基本操作
import pandas as pd #导入pandas包 data = pd.read_csv("train.csv") #读取csv文件 data = pd.read_csv("train.csv", nrows=15) #读取前n行 data = pd.read_csv("train.csv", usecols=['helpful_votes', 'total_votes']) #读取前n行 //train=pd.read_csv('hair_dryer.tsv', sep=' ') #读取tsv格式 print(data) #打印所有文件 //data.head() //data.tail() print (data.head(5)) #打印前5行 print (data.head(5)) #打印前5行 print(data.columns) #返回全部列名 print(data.shape) #f返回csv文件形状 print(data.loc[2:10]) #打印第2到10行 data.loc[2:4, ['PassengerId', 'Sex']] #打印行中特定列 # 列名 print(df.columns) # 索引 print(df.index)
数据分析
获取指定类的前n位字符串
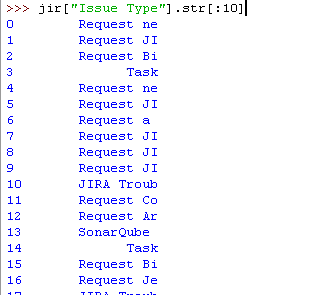
对某列求和,或者分组求和


获取列名与索引:

按照某一列筛选:
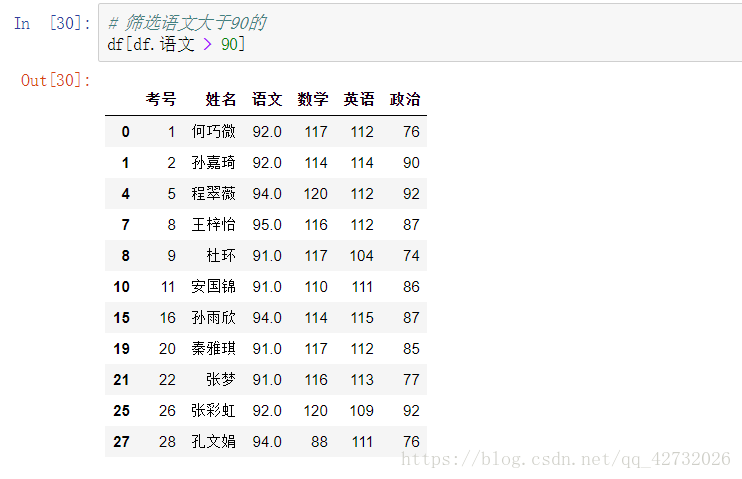
按照某一列或者某几列进行排序:
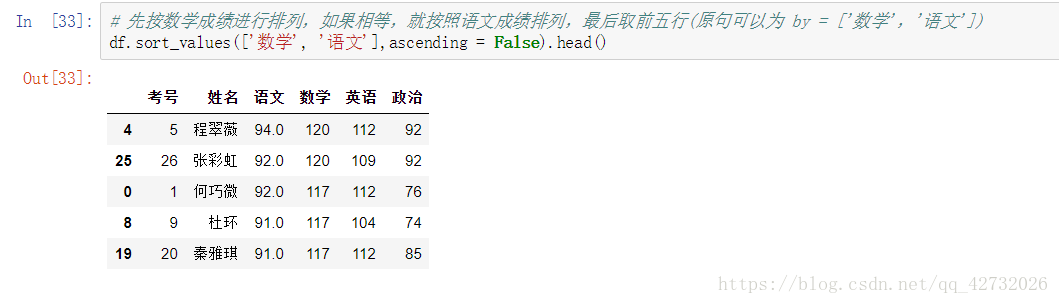
取出某一列的值(返回值为array数列):

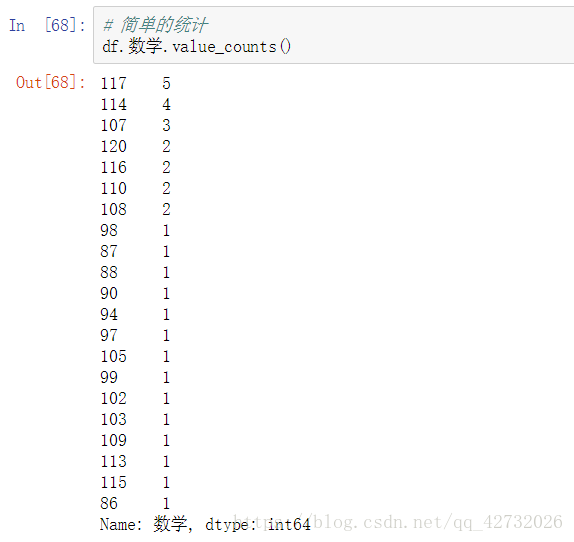
简单的个数统计:
将表格中的某几列拆分出来:

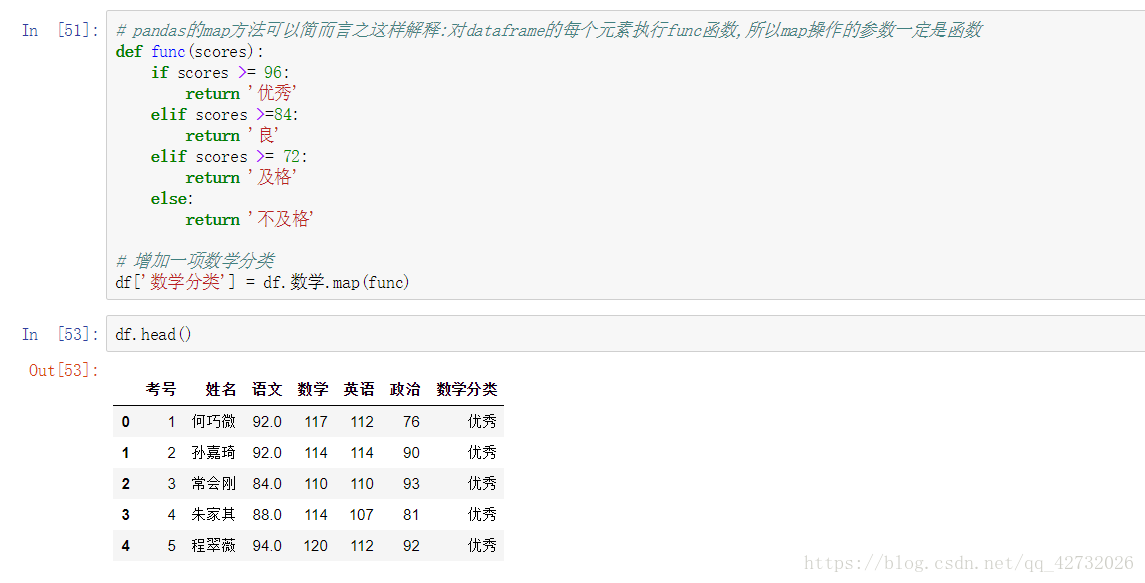
pandas中的map函数:
pandas中的applymap函数:

以上内容来自下面链接,这里只是做个汇总!
1. https://blog.csdn.net/xz1308579340/article/details/81106310