以下是我在2017 ES 广州 meetup的分享
ppt:https://elasticsearch.cn/slides/11#page=22
摘要
ES最多使用的场景是搜索和日志分析,然而ES强大的实时索引查询、全文检索和聚合能力也能成为数据仓库与OLAP场景的强力支持。本次分享将为大家带来数说故事如何借助ES和Hadoop生态在不同的数据场景下构建起数据仓库能力。
背景
数说故事主要业务为数据商业智能分析,涉及业务包括数字营销、数据分析洞察、消费者连接,同时我们还拥有自己的数据源。
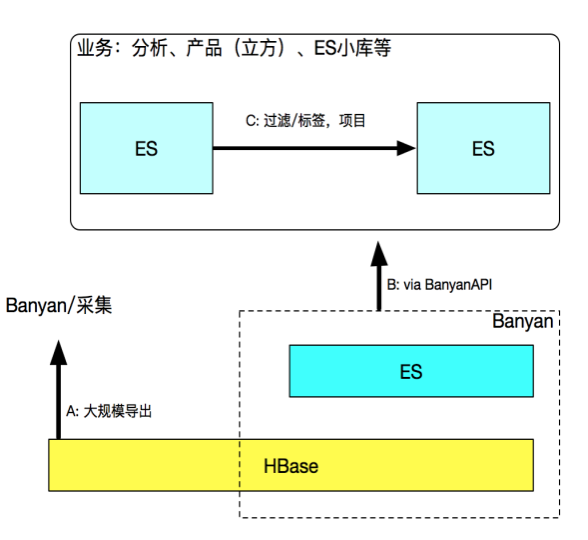
目前我们内部有3种主要取数方式,一种是基于HBase的大规模导出,通俗来说就是Scan HBase扫表,一般用来处理需要全表数据做离线处理的需求。第二种是先从ES query出ID,然后再从HBase get数据,这里ES被当做了HBase的索引层,这种取数方式在我们的业务中用的最多。之所以不从ES取数,一方面是由对ES负担压力比较大,另一方面是无法存放较长的字段。第三种与全量数据库无太多关系,主要涉及业务层面,比如对已有的ES小库做打标签或者ETL操作,然后进行转化写入另一个库,类似数据仓库中将工作表提取出来,然后转换写入另一个表。
基于这些需求我们希望有一个能够统一三种取数模型的解决方案,这也就是Gaia项目的由来,Gaia其实就是离线取数与基础分析能力的构建。
Gaia
Gaia需要解决的问题主要有四点。
- 一是构建Hive on HBase/ ES/Banyan(对于三种取数模式)的能力,由于Banyan是基于ES索引,所以它在构建时要做的事情与ES差不多。
- 二是对不同存储的查询条件优化,在MySQL中使用where条件查询之所以会很快,是因为MySQL已经帮你建立的索引。对应到NoSQL中其实也是一样的,如果where条件没有与索引层建立好关系,select查询就会触发全表扫描,造成很大的负担。
- 三是提供ES特有的查询支持。
- 四是提供拓展性的SQL表达能力。
StorageHandler
在介绍如何构建Hive on ES/Banyan之前,要先讲一下StorageHandler,它是Hive对接外部存储的核心类,主要功能有三个:InputFormat / OutputFormat(如何读写)、MetaHook(如何读写Hive元数据)、Predicate Pushdown(下推优化、分解条件)。
这三个功能中InputFormat在做两件事,首先是InputSplit——按片分割,利用preference制定shard做到并行读取,第二个是RecordReader——内部先scroll一批数据,然后一直调next到当前数据为空时,scroll新一批数据。
之前提过Banyan和ES的取数方式其实差不多,不同之处在于Banyan扩展了自己的StorageHandler和InputFormat。正常情况下ES scroll到数据后会直接传给SearchHit,这里则新增了读Hbase的过程,接着再生产新数据填充给SearchHit。
下推优化
StorageHandler的下推优化在数据库中是一个比较重要的概念,它涉及到了Sargable和谓语下推两个概念。Sargable的全称是Search ARGument ABLE,即SQL中可利用数据库自身索引优势对查询条件进行执行性能优化。一般来说可以优化的为SQL中的WHERE条件,ORDER BY , GROUP BY, HAVING 等有时候可Sargable,当然情况并非绝对,主要还是和实际数据库的支持有关。谓语下推是在实际数据读取和SQL实际执行之前预先执行条件语句进行预处理和过滤。
接下来所讲的就是下推优化的具体实现。
首先从StorageHandler中获取到ExprNodeDesc结点树对象,再基于该对象构建通用的结点树。这一步是可行的过程,一般可以直接基于Hive的原生对象实现,但是我们想要更加定制化的操作以及同时支持HBase和ES不同的存储,所以还是将它给抽了出来。
第二步是自顶向下查询可优化的操作符并进行优化,数据存储的时候已经预先定义好了可优化的操作符。在遇到不可优化的操作符时,会出现两种情况。如果逻辑连接符是AND则跳过当前节点并继续优化兄弟节点,若果是OR则放弃优化。
最后一步是将可优化的结点树转为存储可支持的查询条件(ES Query、HBase Filter等)。
(Hive的源码对象)
在有了构建能力之后,还需要支持ES特有的查询。之所以要怎么做,是由于像es_match、es_matchphrase之类的,如果是在ES的场景下很好实现,但是要用代码实现不仅麻烦而且性能很低。最后我们经过考虑,决定对他们的支持不做具体实现,只是返return true,只用来做下推查询。
ES自动建表
在有很多小表的情况下,如果用户借助数参建表,每次需要使用create table还要写入众多字段。数据和mapping都在的情况下,还要使用这种方式实在是过于繁琐。所以我们给Gaia新增了一个新的特性——ES自动建表,只需要指定es.nodes和es.resource,就可以读取mapping以及数据抽样检查,最后生成完整的create table语句。它的实现是基于SemanticAnalyzerHook 拦截 ASTNode语法树,再读取ES mapping,重写 CREATE 语句。
Gaia-优势
从业务层面来看Gaia减少了写代码的开销和出错率,是更友好的筛选取数工具,同时也为后续的数据分析提供了基础。对平台方来说最重要的是有统一管控计算资源以及审计的能力。
Cube
数说立方(Cube) 是数说故事自研的基于ES的OLAP产品,可提供非技术人员自由的导入数据、维度透视、统计分析等功能。
ES为Cube提供了几点优势。一是即席查询,可以实时查询且灵活度高,只需要索引字段而不用预计算出维度表。二是占用空间小,由于使用ES索引代替维度表,所以空间的开销得以减小。三是全文检索支持,lucene支持。
ES相关技术点
这里先讲下使用Es-hadoop过程中的一些经验。
- 建议使用lasted stable的es-hadoop版本,因为旧版本还是有些隐性BUG,而新版代码更加清晰,对旧版也有很好的兼容。
- 使用时注意一些特殊字段(suggest, array,nested等) ,可能会有坑或不兼容等。比如某个旧版本中在识别到suggest后,就不会再去扫描后续字段。
Es-hadoop还支持跨版本ES的读写。在ES5的时候es-rest被独立出来,用来提供客户端统一接口读写不同版本ES的能力。
Cube通过Schema识别实现了ES表的自动导入,这里主要遇到的问题是ES的数组字段不易识别,因此我们对导入的库做了抽样数据然后进行schema调整。
用户导入的表可能包含众多字段,这就出现了一个问题,即什么样的数据字段可以成为维度。对此除了在产品层面提供给用户配置之外,我们还希望能够进行自动识别。因此用到了Cardinality查询,识别字段的基数,然后设定阀值过滤。
以上为全部分享内容,谢谢大家