chineking / WeiboCrawler / wiki / Home — Bitbucket
Home
WeiboCrawler
WeiboCrawler是一个分布式爬虫程序,主要用来抓取新浪微博(weibo.cn)数据。
为什么不用新浪微博API
首先,新浪微博确实有API可以拿到一个用户数据,但是,一个应用的调用次数也是有限的;另外新浪微博Oauth2.0有过期时间,过段时间(测试的应用只有一天)就去授权会比较麻烦,我希望爬虫是在不需要人为干预的情况下持续的。
安装要求
在分布式情况下运行,抓取到的用户数据是存储在MongoDB中的,所以,首先需要MongoDB的安装,由于爬虫是Python写的,所以需要pymongo(单机模式下使用文件存储则不需要)。如果安装了setuptools,则可以:
easy_install pymongo另外,解析网页用到了pyquery,由于pyquery依赖于lxml,而lxml的安装可能会出现问题。Windows用户可以到这里下载二进制安装包。
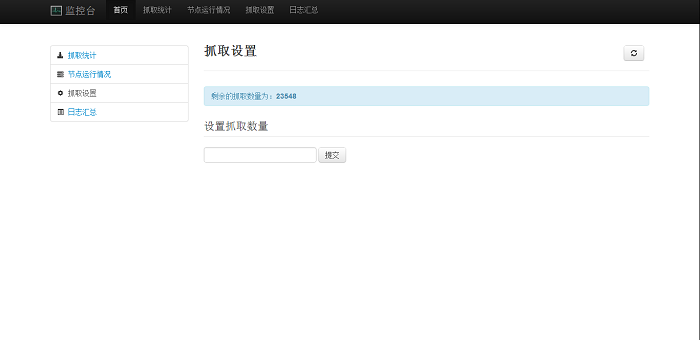
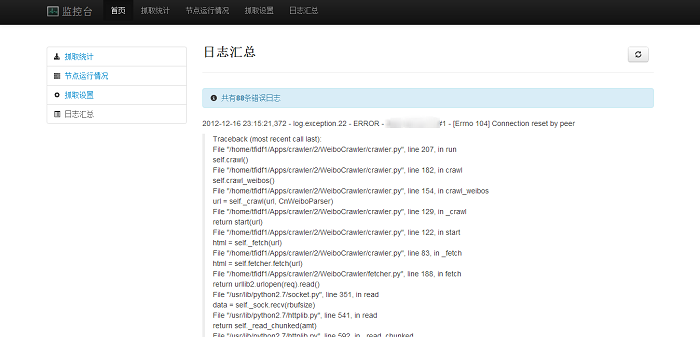
easy_install pyqueryMonitor有一个web界面(见截图),运行需要安装tornado。
easy_install tornado架构
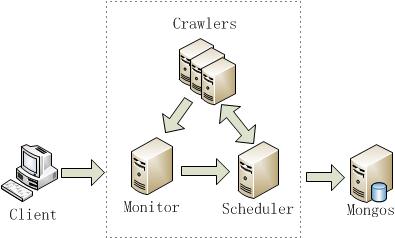
整个爬虫程序分为三个部分。
- Scheduler:一个简单的调度器,主要作用分配UID给每个worker,并响应Monitor命令。
- Monitor:监控程序,收集各个worker程序的心跳,并有一个web接口。用户可以在Monitor进行设置。
- Crawler:爬虫worker程序,每个worker从Scheduler拿到UID,就去抓取这个微博用户数据。
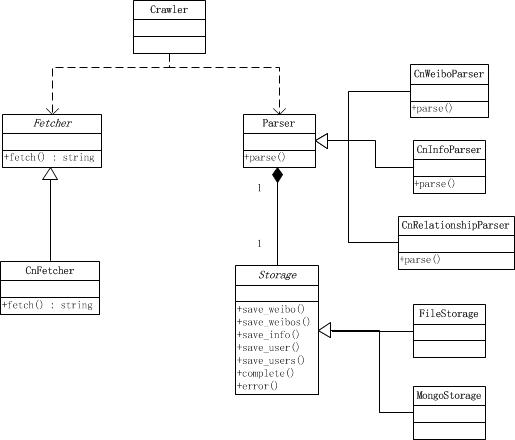
对于一个Crawler,其类图如下:
一个crawler用一个fetcher来抓取新浪微博的网页,然后把得到的网页交给一个特定的parser(CnWeiboParser用来解析用户微博页面,CnInfoParser用来解析用户个人信息页面,CnRelationshipParser解析用户的fav和fans页面),parser将解析的数据交给一个Storage去存储。Storage目前实现了FileStorage和MongoStorage,分别将数据存储在文件和MongoDB中。
部署和运行
单机模式
此时不需要Monitor和Scheduler,只要运行WeiboCrawler目下下的__init__.py文件。支持以下选项:
- -m(--mode):模式,支持的值为dc和sg,这里默认为分布式(dc)。在单机模式下运行必须要设置为sg。
- -t(--type):存储类型,可以为file和mongo,默认为mongo,只有在单机模式下设置才有效。
- -l(--loc):设置为file的存储类型时,文件夹所在的绝对路径。单机模式下设置有效。
- uids:要抓取的一系列用户uid,用空格隔开。单机模式下设置有效。
示例:
python __init__.py -m sg -t file -l /my/path/weibo uid1 uid2其中,uid1和uid2分别为微博用户的UID。
注:如果运行出现ImportError:
Traceback (most recent call last): File "__init__.py", line 11, in <module> from WeiboCrawler.crawler import UserCrawler ImportError: No module named WeiboCrawler.crawler是因为WeiboCrawler不在sys.path中。解决方法:
在site-packages中添加pth文件。site-packages因系统而异,如果是windows,假设python装在C:\python27,那么就是C:\python27\Lib\site-packages;如果是linux,那么应该是/usr/local/lib/pythonX.X/dist-packages。
假设根目录是在/my/path/weibocrawler,下面有intro.py、WeiboCrawler文件夹等等,那么就在site-packages下新建一个WeiboCrawler.pth文件,里面写上路径:/my/path/weibocrawler。
分布式模式
Monitor和Scheduler要记住只能启动一个。Monitor需要在Scheduler启动之后才能启动。Crawler可以起任意多个。
无论是Monitor、Scheduler还是WeiboCrawler,如果要进行配置,都需要在这三个目录下建立local_settings.py,来覆盖默认的settings.py的设置。接下来说明默认情况下,它们的配置:
Scheduler
- data_port:Crawler通信时所用的端口,默认为1123。
- control_port:Monitor发送命令所用端口,默认为1124。
- start_uids:初始抓取的用户uid,默认为空列表[]。
- fetch_size:目标抓取用户的数量,默认为500。
- mongo_host:MongoDB所在机器的IP地址,下同。
- mongo_port:MongoDB所在机器的端口,下同。
启动Scheduler运行
python intro.py schMonitor
- scheduler_host:Scheduler的IP地址,默认为本机,下同
- scheduler_control_port:Scheduler所在机器的控制端口,默认为1124,下同。
- mongo_host
- mongo_port
启动Monitor运行:
python intro.py mntCrawler
- account:这个Crawler所使用的weibo帐号。
- pwd:这个Crawler所使用的weibo密码。
- instance_index:如果想在一台机器上起多个Crawler,需要Crawler所在的文件夹放在机器的不同地方。同时,这里的instance_index代表着这台机器的实例序号。默认为0。
- mongo_host
- mongo_port
- scheduler_host
- scheduler_port
- monitor_enable:是否和Monitor通信,默认为False,在分布式情况下需设置为True。
- monitor_host:Monitor所在的IP地址。
- monitor_port:Monitor使用的端口,默认为8888。
运行Crawler可以:
python intro.py crw如果一台机器上有多个crawler的实例,请参考instance_index设置的相关说明。
缺陷
目前由于该爬虫来自于实验的要求,所以一些数据并没有获取,包括:
- 所有的用户只获取了该用户的自身的微博内容,所以没有获取该用户转发的内容。
- 初始用户获取了粉丝列表,没有获取其follow的用户。
- 非初始用户没有获取其粉丝和follow用户。
所以如果想获取这些数据,只需修改Storage具体的部分即可。
另外,在分布式模式下,一旦crawler开始运行,除非杀掉进程或者所有的用户已抓取完毕,无法做到停止。
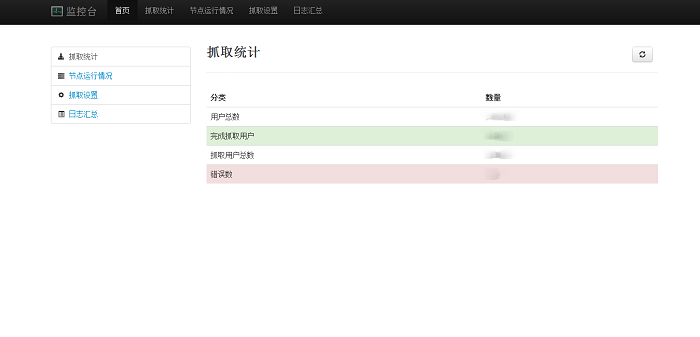
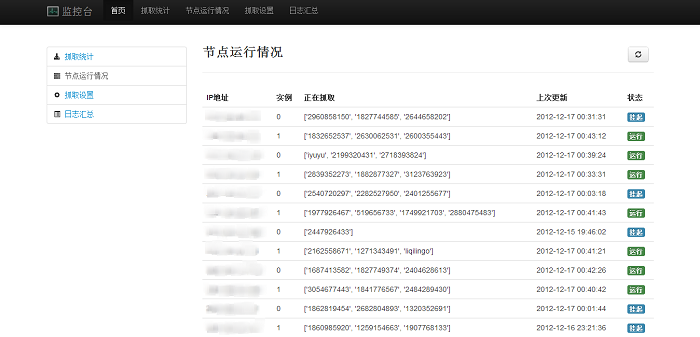
截图(Monitor)
获取源码
hg clone https://bitbucket.org/chineking/weibocrawler