本人的开发环境:
1.虚拟机centos 6.5
2.jdk 1.8
3.spark2.2.0
4.scala 2.11.8
5.maven 3.5.2
在开发和搭环境时必须注意版本兼容的问题,不然会出现很多莫名其妙的问题
1.启动spark master
./start-master.sh
2.启动worker
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
步骤1,2是必须在启动任务之前的。注意worker必须和flume的agent在同一节点,我这里是一台服务器调试,所以直接在同一台机器调试,相当于在一个端口A流出数据(telnet实现),获取数据并流入到同一IP的另一个端口B(flume实现),监听端口B数据并流式处理(Spark Streaming),写入数据库(mysql)。
3.spark streaming代码开发,flume push方式
package com.spark
import java.sql.DriverManager
import com.spark.ForeachRDDApp.createConnection
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePushSparkStreaming {
def main(args: Array[String]): Unit = {
if( args.length != 2 ) {
System.out.print("Usage:flumepushworkCount <hostname> <port>")
System.exit(1)
}
val Array(hostname, port) = args
val sparkConf = new SparkConf()
val ssc = new StreamingContext(sparkConf, Seconds(5))
val flumeStream = FlumeUtils.createStream(ssc, hostname, port.toInt)
val result = flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
result.print()
result.foreachRDD(rdd => { //注意1
rdd.foreachPartition(partitionOfRecords => {
val connection = createConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into FlumeWordCount(word, wordcount) values('" + record._1 + "'," + record._2 + ")"
connection.createStatement().execute(sql)
})
connection.close()
})
})
ssc.start()
ssc.awaitTermination()
}
/**
* 获取MySQL的连接
*/
def createConnection() = {
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection("jdbc:mysql://master:3306/imooc_spark", "root", "root")
}
}
代码很容易理解,在这就不解析了。不过程序还是不够好,还有优化的地方。请看注意1,优化地方:1.使用线程池的方法来连接mysql。2.Spqrk的闭包原理,在集群中,RDD传给执行器的只是副本,一个RDD并不是全部的数据,然而这里写进mysql数据正确是因为在同一个节点调试,所有的RDD只在本机器操作,因此数据都可以写进mysql。如果在集群中,可能结果是不一样的。解决办法:使用collect( )。
4.flume配置
flume_sparkstreaming_mysql.sources = netcat-source
flume_sparkstreaming_mysql.sinks = avro-sink
flume_sparkstreaming_mysql.channels = memory-channel
flume_sparkstreaming_mysql.sources.netcat-source.type = netcat
flume_sparkstreaming_mysql.sources.netcat-source.bind = master
flume_sparkstreaming_mysql.sources.netcat-source.port = 44444
flume_sparkstreaming_mysql.sinks.avro-sink.type = avro
flume_sparkstreaming_mysql.sinks.avro-sink.hostname = master
flume_sparkstreaming_mysql.sinks.avro-sink.port = 41414
flume_sparkstreaming_mysql.channels.memory-channel.type = memory
flume_sparkstreaming_mysql.sources.netcat-source.channels = memory-channel
flume_sparkstreaming_mysql.sinks.avro-sink.channel = memory-channel
flume的配置也很简单,需要注意的是这里是在服务器跑的, 注意黑体的地方,要写服务器的IP地址,而不是本地调试的那个IP。
3.打jar包并提交任务
./spark-submit --class com.spark.FlumePushSparkStreaming --master local[2] --packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 /home/hadoop/tmp/spark.jar master 41414
4.启动flume-push方式
./flume-ng agent --name simple-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume_push_streaming.conf -Dflume.root.logger=INFO,consol
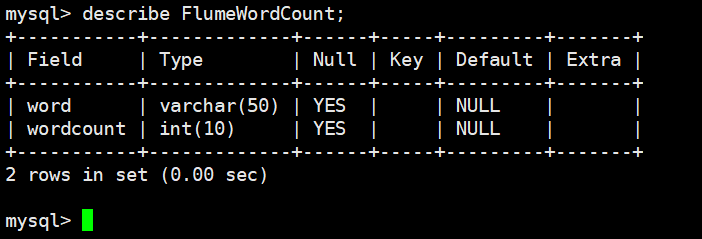
5.建表
create table FlumeWordCount(
word varchar(50) default null,
wordcount int(10) default null
);
6.监听 master : 44444

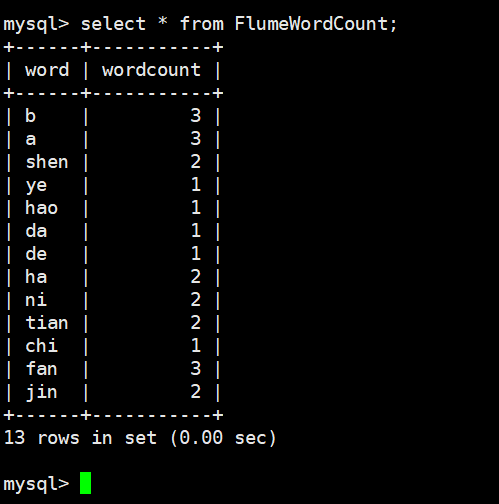
7.mysql 查看数据
mysql> select * from FlumeWordCount;
8.终端打印
