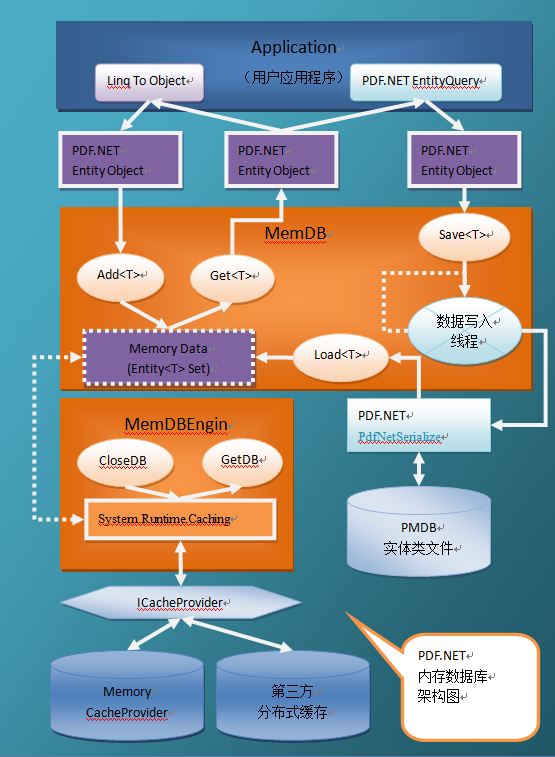
(PDF.NET内存数据库架构图)
架构说明
1,核心类 MemDB
- 一个存储所有实体类集合的集合,即Memory Data,应用程序要取数据,通过Get<T>方法获取(T为实体类类型);
- 当获取数据的时候,如发现Memory Data里面没有,就调用Load<T>方法,从PMDb实体类文件加载数据;
- 当有新实体数据需要保存的时候,调用Add<T>方法;
- 当数据更新以后,如果想保存,就显式的调用一下Save<T>方法,注意,该方法并不直接保存数据,它只保存这个“保存数据的方法”,参见“移花接木”一文的说明;
- 后台维护一个数据写入线程,检查是否有“保存数据的方法”需要执行;
- 数据操作的日志记录。
2,核心类 MemDBEngin
该类实际上就是一个MemDB的工厂类,它会根据不同的数据库“路径”生成一个MemDB对象实例;
MemDB实例的生命周期由“系统缓存”管理,这里使用.NET 4.0的System.Runtime.Caching里面的缓存管理对象。
由于使用了系统缓存,所以MemDB能够做到“按需加载”,“闲置关闭”的功能。
MemDB实例中的Memory Data对应的就是“系统缓存”。
3,ICacheProvider 缓存提供程序接口
定义了一套缓存使用的方法,可以指定缓存策略,如相对过期、绝对过期等。
4,缓存提供程序
系统缓存的默认实现了Memory CacheProvider ,也就是内存缓存提供程序;由于采用接口设计,所以理论上也可以扩展为第三方的“分布式缓存”。
5,数据持久化
整个内存数据库使用的数据都是PDF.NET的实体类,这里使用PDF.NET框架的“序列化”和“反序列化”功能,将内存数据写入磁盘上的pmdb文件,或者从文件加载数据到内存中。
6,用户应用程序
这里是使用“内存数据库”的数据的地方,可以使用多种方式来操作内存数据,比如直接使用Linq To Object来查询内存中的数据,或者使用PDF.NET的EntityQuery对象,实现内存数据库和“关系数据库系统”(DBMS)的数据库间的双向同步。实际使用中,可以完全抛弃DBMS,使用Linq To Object已经足够了。
7,PDF.NET Entity Object
这是整个系统使用的实体数据了,它由相关的组件调用传递。由于PDF.NET实体类的独特设计,使得它的序列化和反序列化效率非常高,另外不使用反射,性能也很好,而且,最重要的,它没有关系数据库那一套“沉重”的数据库元数据标识,所以它非常轻巧,适合作为内存数据库数据的最佳载体。
系统的伸缩能力
纵观整个系统的设计,可以看到它有很好的扩展能力:
- 大型应用--可以很方便的扩展支持第三方分布式缓存,构建大型的系统应用;
- 中小型应用--也可以将常用的DBMS数据放在内存数据库中,提高响应能力;
- 轻微型应用--可以完全抛弃DBMS,使用纯内存数据库,以获得最大的响应速度。