单指令多数据流,即SIMD(Single Instruction, Multiple Data)指一类能够在单个指令周期内同时处理多个数据元素的指令集,利用的是数据级并行来提高运行效率,典型的代表由Intel的MMX和SSE指令系列。这类指令的使用环境是对多个数据进行同一种处理,因此典型的应用场景就是多媒体领域,特别是在其中的编解码流程中。
1. SIMD优缺点
1.1 优点
- 效率高:单指令多数据流意味着只需要一个指令周期就能同时对多个数据进行批处理,虽然该类指令本身的指令周期可能会较一般的指令长,但是整体考虑肯定是提高了处理效率。
1.2 缺点
- 适用场景有限:并不是所有的情况都能使用SIMD,有些情况下就算能使用,也需要对原有算法进行不小的改动。
- 增大功耗和芯片面积:因为多数据流,cpu需要更大的寄存器来存储这些数据。
- 人为编写:目前编译器对SIMD的翻译有限,使用时需要开发者人为编写。
- 固定的数据元素个数:例如MMX指令,只能对1个64位、2个32位、4个16位、8个8位数据进行批量处理,其他位长的数据元素需要特殊处理。比如对6个8位元素进行处理,需要额外填充剩余的2个字节。
2. MMX指令简介
MMX指令有8个64位寄存器(MM0~MM7),但MMX实际上并没有硬件支持的新寄存器,它使用浮点寄存器来模拟MMX指令寄存器。
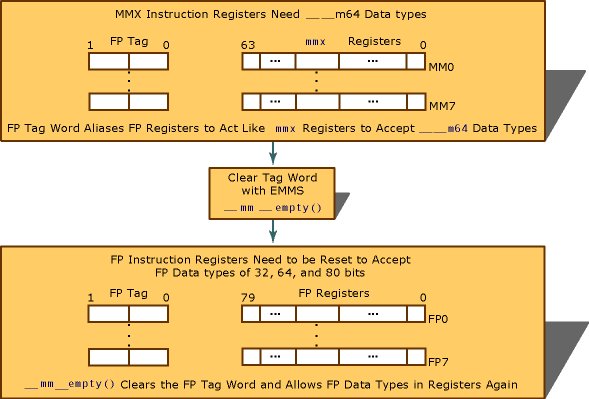
当使用MMX指令的时候,一个叫做FP(Floating Point) Tag 的Word(2字节)被用来映射浮点寄存器到MMX寄存器。这样浮点寄存器就成了MMX寄存器的容器,用来执行计算。从浮点指令切换到MMX指令实在处理器内部完成的,不需要人为的操作;相反,从MMX切换到浮点指令时,需要手动调用emms或者__mm_empty()Intrinsics。
MMX指令与x86指令类似可以分为几类,具体使用及介绍可以参考Oracle的手册,这里不再重复介绍:
- 数据传输指令
- 转换指令
- 算数指令
- 比较指令
- 逻辑运算指令
- 位移指令
- 状态管理指令
3. Intrinsics or Asm
我们可以用通常的汇编嵌入方式在C/C++代码中调用mmx指令,但是这样一来C/C++开发者可能不是很习惯,尤其是它们没有接触过汇编语言的情况下;Intel提供了另一种方式来供开发者选择----Compiler Intrinsics。
Compiler Intrinsics是内建在编译器里的函数,Intrinsics通常会以汇编代码的形式被内联到代码中且具有较高的执行效率,因为编译器知道intrinsics的表现,相比内嵌汇编代码编译器能做更多的优化。
同时,Intrinsics的使用方式是停留在宿主语言层的,所以C语言(通常情况下)相比汇编语言拥有的所有优点,Intrinsics都有(比如我可以对Intrinsics数据类型做类型单位的递增递减)。
4. 效率比较
我们这里分别简单测试C++、Intrinsics(使用MMX)、Asm(使用MMX)三种形式代码的执行效率,示例中我们分别对内存中的100 000 000个字节进行加算数运算:
4.1 C++代码
void calculateUsingCpp(char* data, unsigned size)
{
assert(size % 8 == 0);
unsigned step = 10;
for (unsigned i = 0; i < size; ++i)
{
*data++ += step;
}
}
4.2 Intrinsics代码
Intrinsics代码中,我们每次执行mmx Intrinsics时都打包8个字节的数据并执行加操作,执行完mmx指令后我们需要调用_mm_empty() Intrinsics来取消mmx指令对浮点寄存器的别名映射:
void calculateUsingIntrinsics(char* data, unsigned size)
{
assert(size % 8 == 0);
__m64 step = _mm_set_pi8(10, 10, 10, 10, 10, 10, 10, 10);
__m64* dst = reinterpret_cast<__m64*>(data);
for (unsigned i = 0; i < size; i += 8)
{
auto sum = _mm_adds_pi8(step, *dst);
*dst++ = sum;
}
_mm_empty();
}
4.3 Asm代码
Intel汇编语法在嵌入到高级语言代码中时可以直接使用上下文中的变量,这一点非常方便:
void calculateUsingAsm(char* data, unsigned size)
{
assert(size % 8 == 0);
unsigned loopCount = size / 8;
__int64 value = 0x0a0a0a0a0a0a0a0a;
__asm
{
push eax
push ecx
mov eax, data
mov ecx, loopCount
movq mm1, value
startLoop:
movq mm0, [eax]
paddb mm0, mm1
movq [eax], mm0
add eax, 8
dec ecx
jnz startLoop
emms
pop ecx
pop eax
}
}
5. 运行结果对比
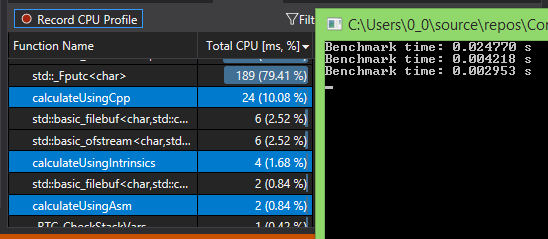
可以看出运行时间比是 8 : 1.5 : 1左右,完整代码见链接。