, ))中,每个图元(primitive,文献[1]10.1 p322)的顶点索引存于Element Array Buffer(glBindBuffer( GL_ELEMENT_ARRAY_BUFFER, ))中。应用程序通过绘制命令启动管线(如glDrawElements( GL_POINTS/LINES/TRIANGLES/PATCHES, ));
- Vertex Shader(VS,顶点着色器):对每个顶点,OpenGL启动一个VS,VS的输入即每个顶点的全部属性,还包括该顶点的索引(index,由内置变量gl_VertexID指示)等,VS无法访问其他顶点数据(非本VS的输入),VS必须且只能输出一个顶点。VS对顶点进行处理,典型的例子是顶点坐标变换(将顶点齐次坐标乘以模型视图矩阵和投影矩阵)和逐顶点光照;
- Tessellation(曲面细分,可选阶段):又分为Tessellation Control Shader(TCS,细分控制着色器)、Tessellation Primitive Generation(细分图元生成)、Tessellation Evaluation Shader(TES,细分求值着色器),其中TCS是可选的。当Tessellation阶段存在时,只能给管线提供GL_PATCHES类型的图元,不存在时,不能提供GL_PATCHES类型的图元,即Tessellation和GL_PATCHES需同时出现。(1) 对每个PATCH由TCSs处理后输出的PATCH,OpenGL对其每个输出顶点启动一个TCS(该输出顶点在输出PATCH中的索引由gl_InvocationID指示),该TCS可以访问其所在的输入PATCH的全部顶点数据及PATCH的属性(在TCS/TES内部由patch关键字指定),即一个输入PATCH被一组TCSs处理得到一个输出PATCH,组内TCSs的个数等于输出PATCH的顶点数,TCS必须且只能输出一个顶点,并且可以修改其所在输出PATCH的属性。TCS一般对顶点进行操作并计算PATCH的细分水平值(tessellation level,gl_TessLevelOuter[4]/Inner[2],是PATCH的属性),若TCS不存在,该细分水平值均为默认(可通过glPatchParameteri( GL_PATCH_VERTICES, )设置)。(2) Tessellation Primitive Generation根据此细分水平值对每个PATCH在抽象图元上(abstract patch,"triangles"或"quads")进行细分(此阶段仅在TES存在时进行)并给出生成顶点相对抽象图元顶点的相对坐标(gl_TessCoord,包含抽象图元的顶点,其相对坐标某个元素为1其余为0)。(3) 对Tessellation Primitive Generation生成的每个相对坐标,OpenGL启动一个TES,TES可以访问其所在输入PATCH的全部顶点数据及PATCH的属性(即TCS的输出),即TCS输出的PATCH外加相对坐标被一组TESs处理得到一些列输出顶点,组内TESs的个数等于输出顶点数,TES必须且只能输出一个顶点。TES一般用相对坐标从输入PATCH的所有顶点计算输出顶点的齐次坐标(如根据贝塞尔曲面方程计算)。(end) Tessellation输出的顶点(由TES产生)随后被组装为图元(非GL_PATCHES类型图元,后续阶段可以处理);
- Geometry Shader(GS,几何着色器,可选阶段):前面阶段中顶点数据被组装为图元(primitive assembly),其类型由绘制命令的参数或TES的输出决定。对每个图元,OpenGL启动一个GS,可以定义对每个图元启动多个GS(GS中"layout(invocations=?) in;"),GS可以输出零个至多个新的图元(用EmitVertex()、EndPrimitive()等),GS不能访问除输入图元之外的图元,当图元类型为GL_*_ADJACENCY时,每个图元带有邻接信息,该邻接信息在GS不存在时将被忽略。可以指定将GS的输出定向到特定Stream中,只有Stream 0中的数据会继续进入Transform Feedback之后的图元裁剪、光栅化阶段,可以同时定向CS的输出至多个Stream(此时图元类型受限制),若GS不存在,图元数据都将进入Stream 0。GS一般用作几何计算,如Shadow Volumes。(end) 从VS到GS的阶段合起来称为顶点处理(vertex processing),顶点处理阶段应该对内置变量gl_Position进行写入(可在VS到GS的任何阶段),否则其值是未定义的(undefined),该裁剪空间的齐次坐标(clip coordinates)是后续阶段(图元裁剪、光栅化等)需要的;
- Transform Feedback(变换反馈,可选阶段):在GS之后,可以开启一个固定管线功能阶段,若开启(用glBeginTransformFeedback()开启,glEndTransformFeedback()关闭,即在它们之间的绘制结果被记录),顶点处理的结果即输出的图元可以被写入Transform Feedback Buffer(glBindBuffer( GL_TRANSFORM_FEEDBACK_BUFFER, )),Transform Feedback过程仅记录数据不对图元进行处理,即图元直接通过(bypass)。记录在buffer中的数据在随后又可以被用来进行绘制(用glDrawTransformFeedback()等);
- Vertex Post-Processing(顶点后处理):顶点处理的结果即输出的图元,其顶点的位置(gl_Position)是裁剪空间的齐次坐标(clip coords),图元在此空间内进行裁剪(clipping),随后进行透视除法(perspective divide)转换为规范化坐标(normalized coords),然后进行视口变换(viewport transform)转换为窗口坐标(window coords),该坐标将在光栅化阶段使用,多边形图元将根据其顶点在二维窗口中的环绕方向(顺时针或逆时针,可通过二维向量叉乘结果的符号确定)被指定为正面或背面(front/back-facing)。顶点的其他属性不进行这些变换操作,但在图元被裁剪产生新顶点时,这些属性值被插值;
- Rasterization(光栅化):顶点后处理的图元其顶点为窗口坐标,光栅化阶段将确定哪些像素属于图元,对于属于图元的像素,从图元的顶点属性插值得到相应像素属性,这些具有和顶点一样属性格式的像素即“片断”(fragment)。插值的方式一般在裁剪空间进行(窗口空间的权值要除以wc),也可以指定在窗口空间进行插值(FS中"layout(noperspective) in;"或在VS中"layout(noperspective) out;")或不进行插值(FS中"layout(flat) in;"或在VS中"layout(flat) out;"),但对于纹理坐标等属性在窗口空间插值将得到错误结果;
- Fragment Shader(FS,片断着色器,可选阶段):对于光栅化产生的每个片,OpenGL启动一个FS,FS的输入数据即片断的坐标(gl_FragCoord)、图元ID(gl_PrimitiveID)等内置变量及其他定义的属性,FS无法访问其他片断(尤其是同一图元的片断)。FS可以丢弃(用discard关键字)但至多输出一个片断,FS的输出和应用程序的帧缓存接口,内置变量gl_FragDepth对应深度缓存,其他属性统称为“颜色”(colors),和颜色缓存对应;VS、TCS、TES、GS、FS均可以读写Image/Atomic Counter/Shader Storage Buffer,可以读Texture/Uniform Block Buffer(buffer参考文献[1]6.1 p58及API reference页);
- Per-Fragment Operations(逐片断操作):对FS或光栅化的输出片断,在将其写入帧缓存之前,要进行一些列操作,依次是:Stencil Test、Depth BuffrTest、Occlusion Query、Blending、Logicop等,其中前三个操作可以提前到FS之前(FS中"layout(early_fragment_tests) in;"),这样将减少FS的调用次数。通过这些操作并且未被丢弃的片断将被写入帧缓存;
- Framebuffer(帧缓存):帧缓存最多由深度缓存(depth buffer)、模板缓存(stencil buffer)、若干颜色缓存(color buffers),帧缓存本身是个容器,将具体缓存加入帧缓存的操作称为attach(这些具体缓存称为attachment),缓存的数据统称为像素数据。可以通过缓存或纹理直接写入或读取像素数据,即Pixel Unpack/Pack Buffer;
- Compute Shader(CS,计算着色器,独立阶段):CS不能和其他着色器一同链接到同一个Program对象(文献[1] p91),和上面说的图形/渲染管线相对,可以认为CS独自构成计算管线。和CUDA类似,CS分为两层线程模型被调用,内层为多个Invocation构成Work Group(Group内线程ID由gl_LocalInvocationID指示),多个Work Group再构成Dispath(Dispatch内Group ID由gl_WorkGroupID指示),可以在内层声明Work Group内共享的变量(用shared关键字),Work Group内还支持高效的同步机制,Dispatch整体共享Image/Atomic Counter/Shader Storage/Texture/Uniform Block Buffer,这也是CS和VS、TCS、TES、GS、FS通信的方式。
下面,我们将深入管线每个阶段的内部。
【这是一篇从很早很早就开始写的博客,还没有写完,作者现在不在从事OpenGL相关开发了,所以估计也很难完成了吧,但看着写了这么多,还是发出来吧】
2.1 - 1;2.2 - 234;2.3 - 56;2.4 - 7;2.5 - 8;2.6 - 9 10;2.7 - 11;
pipeline obj,buffer,UIform, opaque
2.2 顶点处理
加个图,在框图中标出这部分
2.3 顶点后处理
2.4 光栅化
2.5 片断着色器
2.6 逐片断操作及写入帧缓存
2.7 计算着色器
(by gl, GL_, and GL, respectively)
有道笔记,glerror
- The OpenGL Graphics System: A Specification, Version 4.5 (Core Profile), May 28, 2015. OpenGL Core Profile官方手册,详细定义OpenGL机制;
- The OpenGL Shading Language, Language Version: 4.50, Document Revision: 5, 30-Jan-2015. GLSL官方手册,定义GLSL语言;
- OpenGL 4.5 API Reference Card, Rev. 0814. GL API、GLSL API速查手册,内含精美的管线图;
- OpenGL 4.5 Reference Pages. GL API、GLSL Functions、GLSL Built-In Variables,详细描述了API在不同情况下产生的影响、错误等;
- OpenGL Wiki.(Overview,Vertex Specification,Vertex Processing,Vertex Post-Processing,Primitive Assembly,Rasterization,Fragment Shader,Per-Sample Processing)
- The OpenGL Graphics System: A Specification, Version 4.5 (Compatibility Profile), May 28, 2015
- Lighthouse3d.com, GLSL Tutorial – Core.
- OpenGL管线(用经典管线代说着色器内部).