药监局网址:http://scxk.nmpa.gov.cn:81/xk/
药监局首页:
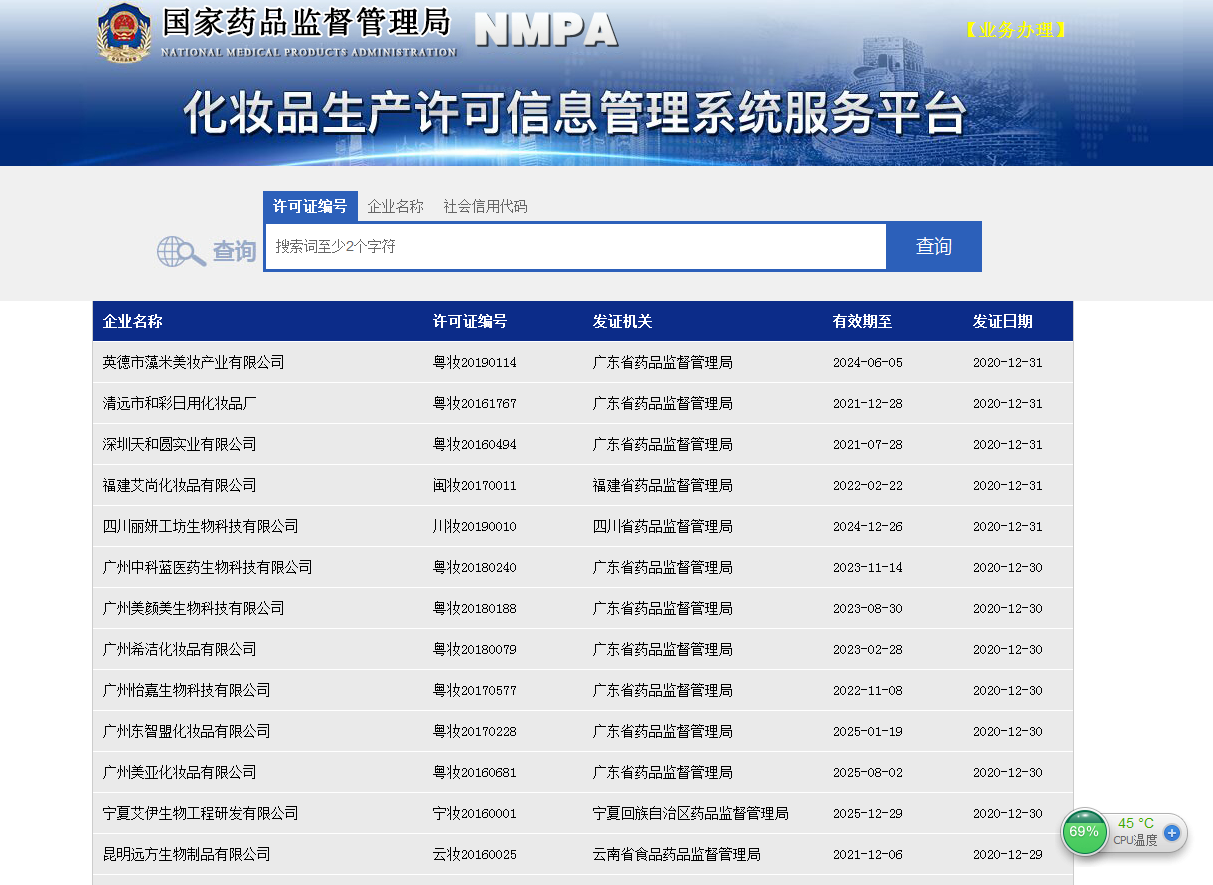
详情页:

目的:爬取药监局所有详情页信息,保存在本地,以csv文件格式保存。
分析主页:
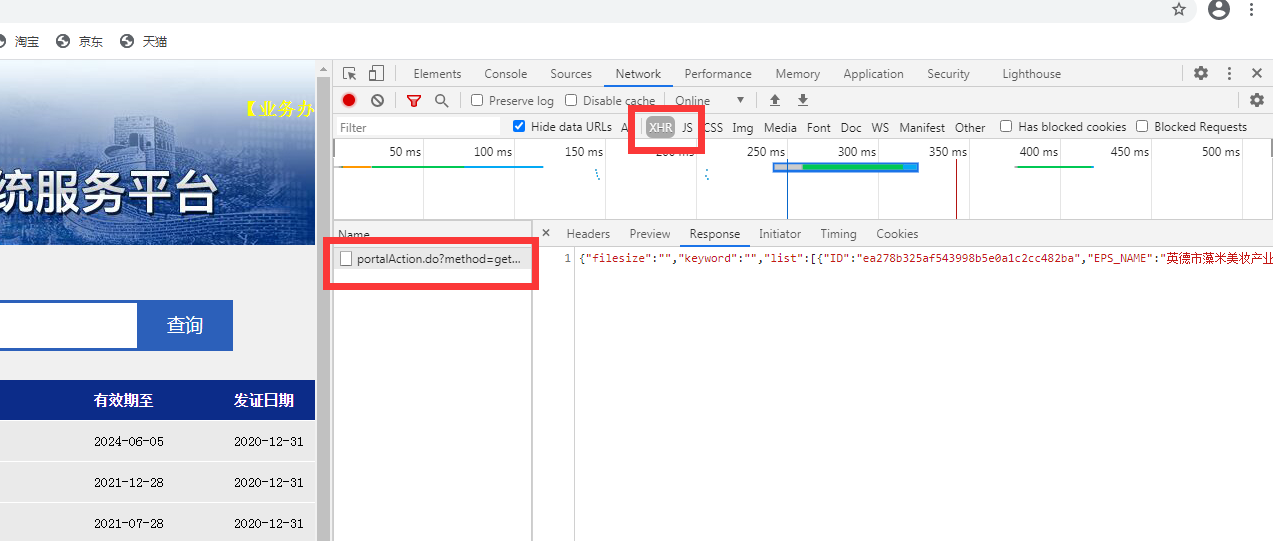
主页的response返回内容中,包含了这一页中的所有企业的id
修改网页参数page可以实现翻页
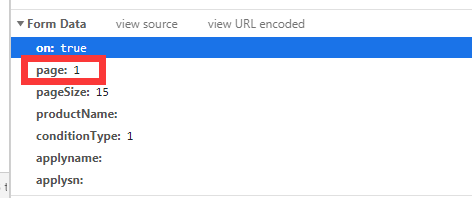
所以首先要通过访问主页,获取所有企业id,放到一个list中。
if __name__ == '__main__': url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36' } data_ids=[] for i in range(0,50): #50页之后数据异常,就爬到50页吧 data = { 'on': 'True', 'page':str(i), 'pageSize':'15', 'productName':'', 'conditionType':'1', 'applyname':'', 'applysn':'' } dict_data = requests.post(url = url ,data = data,headers = headers).json() time.sleep(0.1) for j in dict_data['list']: data_ids.append(j['ID'])
data_ids中就是所有企业的id
下一步是通过numpy创建csv文件,把列索引创建出来。先对data_ids第0个id,也就是第0个企业的详情页进行解析,

把每一项作为列索引
url_creat_csv = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById' creat_csv(url_creat_csv,data_ids[0])
创建csv文件函数定义
def creat_csv(url,list_id_0): df = pd.DataFrame() headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36' } data = { 'id': list_id_0 } dict_data = requests.post(url=url, data=data, headers=headers).json() for i in dict_data.keys(): df[i]='' df.to_csv('1.csv',encoding = 'utf-8_sig')
最后将每一个企业id对应详情页解析,放到csv文件中
pd = pd.read_csv('1.csv',encoding = 'utf-8') url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById' for (j,i) in zip(range(len(data_ids)),data_ids): #对每一个id网页进行访问 data = { 'id':i } data_js = requests.post(url = url ,data = data,headers = headers).json() for k in data_js.keys():#k是遍历data_js中的key pd.loc[j,k] = data_js[k] pd.to_csv('1.csv', encoding='utf-8_sig')
最后爬到的文件是这样的:
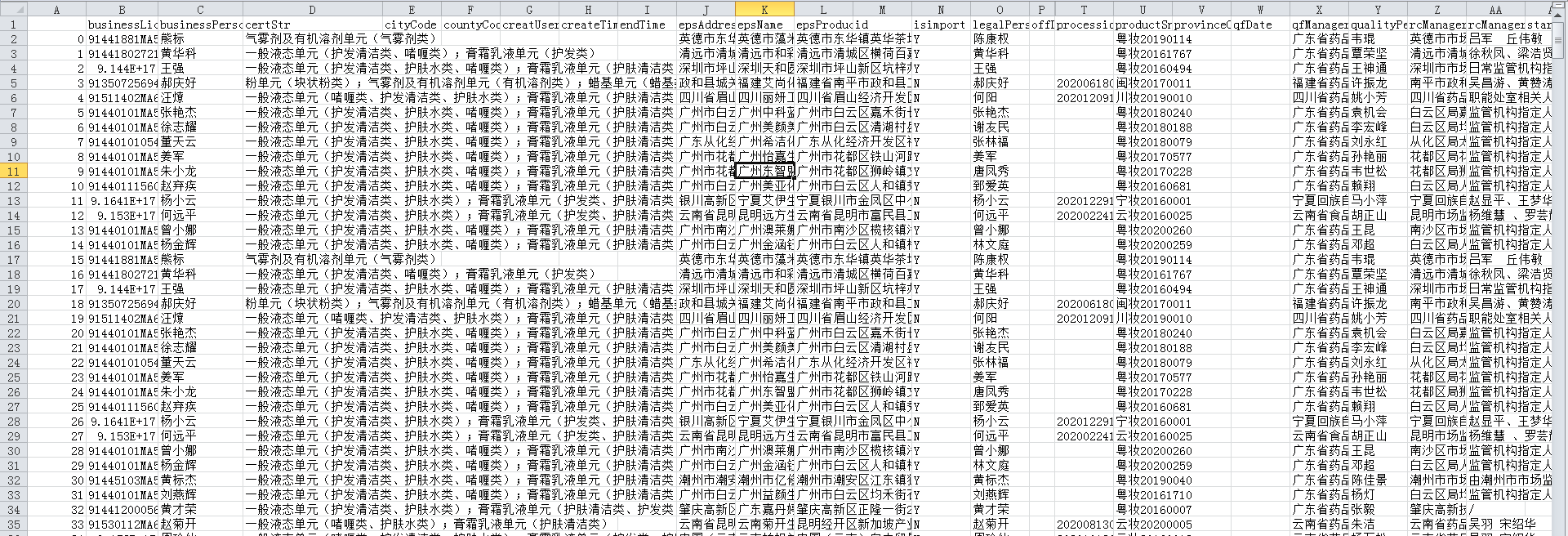
如果觉得列索引是英文的,可以用字典对应替换下,这里就不写了。
个人总结:爬数据不难,难在保存在本地中。利用pandas保存文件花了半天时间。。。囧