装饰器
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
先看简单例子:
def run(): time.sleep(1) print('run....')
现有一个新的需求,希望可以记录下函数的运行时间,需要在代码中计算时间的代码:
def run(): start_time = time.time() time.sleep(1) print('run....') end_time = time.time() print('run time', end_time - start_time)
login()等多个函数也有类型的需求,怎么做?若在每个函数内都写一个开始、结束时间,然后再算差值,这样代码就冗余了,可以定义一个函数,专门计算执行时间,再执行真的业务代码,如下:
def timer(func): #计算时间 start_time = time.time() func() end_time = time.time() print('run time', end_time - start_time) def run(): #业务代码 time.sleep(1) print('run....') timer(run)
以上代码逻辑不能理解,但这样的话,每次都将一个函数作为参数传递给timer()函数,而且这种方式已经破坏了原有的代码逻辑结构,之前执行业务逻辑时,执行运行run(),但现在不得不运行timer()。使用装饰器,可以解决以上问题。
简单装饰器
def timer(func): #计算时间 def deco(*args, **kwargs): #可以传参 start_time = time.time() func(*args, **kwargs) #函数调用 end_time = time.time() print('run time', end_time - start_time) return deco #return 函数名,函数即变量 def run(): #业务代码 time.sleep(1) print('run....') run = timer(run) #run相当于deco run() #run调用相当于deco()
函数即变量,在python里面的函数就是一个变量、函数名就是一个变量,这个函数名存放的是这个函数的内存地址,它把函数体放到内存里,在调用的时候从函数名里面的这个内存地址找到函数体然后运行这个函数。函数名后面加上小括号就是调用这个函数,如果只写这个函数名的话,打印一下就是这个函数的内存地址。
函数timer就是装饰器,它把执行真正业务方法的func包裹在函数里面,看起来像run被timer装饰了。继续演变如下:
def timer(func): #计算时间 def deco(*args, **kwargs): #可以传参 start_time = time.time() func(*args, **kwargs) #函数调用 end_time = time.time() print('run time', end_time - start_time) return deco #return 函数名,函数即变量 @timer #使用 @ 形式将装饰器附加到函数上时,就会调用此方法.timer(func) 返回的是函数名deco,所以run== deco,函数名即变量,此时run的代码已更新,func() = run之前的代码 def run(): #业务代码 time.sleep(1) print('run....')
run()
run()函数更新后代码如下:其实run的代码并没有直接改动,只是调用装饰器时,run的代码进行了更新。
def run(): start_time = time.time() time.sleep(1) print('run....') end_time = time.time() print('run time', end_time - start_time)
import time def timmer(func): def deco(*arg,**kwarg): start_time=time.time() func(*arg,**kwarg) stop_time=time.time() print('the func run time is %s'%(stop_time-start_time)) return deco @timmer def test1(): time.sleep(1) print('in the test1') @timmer def test2(name,age) : time.sleep(2) print('in the test2:',name,age) test1() test2('niuniu,18)
python 内置函数
print(all([1, 2, 3, 0, 11, -1])) #判断可迭代对象里面的值是否都为真,有一个为假即为False,非空即真非0即真 print(any([0, 1, 2])) #判断可迭代对象里面的值是否有一个为真,即为True print(bin(10)) #将十进制转换为二进制 print(bool('sdf')) #将一个对象转换为布尔类型 func = '' print(callable(func)) #判断传入的对象是否可调用,func为变量不可调用,即返回False def adf(): pass print(callable(adf)) #判断传入的对象是否可调用,adf为方法即可调用,即返回True print(chr(98)) #打印数字对应的ASCII码,98=b print(ord('a')) #打印字符串对应的ASCII码, a=97 print(dict(a=1, b=2)) #转换成字典,{'b': 2, 'a': 1} #print(eval('[a=1]')) print(exec('def a():pass')) #执行python代码,只能执行简单的,定义数据类型和运算 def func(num): name = '88' print(locals()) print(globals()) return num print(list(filter(func, [0, 1, 2, 3, 4]))) #在python3里面这么用是没问题 filter(func, [1, 2, 3, 4]) #根据前面的函数处理逻辑,依次处理后面可迭代对象里面的每个元素,返回true保存 print(list(map(func, [0, 1, 2, 3, 4]))) #根据前面的函数处理逻辑,依次处理后面可迭代对象里面的每个元素,保存前面函数返回的所有结果 </span> print(globals()) #返回程序内所有的变量,返回的是一个字典,函数里面的局部变量不会返回 print(locals()) #返回局部变量 print(hex(111)) #数字转成16进制 print(max(111, 12, 13, 14, 16, 19)) #取最大值 print(oct(111)) #把数字转换成8进制 print(round(11.1198, 2)) #取几位小数,会四舍五入 print(sorted([2, 31, 34, 6, 1, 23, 4], reverse=False))#排序
dic={1:2,3:4,5:6,7:8}
print(sorted(dic.items())) #按照字典的key排序,[(1, 2), (3, 4), (5, 6), (7, 8)]
print(sorted(dic.items(), key=lambda x:x[1])) #按照字典的value排序
import time #导入一个模块
import sys
print(sys.path) #查看系统环境变量有哪些目录
sys.path.append(r'E:python_workspacease-code') #将base-code下的代码添加到环境变量,允许python xxx.py就不报错
from day4.day5_test import hhh
hhh() #直接右键允许不报错,使用python model2.py允许时报错,找不到day4模块No module named 'day4'
random 模块
import random print(random.randint(1, 20)) #在1-19之间随机生成一个整数,随机 print(random.choice('abs123')) #随机取一个元素,随机可迭代对象:字符串、字典、list、元组 print(random.sample('abcdfgrtw12', 3)) #随机取几个元素,3是长度,['2', 'a', 'b'],返回结果是list类型 print(random.uniform(1, 9)) #随机浮点数,随机取1-9之间的浮点数,可指定范围,5.8791750348305625 print(random.random()) #随机0-1的浮点数,0.9465901444615425 random.shuffle([1, 2, 3, 4, 5, 6]) #随机打乱list的值,只能是list
JSON函数
使用 JSON 函数需要导入 json 库:import json。
| 函数 | 描述 |
| json.dumps | 将字典转换为json串 |
| json.dump | 将字典转换的json串写入文件 |
| json.loads | 将json串转换为字典 |
| json.load | 从文件中读取json数据,然后转换为字典 |
举例说明,如下:
a.json内容格式:
{"car":{"price":1100,"color":"red"},"mac":{"price":7999,"color":"black"},"abc":{"price":122,"color":"green"}}
json.load()
import json with open('a.json') as fp: shop_dic = json.load(fp) #从a.json文件内读取数据,返回结果为字典:{'abc': {'price': 122, 'color': 'green'}, 'mac': {'price': 7999, 'color': 'black'}, 'car': {'price': 1100, 'color': 'red'}} print(shop_dic)
json.loads()
s_json = '{"name":"niuniu","age":20,"status":true}' print(json.loads(s_json)) #将json串转换为字典:{'age': 20, 'status': True, 'name': 'niuniu'}
json.dump()
import json with open('a.json', 'a+') as fp: dic = {'name': 'niuniu', 'age': 18} fp.seek(0) fp.truncate() json.dump(dic, fp) #将字典转换为json串写入文件
写入的a.json如下:
{"age": 18, "name": "niuniu"}
json.dumps()
import json dic = {'name': 'niuniu', 'age': 18} print(json.dumps(dic)) #将字典转换为json串:{"name": "niuniu", "age"
扩展小知识点:
将字典内容写入json文件,包含中文。
1. 中文写入json文件后显示乱码,怎么解决? ensure_ascii = False
2. 写入的字典内容显示为不一行,显示不美观,怎么解决? indent = 4
import json d = {"Name": "战神","sex" : ["男","女","人妖"],"Education":{"GradeSchool" : "第一小学","MiddleSchool" : ["第一初中" , "第一高中"], "University" :{ "Name" : "哈佛大学", "Specialty" : ["一年级","二年级"]}}} with open('a.json', 'w', encoding='utf-8') as f: # 中文显示乱码问题, ensure_ascii = False # json格式化问题, indent = 8 # s = json.dumps(d, ensure_ascii=False, indent=8) 字典转换为json 字符串 # f.write(s) #第二种写法 json.dump(d, f, ensure_ascii=False,indent=8)
写入的json文件,a.json:

enumerate 模块
enymerate函数用于将一个可遍历的数据对象(列表,元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环。
小案例:
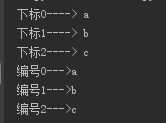
li = ['a', 'b', 'c'] # 常规写法 count = 0 for line in li: print('下标%s----> %s' %(count, line)) count += 1 #enumerate函数 for index, value in enumerate(li): #取下标值,默认从0开始 print('编号%s--->%s' % (index, value))
运行结果:
实际操作:
将list数据写入excel
import xlwt book = xlwt.Workbook() sheet = book.add_sheet('user') stu_list = [ [1, '小明', 'beijing', '186232424', '女'], [2, '小花', 'beijing', '186232424', '女'], [4, 'apple', 'beijing', '186232424', '女'], [5, '橙子', 'beijing', '186232424', '女'], [6, '樱桃', 'beijing', '186232424', '女'], [7, '香蕉', 'beijing', '186232424', '女'], ] #常规写法 row = 1 for row_line in stu_list: # [1, '小明', 'beijing', '186232424', '女'] clow = 0 for clow_line in row_line: # 1 , 小明 sheet.write(row, clow, clow_line) clow += 1 row += 1 # enumerate 函数 for row, row_data in enumerate(stu_list, 1): # 下标从1开始取, row = 1 # row_data : [1, '小明', 'beijing', '186232424', '女'] for clo, clo_data in enumerate(row_data): # enumerate 默认取下标0,clo = 0 # clow_data = 1 / 小明 sheet.write(row, clo, clo_data) book.save('stud.xls')