前言:许多基础数据类型都和对象的集合有关。具体来说,数据类型的值就是一组对象的集合,所有操作都是关于添加、删除或是访问集合中的对象。而且有很多高级数据结构都是以这样的结构为基石创造出来的,在本文中,我们将了解学习三种这样的数据类型,分别是背包(Bag)、栈(Stack)和队列(Queue)
一、学习感悟
对于数据结构的学习可以用以下步骤来学习:
- 首先先对该结构的场景操作进行API化;
- 然后再对数据类型的值的所有可能的表示方法以及各种操作的实现;
- 总结特点和比较;
接下来就对这三种数据类型进行介绍。
二、API
这三种数据类型都是依赖于之前介绍过的线性表的链式存储结构的,所以理解并掌握链式结构是学习各种算法和数据结构的第一步,若还不是很清楚,可以看一下前面关于线性表的链式存储结构的文章(本文主要是对链式存储结构的进行介绍,如想要对顺序存储结构了解的话,可根据其特性和API进行编写代码,欢迎在评论区留言讨论)。
2.1、背包(Bag)
背包是一种不支持从中删除元素的集合数据类型——它的目的就是帮助用例收集元素并迭代遍历所有收集到的元素(用例也可以检查背包是否为空或者获取背包中元素的数量)。
要理解背包的概念,可以想象一个喜欢收集弹珠球的人。他将所有的弹珠球都放在一个背包里,一次一个,并且会不时在所有的弹珠球中寻找某一颗;
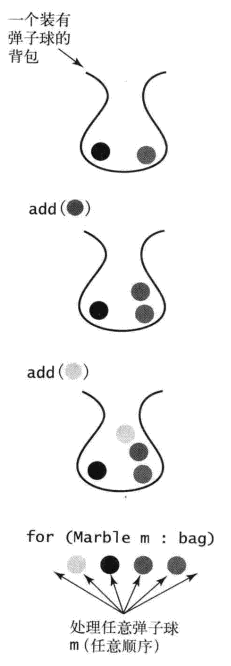

2.1.1 背包API
根据以上的需求,可以写出背包的API:
public class Bag<Item> implements Iterable<Item> Bag() 创建一个空背包 void add(Item item) 添加一个元素 boolean isEmpty() 背包是否为空 int size() 背包中的元素数量
使用Bag的API,用例可以将元素添加进背包并根据需要随时使用foreach语句访问所有的元素。用例也可以使用栈或是队列,但是用Bag可以说明元素的处理顺序不重要,比如在计算一堆Double值的平均值时,无需关注背包元素相加的顺序,只需要在得到所有值的和后除以Bag中元素的数量即可。
2.1.2 背包实现
根据2.1.1的API写出具体的实现,其中关键方法add使用了头插法:


public class Bag<T> implements Iterable<T> { private Node<T> first; private Integer size; Bag() { first = new Node<>(); first.next = null; size = 0; } //由于Bag类型不需要考虑元素的相对顺序,所以这里我们可以使用头插法来进行插入,提高效率 public void add(T t) { Node<T> newNode = new Node<>(); newNode.t = t; newNode.next = first.next; first.next = newNode; size++; } public Boolean isEmpty() { return size < 1; } public Integer size() { return size; } class Node<T> { T t; Node<T> next; } @Override public Iterator<T> iterator() { return new ListIterator(); } class ListIterator implements Iterator<T> { private Node<T> current = first.next; @Override public boolean hasNext() { return current!=null; } @Override public T next() { T t = current.t; current = current.next; return t; } } public static void main(String[] args) { Bag<Integer> bag = new Bag<>(); for (int i = 1; i <= 100; i++) { bag.add(i); } double sum = 0; Iterator<Integer> iterator = bag.iterator(); while (iterator.hasNext()) { sum = sum + iterator.next(); } System.out.println("和:"+sum); double size = bag.size(); String format = new DecimalFormat("0.00").format(sum / size); System.out.println("平均值:"+format); } }
核心代码为add(),使用了头插法::
//由于Bag类型不需要考虑元素的相对顺序,所以这里我们可以使用头插法来进行插入,提高效率 public void add(T t) { Node<T> newNode = new Node<>(); newNode.t = t; newNode.next = first.next; first.next = newNode; size++; }
2.1.3 总结
上面就是关于Bag数据类型的实现,从中可以看出Bag是一种不支持删除元素的、无序的、专注于取和存的集合类型。
2.2、栈(Stack)
下压栈(或简称栈)是一种基于后进先出(LIFO)策略的集合类型。比如在桌子上对方一叠书,我们拿书时,一般都是从最上面开始取的,这样的操作就类似栈。
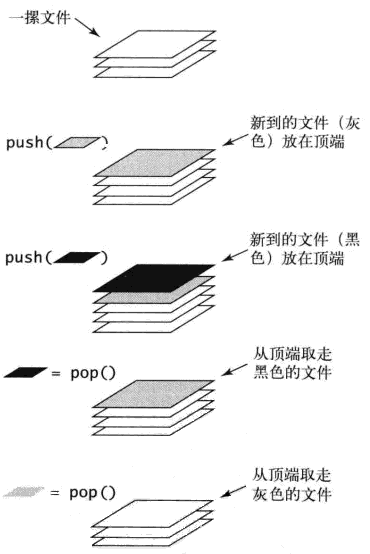

栈管理数据的两种操作如下:
- 写入数据(堆积)操作称作入栈(PUSH);
- 读取数据操作称作出栈(POP);
栈类型的模型结构在生活中的应用也不少,比如浏览器的回退功能,在一个浏览器tag页上打开的网页,通过回退功能可以一次回退到历史最近的浏览记录。还有电脑软件撤销功能,也是这样的策略模型。
栈是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一段被称为栈顶,相对的,把另一端称为栈底。想一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之称为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
另外,像栈这样,最后写入的数据被最先读取的数据管理方式被称作LIFO(last in,first out),或者FILO(first in,last out)。
2.2.1 栈API
根据对以上理解写出背包的API:
public class Stack<Item> implements Iterable<Item> Stack() 创建一个空栈 void push(Item item) 添加一个元素 Item pop() 删除最近添加的元素 boolean isEmpty() 栈是否为空 int size() 栈中的元素数量
2.2.2 栈实现
根据上面的栈API实现其方法,还是使用头插法来实现:
public class Stack<T> implements Iterable<T> { private Node<T> head; private Integer size; Stack() { head = new Node<>(); head.next = null; size = 0; } //头插法 public void push(T t) { Node<T> first = head.next; head.next = new Node<>(); head.next.t = t; head.next.next = first; size++; } //取的时候从最上面开始取,也就是最近插入的元素 public T pop() { Node<T> first = head.next; head.next = first.next; size--; return first.t; } public Boolean isEmpty() { return size < 1; } public Integer size() { return size; } class Node<T> { T t; Node<T> next; } @Override public Iterator<T> iterator() { return new ListIterator<T>(); } class ListIterator<T> implements Iterator<T> { private Node<T> current = (Node<T>) head.next; @Override public boolean hasNext() { return current!=null; } @Override public T next() { T t = current.t; current = current.next; return t; } } public static void main(String[] args) { Stack<Integer> stack = new Stack<>(); for (int i = 0; i < 10; i++) { stack.push(i); System.out.println("push --> "+i); } Iterator<Integer> iterator = stack.iterator(); while (iterator.hasNext()) { System.out.println("pop --> "+iterator.next()); } } }
核心方法为push()和pop():
//头插法 public void push(T t) { Node<T> first = head.next; head.next = new Node<>(); head.next.t = t; head.next.next = first; size++; } //取的时候从最上面开始取,也就是最近插入的元素 public T pop() { Node<T> first = head.next; head.next = first.next; size--; return first.t; }
运行结果:
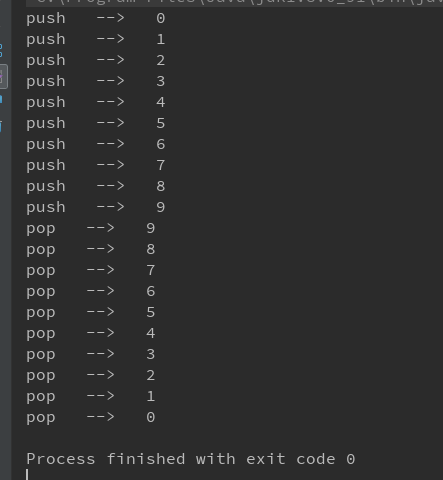

2.2.3 总结
它可以处理任意类型的数据,所需的空间总是和集合的大小成正比,操作所需的时间总是和集合的大小无关。
- 先进后出;
- 具有记忆功能,栈的特点是先进栈的后出栈,后进栈的先出栈,所以你对一个栈进行出栈操作,出来的元素肯定是你最后存入栈中的元素,所以栈有记忆功能;
- 对栈的插入与删除操作中,不需要改变栈底指针;
- 栈可以使用顺序存储也可以使用链式存储,栈也是线性表,因此线性表的存储结构对栈也适用线性表可以链式存储;
2.3、队列(Queue)
先进先出队列(或简称队列)是一种基于先进先出(FIFO)策略的集合类型。在生活中这种模型结构的示例有很多,比如说排队上公交、排队买火车票、排队过安检等都是先进先出的策略模型。
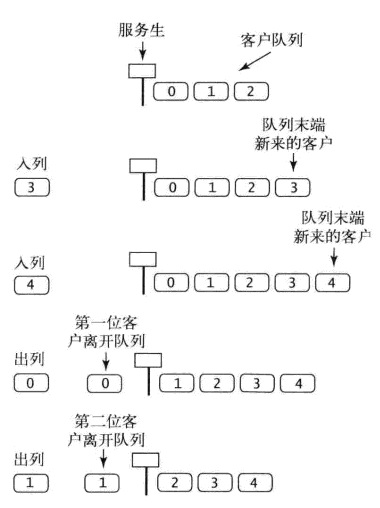

队列是一种特殊的线性表,特殊之处在于它只允许在表的前端进行删除操作,而在表的后端进行插入操作,和栈一样,队列是一种操作受限制的线性表,进行插入操作的端称为队尾,进行删除操作的端称为队头。
像排队一样,一定是从最先的数据开始序按顺处理数据的数据结构,就成为“队列”,而像这类模型策略,被称为FIFO(first in,first out)或者LILO(last in,last out)。
队列在通信时的电文发送和接收中得到了应用。把接收到的电文一个一个放到了队列中,在时间宽裕的时候再取出和处理。
当用例使用foreach语句迭代访问队列中的元素时,元素的处理顺序就是他们被添加到队列中的顺序,而在程序中使用它的原因是在用集合保存元素的同时保存它们的相对顺序:使它们入列顺序和出列顺序相同。
2.3.1 队列API
综上所述,队列的API为:
public class Queue<Item> implements Iterable<Item> Queue() 创建一个空队列 void enqueue(Item item) 添加一个元素 Item dequeue() 删除最近添加的元素 boolean isEmpty() 队列是否为空 int size() 队列中的元素数量
2.3.2 队列实现
根据2.3.1的API编写队列的实现:
public class Queue<T> implements Iterable<T> { private Node<T> head; private Node<T> tail; private Integer size; Queue() { head = new Node<>(); tail = null; head.next = tail; tail = head; size = 0; } //从队列的尾部插入数据 public void enqueue(T t) { Node<T> oldNode = tail; tail = new Node<>(); tail.t = t; tail.next = null; if (isEmpty()) head.next = tail; else oldNode.next = tail; size++; } //从队列的头部取数据 public T dequeue() { Node<T> first = head.next; head.next = first.next; return first.t; } public Boolean isEmpty() { return size < 1; } public Integer size() { return size; } class Node<T> { T t; Node<T> next; } @Override public Iterator<T> iterator() { return new ListIterator(); } class ListIterator implements Iterator<T> { private Node<T> current = head.next; @Override public boolean hasNext() { return current!=null; } @Override public T next() { T t = current.t; current = current.next; return t; } } public static void main(String[] args) { Queue<Integer> queue = new Queue<>(); for (int i = 0; i < 10; i++) { queue.enqueue(i); System.out.println("enqueue --> "+i); } Iterator<Integer> iterator = queue.iterator(); while (iterator.hasNext()) { System.out.println("dequeue --> "+iterator.next()); } } }
核心方法为enqueue()和dequeue():
//从队列的尾部插入数据 public void enqueue(T t) { Node<T> oldNode = tail; tail = new Node<>(); tail.t = t; tail.next = null; if (isEmpty()) head.next = tail; else oldNode.next = tail; size++; } //从队列的头部取数据 public T dequeue() { Node<T> first = head.next; head.next = first.next; return first.t; }
运行结果:


2.3.3 总结
队列做的事情有很多,包括我们常用的一些MQ工具,也是有队列的影子。
- 先进先出;
- 特殊的线性结构;
- 关注于元素的顺序,公平性;
三、背包、栈和队列的比较
背包:不关注元素的顺序,不支持删除操作的集合类型;
栈:先进后出,具有记忆性,多应用于需要记忆功能的业务;
队列:先进先出,可以应用于缓冲;
本系列参考书籍:
《写给大家看的算法书》
《图灵程序设计丛书 算法 第4版》