当执行 ./bin/hdfs dfs -put ./etc/hadoop/*.xml ../input 打算将xml移动到input文件夹中出错
rogn@ubuntu:~/Downloads$ hdfs dfs -put ./test.txt hdfs:///rogn/input 2020-06-10 17:39:41,266 WARN hdfs.DataStreamer: DataStreamer Exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /rogn/input/test.txt._COPYING_ could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and 0 node(s) are excluded in this operation.
看它的报错信息好像是节点没有启动,但是我的节点都启动起来了,使用jps也能查看到节点信息。
使用hadoop dfsadmin -report命令查看磁盘使用情况,发现出现以下问题:
Configured Capacity: 0 (0 B) Present Capacity: 0 (0 B) DFS Remaining: 0 (0 B) DFS Used: 0 (0 B) DFS Used%: NaN% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 0 (0 total, 0 dead)
节点下存储空间都是空的,问题应该就是出现在这了。
查阅资料发现造成这个问题的原因可能是使用hadoop namenode -format格式化时格式化了多次造成那么spaceID不一致,解决方案:
1、停止集群(切换到/sbin目录下)
$./stop-all.sh
2、删除在hdfs中配置的data目录(即在core-site.xml中配置的hadoop.tmp.dir对应文件件)下面的所有数据;
$ rm -rf /home/hadoop/hdpdata/*
3、重新格式化namenode(切换到hadoop目录下的bin目录下)
$ ./hadoop namenode -format
4、重新启动hadoop集群(切换到hadoop目录下的sbin目录下)
$./start-all.sh
在使用hadoop dfsadmin -report查看使用情况,结果如下图所示:
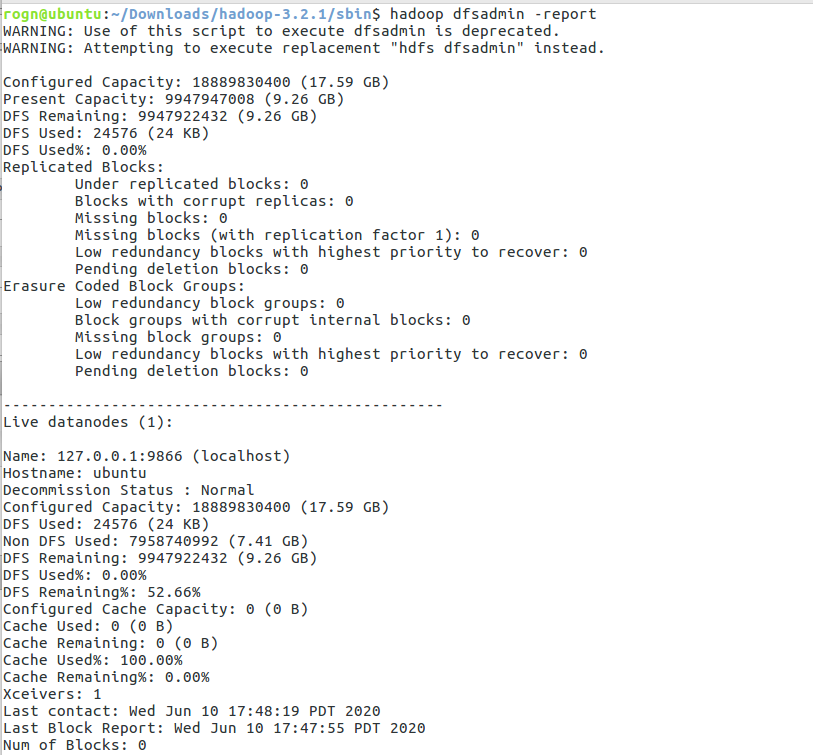
原文链接:https://blog.csdn.net/weiyongle1996/article/details/74094989