一、hadoop安装
1. 修改主机名和 IP 地址映射
sudo vi /etc/hostname #修改主机名(如,删掉原有内容,命名为 hadoop) ping hadoop #ping 通证明成功
2. 安装java
sudo apt install openjdk-8-jdk-headless
配置JAVA环境变量,在当前用户根目录下的.profile文件最下面加入以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使用source命令让立即生效
source .profile
rogn@ubuntu:~$ java -version openjdk version "1.8.0_252" OpenJDK Runtime Environment (build 1.8.0_252-8u252-b09-1~16.04-b09) OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode)
3. 下载hadoop 3.2.1
wget http://mirrors.ustc.edu.cn/apache/hadoop/common/stable/hadoop-3.2.1.tar.gz tar -zxvf hadoop-3.2.1.tar.gz
再次修改 ~/.bashrc,在末尾添加:
export HADOOP_HOME=/home/rogn/Downloads/hadoop-3.2.1 export PATH=$PATH:$HADOOP_HOME/bin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
source ~/.bashrc
4. 配置SSH的无密码登录
安装openssh-server( 通常Linux系统会默认安装openssh的客户端软件openssh-client),所以需要自己安装一下服务端。
sudo apt-get install openssh-server
输入 cd .ssh目录下,如果没有.ssh文件 输入 ssh localhost生成。
cd ~/.ssh/
生成秘钥
ssh-keygen -t rsa
过程中可一直回车
将Master中生成的密钥加入授权(authorized_keys)
cat id_rsa.pub >> authorized_keys # 加入授权 chmod 600 authorized_keys # 修改文件权限,如果不修改文件权限,那么其它用户就能查看该授权
完成后,直接键入“ssh localhost”,能无密码登录即可,

键入“exit”退出,到此SSH无密码登录配置就成功了。
5. 配置完成后,执行 NameNode 的格式化:
$./bin/hdfs namenode -format
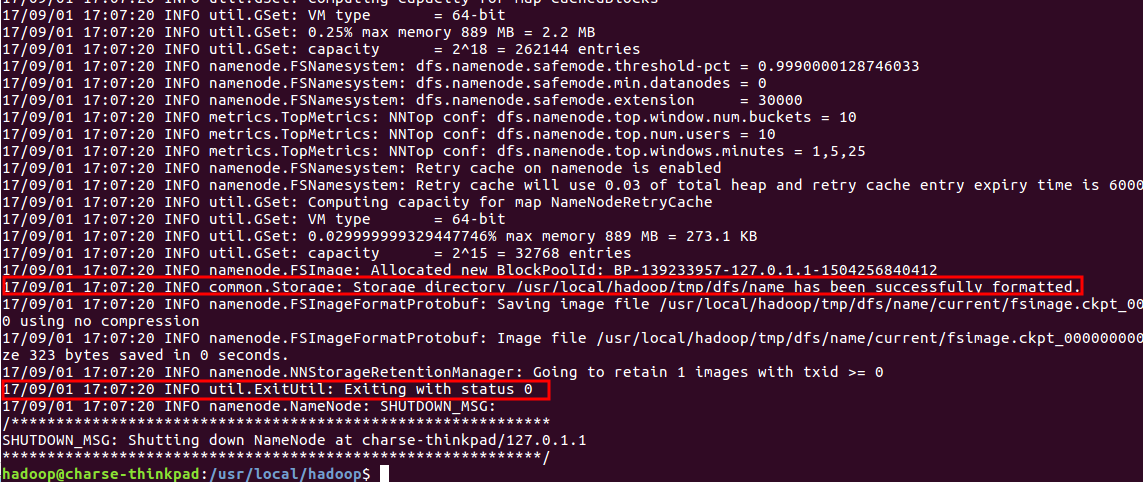
注意:不能进行多次格式化操作
6. 接着开启 NameNode 和 DataNode 守护进程
启动hdfs
sbin/start-dfs.sh
启动YARN集群
sbin/start-yarn.sh
用start-all.sh可以同时启动两者
可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”

访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
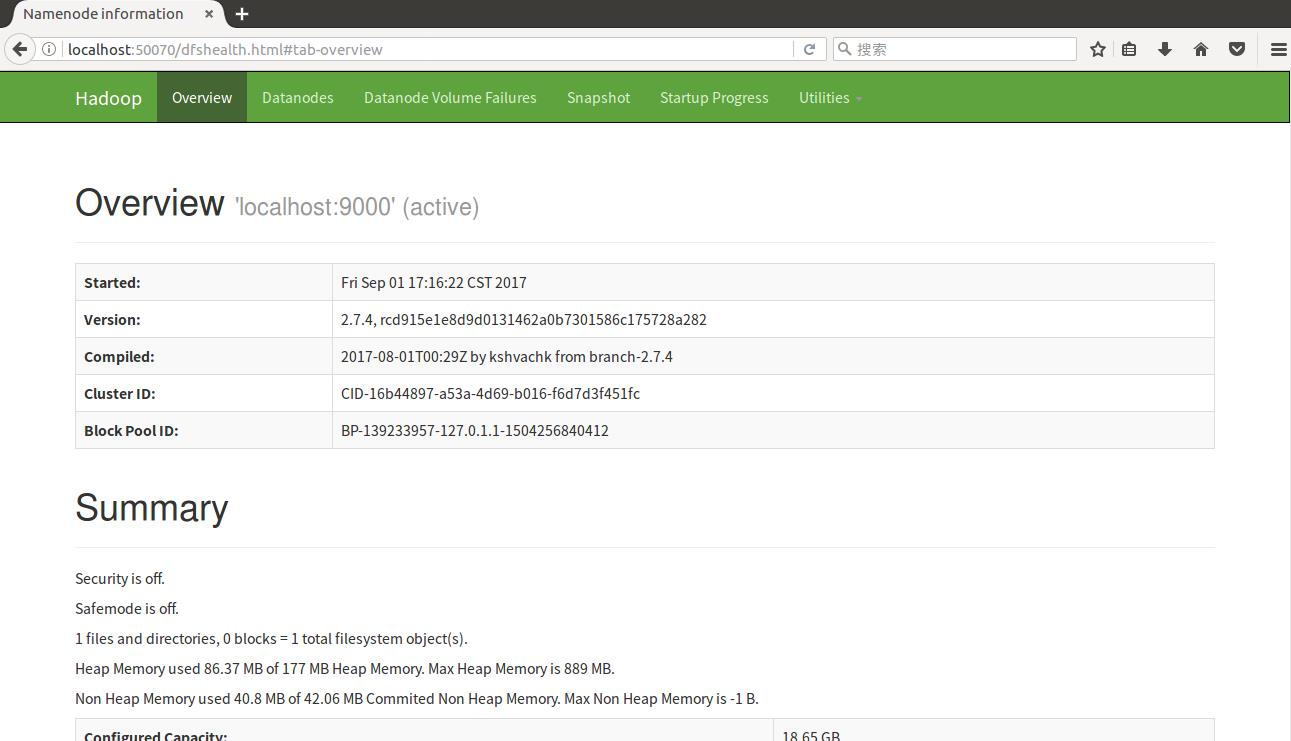
测试hadoop
建立测试文件:
# vim test.txt
然后输入如下数据
hello hadoop hello World Hello Java Hey man i am a programmer
将测试文件放到测试目录中:
# hdfs dfs -mkdir hdfs:///wordlab # hdfs dfs -mkdir hdfs:///wordlab/input # hdfs dfs -put ./test.txt hdfs:///wordlab/input
执行hadoop自带的wordcount程序:
hadoop jar /home/rogn/Downloads/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount hdfs:///wordlab/input hdfs:///wordlab/output
查看词频统计的结果
# hdfs dfs -cat hdfs:///wordlab/output/part-r-00000
删除文件夹:
hdfs dfs -rm -r hdfs:///wordlab/output/
列出文件:
hdfs dfs -ls hdfs:///wordlab