1、分词源码升级一段时间后异常
主要特点:其中几个数据节点 CPU 负载飙升,线程池阻塞
线上升级完分词后,线下测试与压测都没有什么问题,统一大规模上线一段时间后频繁的出现数据节点所在的服务器节点 CPU 飚的非常高,查看日志只看到:
java.lang.OutOfMemoryError: unable to create new native thread,但是并没有从中可以发现有价值的内容。
通过 linux 命令:top、ps aux | grep pid 等命令确定了哪个节点异常后,首先想到是不是数据不均衡导致的,采用:
GET /_cat/segments/xxx_index?v 查看发现 es 经过 hash 计算数据还是比较均衡的。
通过 jstack 打印 Java线程栈的状态,以及通过 es api 接口查看线程池的状态:GET _cat/thread_pool,发现 index 时有异常,进一步查看 index 线程池状态:GET _cat/thread_pool/index
可以 formate:GET /_cat/thread_pool/index?v&h=ip,port,type,name,active,rejected,completed,size,queue,queue_size
这个命令查看到的结果发现 rejected 和 queue 数据量居多,表明拒绝的 和 排队的持续增高,绝对有异常。那么进而通过命令:GET /_nodes/hot_threads 来查看当前有问题的热的线程到底在干什么操作,从这里大概就可以看出问题了。定位到是分词的时候做歧义处理采用递归循环导致无法退出卡死的现象。
以上都是通过 es 的 dev_tools 来查看问题。具体和 jstatck pid 查出来的问题是一样的。
2、批量更新后服务节点异常
主要特点:其中几个数据节点 内存持续 80%以上,内存泄露
经验证,es5.x 机器以下版本都存在,es6.x 没有做验证,怀疑应该也存在相同问题。
由于新上线一个业务,非要实时局部更新 es,我的态度很明确不允许业务和 es 产生直接关联,通过中间件的方式,例如:中间表 mysql/TiDB 等数据库、kafka队列等,业务只需要关系中间件的数据更新就可以了,至于 es 如何更新是由索引系统来处理,根据 ElasticStack系列之十九 & bulk时 index、create 和 update 的区别 我们可知道,做为专业搜索引擎工程师一般不会使用 update 方式,都会通过拼装完成的 data 数据直接 index 到 es,技能保证效率,也能降低 es 的负载和内存使用率。但有时候有些事情不以人的意志为转移,所以最后这个 update 的接口“顺利上线”。
不出意料,一段时间后,其中有几个 data 节点内存持续告警,很明显 full gc 也解决不了问题,线上同时也出现了超时情况,卡顿频出。
为了不影响线上业务,首先保留了线程,之后紧急重启有问题节点,并下线相关接口。之后就平稳了,再来分析问题吧。
通过排查总结如下:
1. 集群的数据量并不大,占用磁盘空间较小

2. 各节点的 segment memory 和 cache 占用量也较小
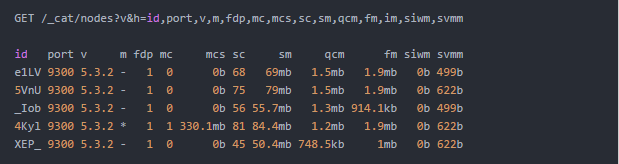
3. 集群的 QPS大概也 50 左右,CPU 平时消耗最高不到 10%,各类 thread pool 活动线程量都比较低
通过以上 3 排查总结,非常费解是什么东西占着 20 多个 GB 内存不释放呢?怀疑是 update 相关操作导致,需要进一步查看日志。
日志大量的报以下信息:
[DEBUG][o.e.a.b.TransportShardBulkAction] [] [suggest-3][0] failed to execute bulk item (update) BulkShardRequest [[suggest-3][0]] containing [44204 ] requests
org.elasticsearch.index.engine.DocumentMissingException: [ type ][纳格尔果德_1198]: document missing
at org.elasticsearch.action.update.UpdateHelper.prepare(UpdateHelper.java:92) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.action.update.UpdateHelper.prepare(UpdateHelper.java:81) ~[elasticsearch-5.5.1.jar:5.5.1]
这是因为写入程序会从数据源拿到数据后,根据 doc_id 对ES里的数据做update。会有部分doc_id在ES里不存在的情况,但并不影响业务逻辑,因而ES记录的document missing异常。
这个日志还不能说明问题,至此别无他法,只能对 JVM 做Dump分析了。
最终发现问题是因为当大量 update es 不存在的 id 时,es 会记录这些 document missing 异常记录,记录的时候使用的 log4j 的 logevent 对一个大的bulk请求对象有强引用而导致其无法被垃圾回收掉,产生内存泄漏。
追踪 es 底层源码发现,日志打印的 logevent 因为被一个MutableLogEvent在引用,而这个MutableLogEvent被做为一个thread local存放起来了。 由于ES的Bulk thread pool是fix size的,也就是预先创建好,不会销毁和再创建。 那么这些MutableLogEvent对象由于是thread local的,只要线程没有销毁,就会对该线程实例一直全局存在,并且其还会一直引用最后一次处理过的ParameterizedMessage。 所以在ES记录bulk exception这种比较大的请求情况下, 整个request对象会被thread local变量一直强引用无法释放,产生大量的内存泄漏。
继续深挖 log4j 源码对应的 MutableLogEvent 发现在org.apache.logging.log4j.util.Constants里,log4j会根据运行环境判断是否是WEB应用,如果不是,就从系统参数 log4j2.enable.threadlocals 读取这个常量,如果没有设置,则默认值是true。由于ES不是一个web应用,导致log4j选择使用了ReusableLogEventFactory,因而使用了thread_local来创建 MutableLogEvent 对象,最终在ES记录bulk exception 这个特殊场景下产生非常显著的内存泄漏。
参考上面的原因,目前线上采用了两种方案,当然这两种方案任何一种都可以解决这类问题:
1. 不允许业务直接通过 update 接口来更新 es 集群
2. 在ES的JVM配置文件jvm.options里,添加一个log4j的系统变量- Dlog4j2.enable.threadlocals=false ,禁用掉thread local即可
3、sug 服务导致服务节点异常
主要特点:其中几个数据节点 CPU 负载飙升,线程池阻塞
之前针对 sug 做了大规模的调优和业务逻辑优化,上线后运行良好,但是一段时间后其中有几个 es data 节点负载飙升,影响整个服务稳定。相关日志如下:
[ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [xx.xx.xx.xx] fatal error in thread [elasticsearch[xx.xx.xx.xx][search][T#29]], exiting
java.lang.StackOverflowError
at org.apache.lucene.util.automaton.Operations.isFinite(Operations.java:1053)
调查后发现,由于业务接口并没有对 query 长度做任何校验和限制,有些恶意攻击或者刷数据的情况导致使用 Prefix/Regex/Fuzzy 一类的 Query,是直接构造的 deterministic automaton,如果查询字符串过长,或者pattern本身过于复杂,构造出来的状态过多,之后一个isFinite的Lucene方法调用可能产生堆栈溢出。
对于我们这次特定的问题,是因为prefix Query里没有限制用户输入的长度。看ES的源码,PrefixQuery继承自Lucene的AutomatonQuery,在实例化的时候,maxDeterminizedStates传的是Integer.MAX_VALUE, 并且生成automaton之前,prefix的长度也没有做限制。 个人认为这里可能应该限制一下大小,避免产生过多的状态。 最终抛出异常的代码是
org.apache.lucene.util.automaton.Operations.isFinite,可以知道这段代码里用了递归,递归的深度取决于状态转移的数量。因为使用了递归,可能导致堆栈溢出。
由此可见,在项目里使用了模糊查询的同学,一定一定要注意限制用户输入长度,否则可能导致集群负载过高或者整个挂掉。