一、ReplicationController/ReplicaSet
在Kubernetes集群中,ReplicationController能够确保在任意时刻,指定数量的Pod副本正在运行。如果Pod副本的数量过多,则ReplicationController会Kill掉部分使其数量与预期保持一致,如果Pod数量过少,则会自动创建新的Pod副本以与预期数量相同。下面是一个ReplicationController的配置示例,如下所示:

ReplicaSet是ReplicationController的下一代实现,它们之间没有本质的区别,除了ReplicaSet支持在selector中通过集合的方式进行配置。在新版本的Kubernetes中支持并建议使用ReplicaSet,而且我们应该尽量使用Deployment来管理一个ReplicaSet。下面定义一个ReplicaSet,对应的配置示例如下所示:

二、Volume
默认情况下容器的数据都是非持久化的,在容器销毁以后数据也会丢失,所以Docker提供了Volume机制来实现数据的持久化存储。同样,Kubernetes提供了更强大的Volume机制和丰富的插件,实现了容器数据的持久化,以及在容器之间共享数据。
Kubernetes Volume具有显式的生命周期,它与Pod的生命周期是相同的,所以只要Pod还处于运行状态,则该Pod内部的所有容器都能够访问该Volume,即使该Pod中的某个容器失败,数据也不会丢失。
Kubernetes支持多种类型的Volume,如下所示:
- emptyDir
- hostPath
- gcePersistentDisk
- awsElasticBlockStore
- nfs
- iscsi
- fc (fibre channel)
- flocker
- glusterfs
- rbd
- cephfs
- gitRepo
- secret
- persistentVolumeClaim
- downwardAPI
- projected
- azureFileVolume
- azureDisk
- vsphereVolume
- Quobyte
- PortworxVolume
- ScaleIO
- StorageOS
- local
上面各种类型的说明和示例,可以参考官方文档。Volume是与Pod有关的,所以这里我们给出一个Pod定义的配置示例,使用了hostPath类型的Volume,如下所示:
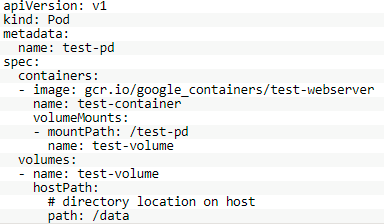
上面定义中,指定了Pod中容器使用的Node节点上的data存储路径。
三、Deployment
Deployment提供了声明式的方法,对Pod和ReplicaSet进行更新,我们只需要在Deployment对象中设置好预期的状态,然后Deployment就能够控制将实际的状态保持与预期状态一致。使用Deployment的典型场景,有如下几个:
- 创建ReplicaSet,进而通过ReplicaSet启动Pod,Deployment会检查启动状态是否成功
- 滚动升级或回滚应用
- 应用扩容或缩容
- 暂停(比如修改Pod模板)及恢复Deployment的运行
- 根据Deployment的运行状态,可以判断对应的应用是否hang住
- 清除掉不再使用的ReplicaSet
定义一个Deployment,示例如下所示:
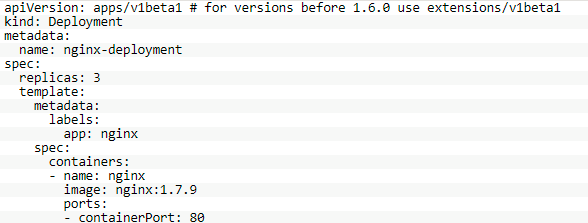
上述配置创建一个ReplicaSet,进而启动3个Nginx Pod。
四、DaemonSet
DaemonSet能够保证Kubernetes集群中某些Node,或者全部Node上都运行一个Pod副本,当集群中某个Node被移除时,该Node上的Pod副本也会被清理掉。删除一个DaemonSet,也会把对应的Pod都删除掉。
通常,DaemonSet会被用于如下场景(在Kubernetes集群中每个Node上):
- 运行一个存储Daemon,如glusterd、ceph等
- 运行一个日志收集Daemon,如fluentd、logstash等
- 运行一个监控Daemon,如collectd、gmond等
定义一个DaemonSet,示例如下所示:
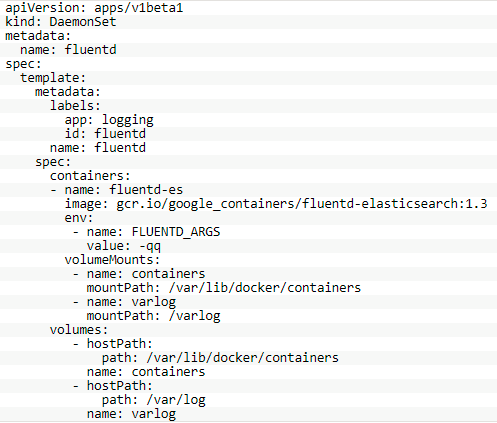
上面例子,创建了一个基于fluentd的日志收集DaemonSet。
五、StatefulSet
StatefulSet是Kubernetes v1.5版本新增的,在v1.5之前的版本叫做PetSet(使用v1.4版本可以使用,具体可以查看官方文档,这里不再累述),是为了解决有状态服务的问题(对应无状态服务的Kubernetes对象:Deployment和ReplicaSet),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行,基于init containers来实现
- 有序缩容,有序删除
为了说明StatefulSet,我们先定义一个名称为nginx的Headless Service,如下所示:
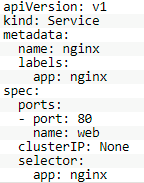
再定义一个名称为web的StatefulSet,定义了要在3个独立的Pod中分别创建3个nginx容器,示例如下所示:
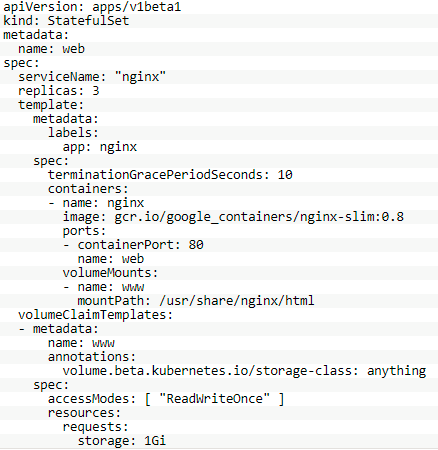
上面示例,在Service中引用了名称为web的StatefulSet,该Service对应的存储信息是有状态的,通过StatefulSet能够保证Service中的Pod失败也不会丢失存储的数据,它通过PersistentVolume来提供稳定存储的。
六、ConfigMap
应用程序会从配置文件、命令行参数或环境变量中读取配置信息,如果将这些配置信息直接写在Docker镜像中,会非常不灵活,每次修改配置信息都要重新创建一个Docker镜像。ConfigMap的出现,能够使配置信息与Docker镜像解耦,更加方便和灵活。
在定义一个Pod的时候,可以使用ConfigMap对象中的配置数据,有很多种方式,如下所示:
- 从一个ConfigMap中读取键值对配置数据
- 从多个ConfigMap中读取键值对配置数据
- 从一个ConfigMap中读取全部的键值对配置数据
- 将一个ConfigMap中的配置数据加入到一个Volume中
下面给出其中2种使用方式:
- 定义一个环境变量,该变量值映射到一个ConfigMap对象中的配置值
创建一个名称为special-config的ConfigMap对象,执行如下命令:
kubectl create configmap special-config --from-literal=special.how=very
在上述ConfigMap对象special-config中创建了一个键special.how,它对应的值为very。
然后,我们定义一个Pod,将ConfigMap中的键special.how对应的值,赋值给环境变量SPECIAL_LEVEL_KEY,Pod定义文件内容,如下所示:

这时,Pod创建以后,就可以获取到对应的环境变量的值:SPECIAL_LEVEL_KEY=very。
- 创建多个ConfigMap对象,Pod从多个ConfigMap对象中读取到对应的配置值
首先,创建第一个ConfigMap对象special-config,该对象定义了配置数据special.how=very,如下所示:
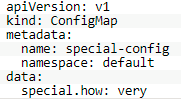
然后,创建第二个ConfigMap对象env-config,该对象定义了配置数据log_level=INFO,如下所示:

最后,就可以在Pod中定义环境变量,如下所示:
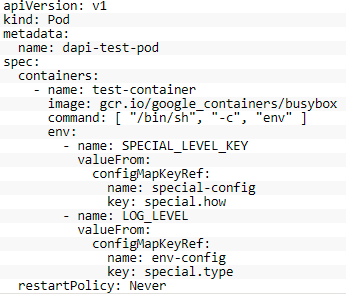
在Pod创建后,可以分别从special-config、env-config中读取环境变量的值:SPECIAL_LEVEL_KEY=very、LOG_LEVEL=INFO。
七、Secret
Secret对象用来保存一些敏感信息,比如密码、OAuth令牌、ssh秘钥等,虽然这些敏感信息可以放到Pod定义中,或者Docker镜像中,但是放到Secret对象中更加安全和灵活。
使用Secret对象时,可以在Pod中引用创建的Secret对象,主要有如下两种方式:
- 挂载到一个或多个容器的Volume中的文件里面
- 当为一个Pod拉取镜像时,被kubectl使用
可以通过将Secret挂载到Volume中,或者以环境变量的形式导出,来被一个Pod中的容器使用。下面是一个示例,在一个Pod中的Volume上挂载一个Secret,如下所示:

通过导出环境变量,使用Secret,示例如下所示:
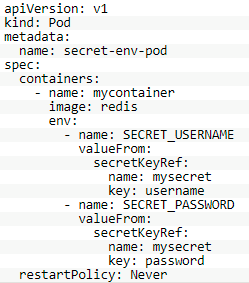
八、Job
一个Job会创建一个或多个Pod,并确保指定数目的Pod能够运行成功。Job会跟踪每个Pod的运行,直到其运行成功,如果该Job跟踪的多个Pod都运行成功,则该Job就变为完成状态。删除一个Job,该Job创建的Pod都会被清理掉。
定义一个Job,示例如下所示:

九、CronJob
Crontab用来管理定时Job,主要使用场景如下:
- 在一个给定的时间点,调度Job运行
- 创建一个周期性运行的Job,例如数据库备份、发送邮件等等
定义一个CronJob,示例配置内容如下所示:
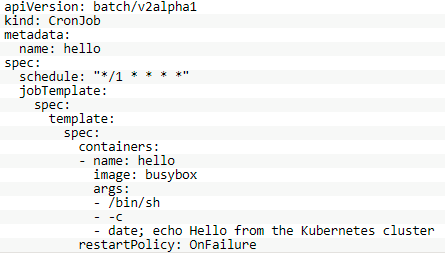
十、Ingress
通常情况下,Service和Pod仅可在集群内部网络中通过IP地址访问。所有到达Edge router的流量或被丢弃或被转发到其它地方。一个Ingress是一组规则的集合,这些规则允许外部请求(公网访问)直接连接到Kubernetes集群内部的Service,
如下图所示:
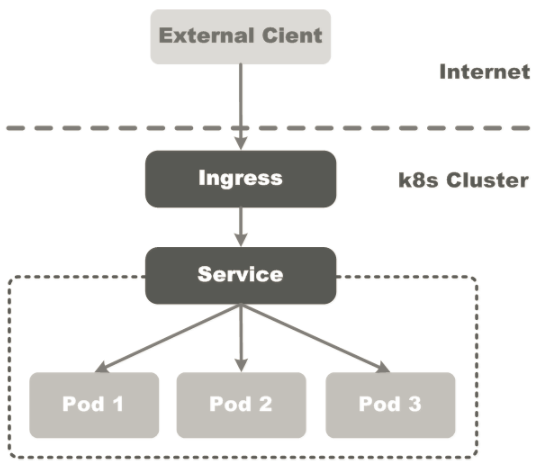
我们可以配置Ingress,为它提供外部(公网)可访问给定Service的规则,如Service URL、负载均衡、SSL、基于名称的虚拟主机等。用户想要基于POST方式请求Ingress资源,需要通过访问Kubernetes API Server来操作Ingress资源。
Ingress Controller是一个daemon进程,它是通过Kubernetes Pod来进行部署的。它负责实现Ingress,通常使用负载均衡器,还可以配置Edge router和其他前端(frontends),以高可用(HA)的方式来处理请求。为了能够使Ingress工作,Kubernetes集群中必须要有个一个Ingress Controller在运行,不同于kube-controller-manager所管理的Controller,我们必须要选择一个适合我们Kubernetes集群的Ingress Controller实现,如果没有合适的就需要开发实现一个。
定义一个Ingress,示例如下所示:

上面rules配置了Ingress的规则列表,目前只支持HTTP规则,该示例使用了HTTP的paths规则,所请求URL能够匹配上paths指定的testpath,都会被转发到backend指定的Service上。
Ingress有如下5种类型:
- 单Service Ingress
- 简单扇出(fanout)
- 基于名称的虚拟主机
- TLS
- 负载均衡
十一、Horizontal Pod Autoscaler (弹性伸缩)
应用运行在容器中,它所依赖的资源的使用率通常并不均衡,资源使用量有时可能达到峰值,有时使用的又很少,为了提高Kubernetes集群的整体资源利用率,我们需要Service中的Pod的个数能够根据实际资源使用量来自动调整。
这时我们就可以使用HPA(Horizontal Pod Autoscaling),它和Pod、Deployment等都是Kubernetes API资源,能实现Kubernetes集群内Service中Pod的水平伸缩。
HPA的工作原理,如下图所示:

通过下面命令,可以对HPA进行各种操作(创建HPA、列出所有HPA、获取HPA详细描述信息、删除HPA):
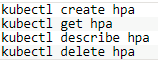
另外,还可以通过kubectl autoscale 命令来创建HPA,例如,执行如下命令:
kubectl autoscale rc foo --min=2 --max=5 --cpu-percent=80
上面示例的命令,要为名称为foo的ReplicationController创建一个HPA对象,使得目标CPU利率用为80%,并且副本的数量保持在2到5之间。
十二、kubectl CLI
kubectl是一个命令行接口,通过它可以执行命令与Kubernetes集群交互。kubectl命令的语法格式,如下所示:
kubectl [command] [TYPE] [NAME] [flags]
上面命令说明中:
command:需要在一种或多种资源上执行的操作,比如:create、get、describe、delete等等,更详细可以参考官网文档。
TYPE:指定资源类型,大小写敏感,当前支持如下这些类型的资源:certificatesigningrequests、clusters、clusterrolebindings、clusterroles、componentstatuses、configmaps、cronjobs、daemonsets、deployments、endpoints、events、horizontalpodautoscalers、ingresses、jobs、limitranges、namespaces、networkpolicies、nodes、persistentvolumeclaims、persistentvolumes、poddisruptionbudget、pods、podsecuritypolicies、podtemplates、replicasets、replicationcontrollers、resourcequotas、rolebindings、roles、secrets、serviceaccounts、services、statefulsets、storageclasses、thirdpartyresources。
NAME:指定资源的名称,大小写敏感。
flags:可选,指定选项标志,比如:-s或-server表示Kubernetes API Server的IP地址和端口。
如果想要了解上述命令的详细用法说明,可以执行帮助命令:
kubectl help
另外,还可以通过官方文档,根据使用的Kubernetes的不同版本,来参考如下链接获取帮助:
- https://kubernetes.io/docs/user-guide/kubectl/v1.7/
- https://kubernetes.io/docs/user-guide/kubectl/v1.6/
- https://kubernetes.io/docs/user-guide/kubectl/v1.5/
下面,举个常用的命令行操作,需要通过YAML文件定义一个Service(详见上文“基本概念”中给出的Service示例),创建一个Service,执行如下命令:
kubectl create -f ./my-k8s-service.yaml
定义任何Kubernetes对象,都是通过YAML文件去配置,使用类似上述命令进行创建。如果想要查看创建Kubernetes对象的结果,比如查看创建Service对象的结果,可通过如下命令查看:
kubectl get services
这样,就能看到当前创建的Service对象的状态。
参考链接
- https://kubernetes.io/
- https://kubernetes.io/docs/concepts/
- https://kubernetes.io/docs/setup/
- http://blog.kubernetes.io/2016/06/container-design-patterns.html
- https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- https://kubernetes.io/docs/concepts/services-networking/service/
- https://kubernetes.io/docs/concepts/storage/volumes/
- https://rootsongjc.gitbooks.io/kubernetes-handbook/
- https://kubernetes.io/docs/user-guide/kubectl-overview/
- https://kubernetes.io/docs/user-guide/kubectl/v1.7/
- https://kubernetes.io/docs/user-guide/kubectl/v1.6/
- https://kubernetes.io/docs/user-guide/kubectl/v1.5/
- https://kubernetes.io/docs/concepts/services-networking/ingress/
- https://github.com/kubernetes/ingress/tree/master/controllers
- https://kubernetes.io/docs/concepts/configuration/secret/
- https://kubernetes.io/docs/tasks/configure-pod-container/configmap/
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/
- https://kubernetes.io/docs/admin/kubelet/
- https://kubernetes.io/docs/admin/kube-proxy/