背景
这里介绍的优化是基于 ik 分词源码的优化。首先,我们知道,ik 分词默认有两种分词模式,分别为:ik_max_word 和 ik_smart
这里针对这两种分词方式分别存在的问题有:
ik_max_word :最细粒度分词方式
分的太细了,召回率确实很高,但是会导致召回的内容存在语义问题。例如,北京的一天,召回了 南京的游玩,或者任何地方的一天等等。
ik_smart:最粗颗粒度分词方式
1. 分的太粗,保证了召回的精准性,但是召回率却很低。
2. 存在歧义,导致召回了不是想要的结果集,例如:广西北海 --> 广西 | 西北 | 北海,找回去了西北相关的数据。
ik_smart 消歧逻辑
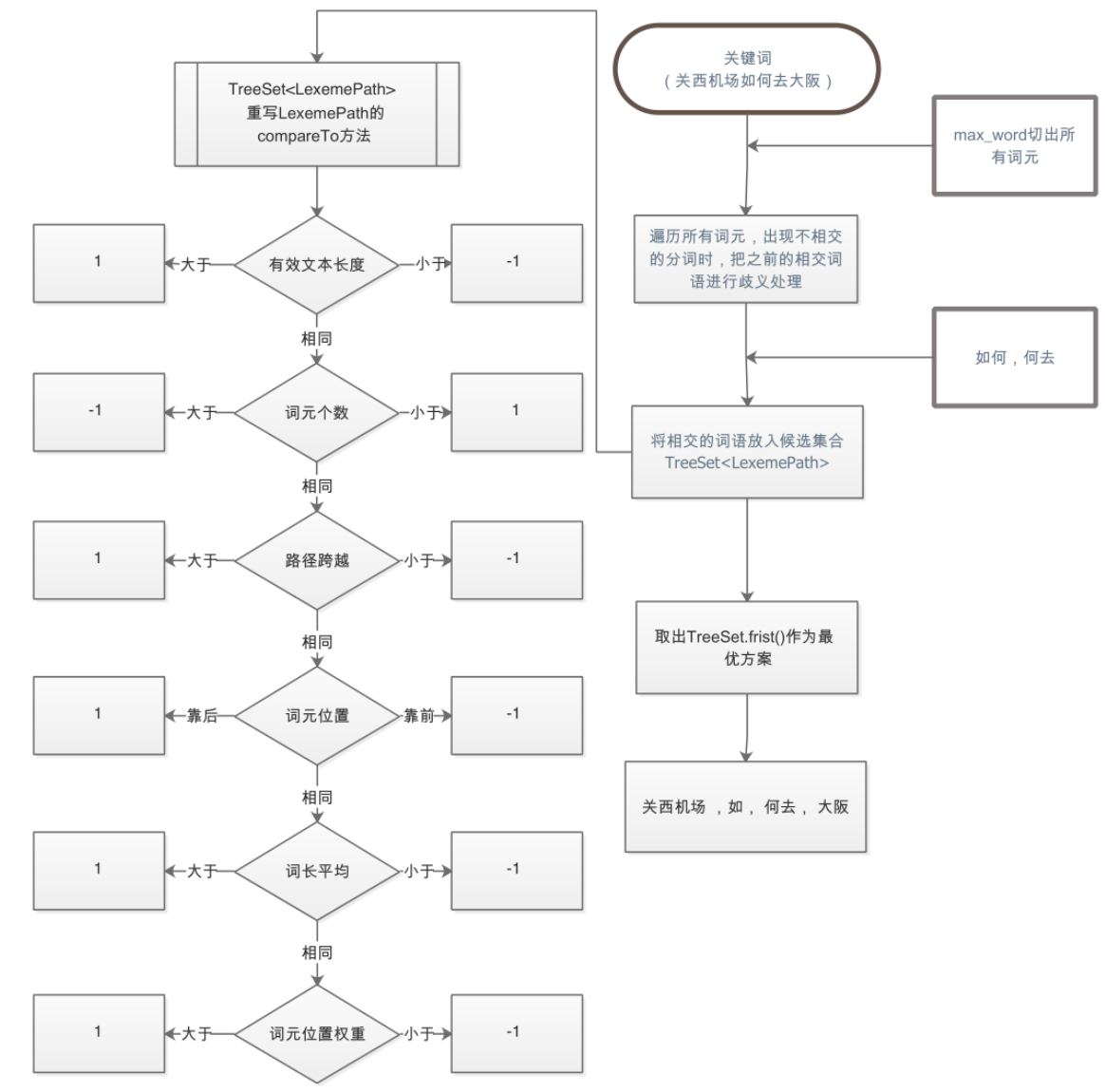
当前 ik_smart 采用的是:贪心算法,分别为:
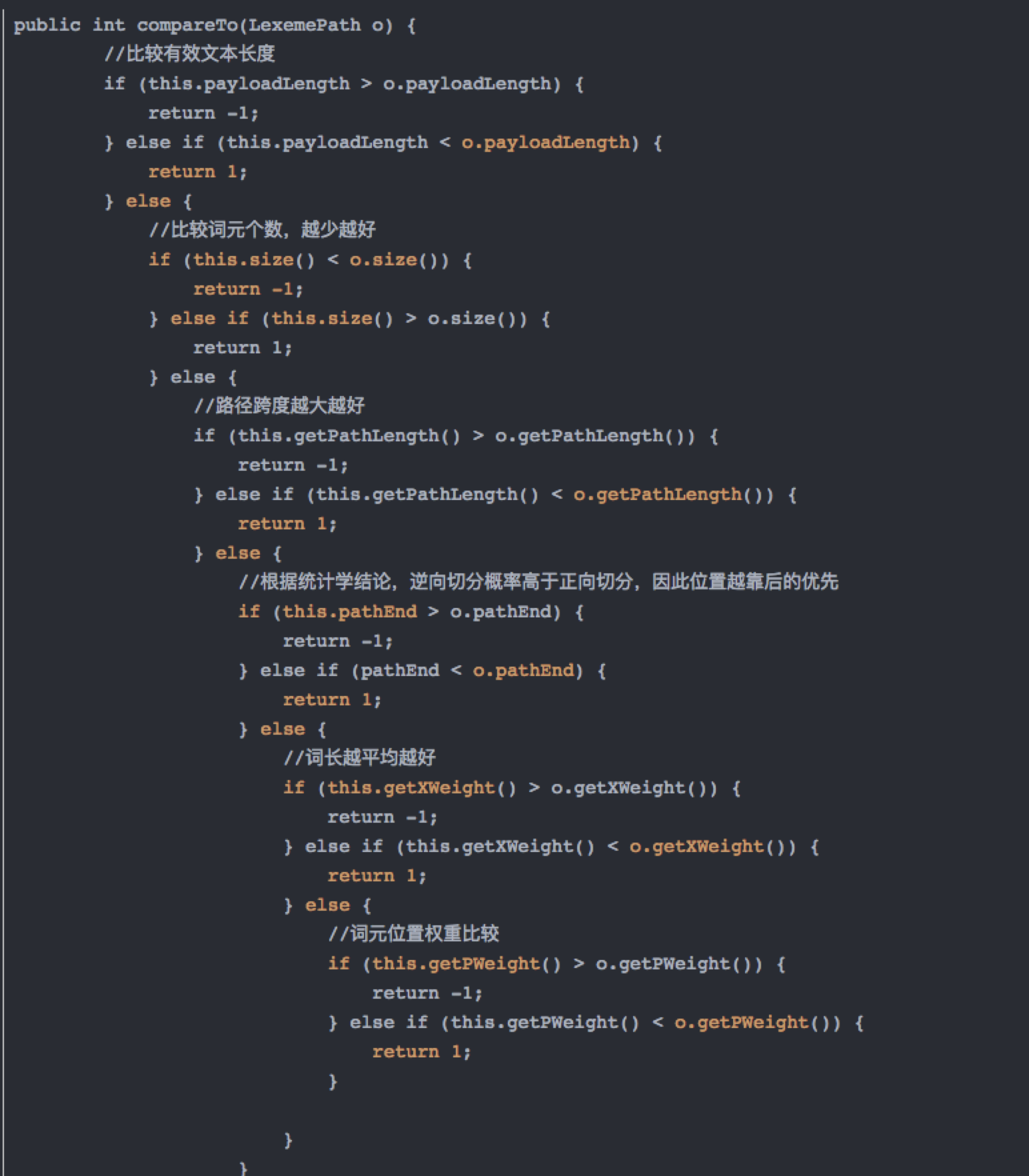
有效文本长度->词元个数->路径跨越->词元位置->词长平均→词元位置权重
可以在该算法的基础上进行改进
优化三部曲
不管做什么优化,前提保证不影响原分词效果,故在原有基础之上增加一种新的分词方式,暂定为:ik
去除语义覆盖的单字
例:玻璃栈道
ik:玻璃栈道 | 玻璃 | 栈道
ik_max_word:玻璃栈道 | 玻璃 | 玻 | 璃 | 栈道 | 道
这里需要注意:在去除单字的时候需要考虑当前 token 所在位置与单字所在位置是否可覆盖,不可覆盖的情况下该单字是不能去除的,例如:
月坨岛华清月府温泉酒店 --> 月坨岛 不能覆盖 华清月府 中的月,故不能因为月坨岛有月,在华清月府中就将单字 月 去掉,这是不对的。
专有名词优化
这个优化一般都是基于行业垂直领域来做的优化。先举例来说吧:
普吉岛、印度尼西亚、香格里拉一日游,分出来的:普吉岛-->吉岛、印度尼西亚-->印度 以及 香格里拉-->里拉,这些都是另外的一个国家地名,都不是这个原词所表达的含义,也就是说想这类专有词就不应该再拆分了,拆分开就会导致语义失真。
优化的方式就是将这些专有名词,这里指的是对应的 mdd、poi 等词用文件固话到 ik 分词器中,启动的时候通过 Dictionary 类去加载到内存,在分词链条中做对应的过滤处理即可。
香格里拉一日游 :原始 ik 分词结果 → 香格里拉|香格|格里拉|格里|里拉|一日游|一日|
新版 ik 分词结果 → 香格里拉|一日游|一日|
去歧处理
借鉴 jieba 分词方式,修改词库文件格式。因为 ik 分词器词典格式为一行一词,需要进行改进,在词典中加入对应挖掘的词频,以及词性。
词典结构为: 单词 词频 词性 ,例如: 西安 2000 n
需要对ik源码中词典结构进行修改。
这里可以提供点改动思路,详情想了解的可以私信我吧,毕竟属于公司内部的:
利用 es 提供的接口,将词库中所有的词分别获取一遍对应的词频,这个是可以取到的。
而且使用 es 获取业务内部的词频更加准确有效,比起从人民日报资源中挖掘出的,直接应用在项目中要好太多了。
其次可以利用第三方接口来得到对应词的词性,这个也很容易拿到,这样词典格式改造就可以轻松的完成了。剩下的就是 ik 源码的改造:
一是首先修改 Dictionary 加载词典的方式;
二是改造去歧逻辑,优化的地方采用的是:
在ik进行前三步判断后: 有效文本长度->词元个数→路径跨越 ,如果还剩多个候选集,后三步骤结合jieba分词中的动态规划计算组合的成词概率来进行去歧处理。