参考链接:
linux内核IDR机制详解(一)https://blog.csdn.net/weixin_37867857/article/details/85028303?depth_1-utm_source=distribute.pc_relevant.none-task
linux内核的idr学习(一) https://www.cnblogs.com/zero-jh/p/5184836.html
映射是实现(key,value)绑定的一种数据结构。也称为关联数组。可以视为由唯一key组成的集合。每个key对应这一个value。
常规的映射实现有hash表和二叉树,以及二叉树的变种。
差异
hash表具有相对较好的平均时间复杂度。二叉树有着更好的最坏时间复杂度。
hash表通过hash函数能够映射不同类型的key。二叉树没有hash,更多用于同类key。
hash表中的key经过hash之后是无序的,便于点查找(linkedhashmap是又加了一个指针)。二叉树能够满足顺序保证,便于范围查找。
另外从内存上来说,hash表有效数据的内存占比较小,它的收缩操作太过于浪费时间,不收缩只扩展的话,太浪费内存。
二叉树在内存上释放和扩展有着天然独特的优势。
idr
idr:是用于将uid和一个数据地址进行绑定的一种映射。文件路径为: include/linux/idr.h
由于uid的特殊性:组成元素在固定范围内。相比较于寻常的二叉树,基数树(Redix)显然更适合。
idr中有两个数据结构:idr 和idr_layer
idr数据结构类似于list_head。用于管理idr整个树的信息。其中最关键的是top。它指向了根节点的idr_layer。
struct idr {
struct idr_layer __rcu *hint; /* the last layer allocated from */
struct idr_layer __rcu *top; // idr的顶层(根节点)
int layers; /* only valid w/o concurrent changes */
int cur; /* current pos for cyclic allocation */
spinlock_t lock;
int id_free_cnt;
struct idr_layer *id_free;
};
idr_layer就是每个树中每个节点的数据结构。每个节点有256个指针数组(在64位中,IDR_BITS=8),还有一个槽位图。槽位图是用于快速查找那些指针数组已经被使用。它是由256个bit组成。第x个指针数组被使用,那么第x个bit就被置1。
每个指针数组指向下一层idr_layer。下一层的idr_layer也有一个指针指向它的父节点。
struct idr_layer {
int prefix; /* the ID prefix of this idr_layer */
int layer; /* 第几层 distance from leaf */
struct idr_layer __rcu *ary[1<<IDR_BITS]; /* IDR_BITS = 8 该层有256个指针,指向256个idr_layer*/
int count; /* When zero, we can release it */
union {
/* A zero bit means "space here" */
DECLARE_BITMAP(bitmap, IDR_SIZE); /* 槽位图 */
struct rcu_head rcu_head;
};
};
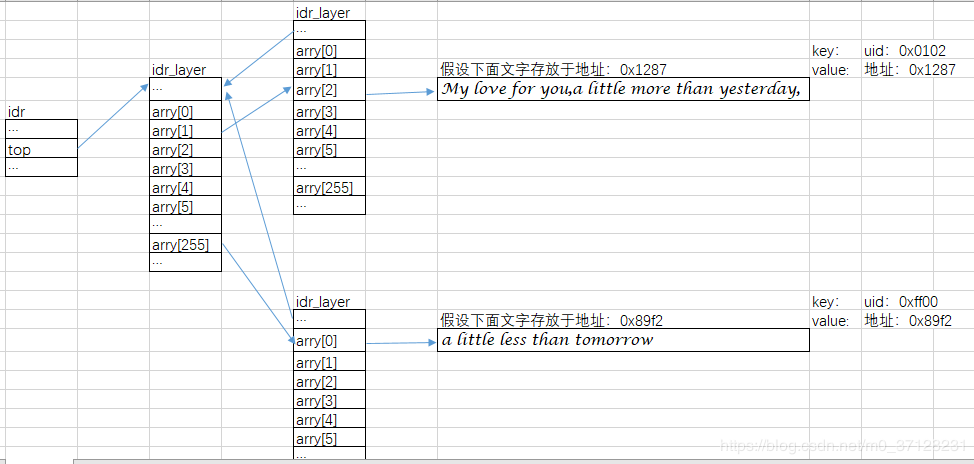
所以idr数据结构的图示为:(只用了两层作为举例)。每层的arry的下标对应着uid的数值组成。
第一句经过arry[1]、array[2]。所以uid1,也就是映射中的key1为0x0102,value1是一个指向My love for you,a little more than yesterday,这段文字的指针。
第二句经过arry[255]、array[0]。所以uid2,也就是映射中的key2为0xff00,value2是一个指向a little less than tomorrow.这段文字的指针。
所以 string=&Lookup(uid1)+&Lookuo(uid2)。得到string为
My love for you,a little more than yesterday,a little less than tomorrow。