前言:回顾一下前面学习的内容,大概说了下数据结构中的线性结构,从物理存储方面来说又分为顺序存储和链式存储结构,各自有自己的优缺点,顺序存储结构读快写慢,链式存储结构写快读慢。但是这些数据元素之间的关系都为一对一的关系,而我们生活中关系不止是一对一,有可能是一对多,多对多,本篇先介绍一下一对多的存储结构,那么它是怎样存储才能保持它们之间的关系呢?
一、树定义
生活中有很多这样的例子,一个强盛家族的族谱,必然是呈金字塔形状的,从一到多。就和树一样,一颗树通常由根部长出一个树干,然后从树干长出一些树枝,然后从树枝上又长出更小的树枝,而叶子则长在最细的树枝上。树这种数据结构正式像一颗倒过来的树木。
所以对树的定义,即树是一种管理有像树干、树枝、树叶一样关系的数据的数据结构。
树由节点(顶点)和边(枝)构成,并且有一个节点作为起始点。这个起始点称为树的根节点。从根节点上可以连出几条边,每条边都和一个节点相连。延伸出来的这些节点又可以继续通过边延伸出新的结点。这个过程中,旧的节点称作父结点,而延伸出来的新节点称作子结点。一个子节点都没有的节点就叫做叶子结点。另外,由根节点出发,到达某一个节点所要经过的边的个数叫做这个节点的深度,节点拥有的子树数称为该节点的度,树的度为各节点度的最大值。
下图中,标着7、9和0三个数字的节点里,7就是父节点,9和0就是子节点。另一个图里,标记6的这个节点就是“根节点”,标记3、5、11、8、10、9、2、17、14的这些节点就是“叶子节点”,而图中12这个的深度是2。 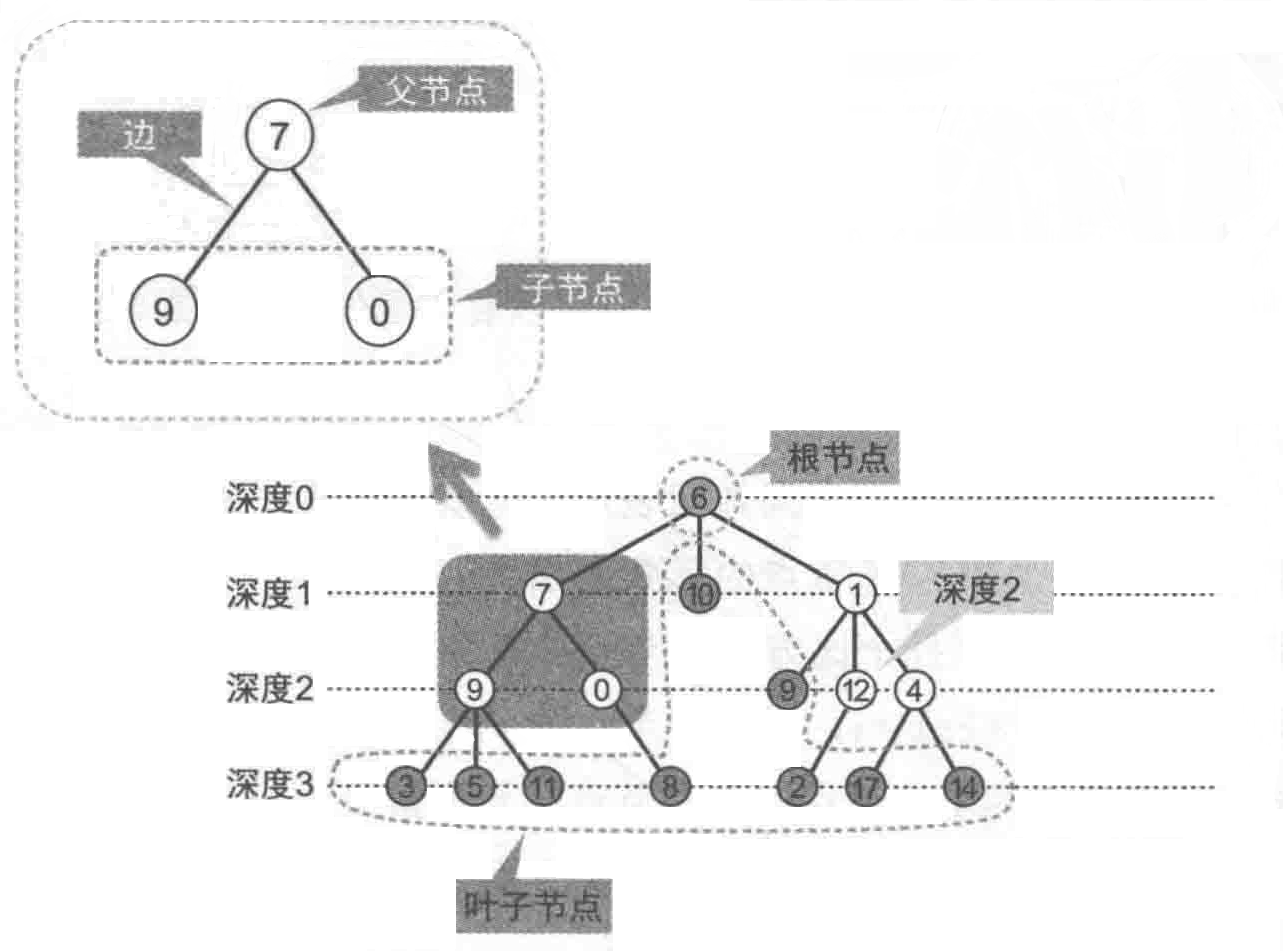

树(Tree)是n(n>=0)个节点的有限集。当n=0时称为空树,在任意一颗非空树中:
- 有且仅有一个特定的称为根(Root)的节点;
- 当n>1时,其余节点可分为m(m>0)个互不相交的有限集T1、T2、、、Tm,其中每一个集合本身由是一棵树,并且称为根的子树(SubTree)。
节点的子树的根称为节点的孩子(Child),相应的该节点称为孩子的双亲(Parent),同一双亲的孩子之间互称为兄弟(Sibling);节点的祖先是从根到该节点所经分支上的所有结点。
总结一下树的相关概念:
节点的度:一个节点含有的子树的个数称为该节点的度;
叶节点或终端节点:度为0的节点称为叶节点;
非终端节点或分支节点:度不为0的节点;
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
树的度:一棵树中,最大的节点的度称为树的度;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次;
堂兄弟节点:双亲在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>=0)棵互不相交的树的集合称为森林;
二、树的存储结构
上面已经对树的定义和概念做了个基本的认识,那么我们最关心的还是怎么在程序中实现该结构。
在计算机中数据的存储有两种结构顺序存储和链式存储,顺序存储结构显然是不行的,而链式存储结构也是有缺点的,我们来看一下:
第一种:
由于链式存储结构中的节点需含有子结点的引用或指针,但在树中子节点的不确定性导致无法无法固定具体节点中有几个引用或指针;
Node节点结构示意图:
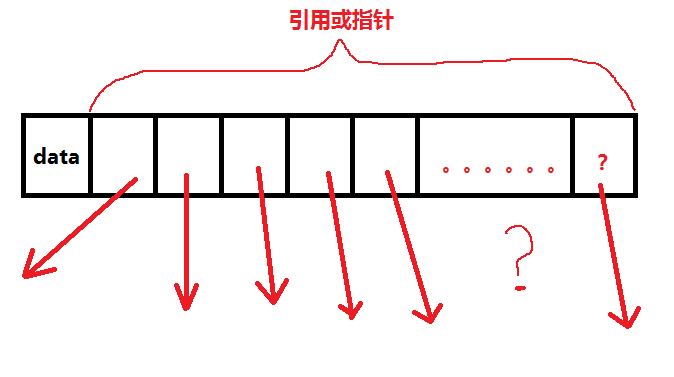

我们可以根据树的度来确定Node节点的结构,比如树的度为3,那么Node结构中就由3个对自己引用。
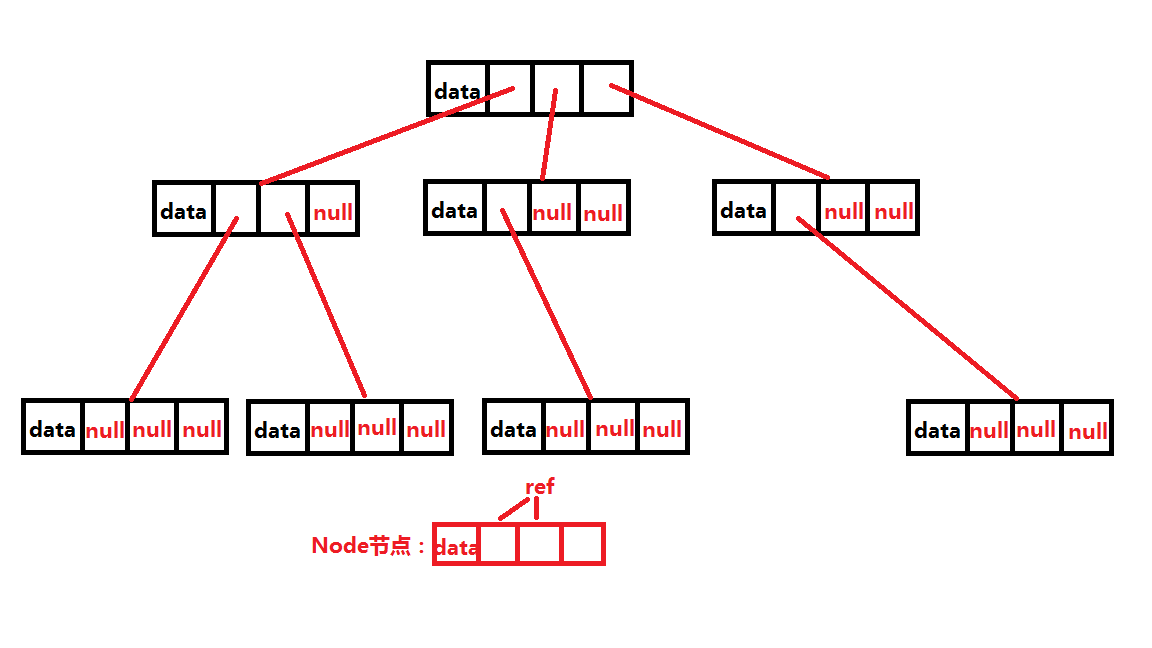

这样的话就会浪费很多空间,所以这样的结构不是最理想的存储结构;
第一种(改):
对于上面的存储结构会过多的浪费存储空间,那么我们在结点中声明一个动态链表Nodes来存放可能的子节点Node;
修改完后的结构如图:

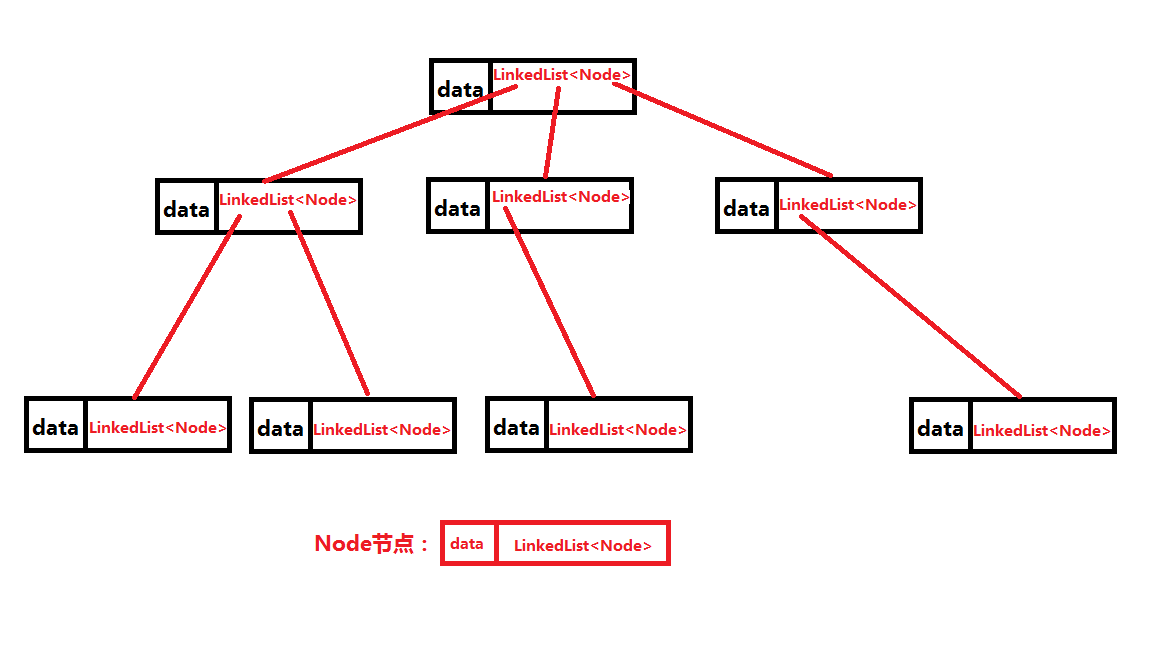
第二种:
使用数组+链表结合的方式来表示树:
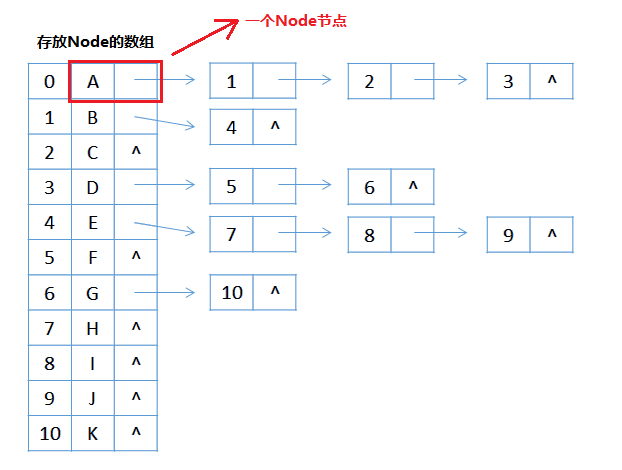

在第一版(改)中可以看到Node使用了集合,那么为什么不直接使用数组+链表的方式来构建呢,所以构建出来后就是上面图的样子(0的位置为ROOT根节点,从根节点出发,查看每个分支,构成树)。
根据上面的存储方式,就可以完成对树的实现了;
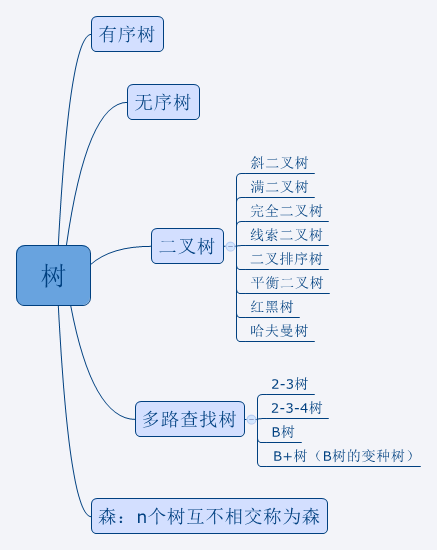
三、树的分类
树的种类分很多,根据是子节点之间否有序可分为有序树和无序树;
根据子节点数量分为二叉树和多路查找树;
而其中二叉树又分为斜二叉树、满二叉树、完全二叉树、线索二叉树、二叉排序树、平衡二叉树、红黑树、哈夫曼树等。多路查找树分为2-3树、2-3-4树、B树、B树变种树B+树等。
有句话是这样说的,一木成树,两木成林,三木成森,所以有树就有森林,即n棵互不相交的树称为森。

本系列参考书籍:
《写给大家看的算法书》
《图灵程序设计丛书 算法 第4版》