上篇博文中已经谈到,有两个流程没有讲到。一个是MetaTableAccessor.getRegionLocations,另外一个是ConnectionImplementation.cacheLocation。这一节,就让我们单独来介绍这两个流程。
首先让我们来到MetaTableAccessor.getRegionLocations。
1.调用MetaTableAccessor.getRegionInfo,获取返回结果集中指定的列信息(info:regioninfo)的值。在这个方法的调用过程中,有一个知识点需要大家关注——Result.binarySearch。我将放在后面讲解。
2.然后调用了Result.getNoVersionMap。在这里,完成了对返回结果集的含version版本信息的封装与不含version版本信息的封装,同样,我将放在后面讲解。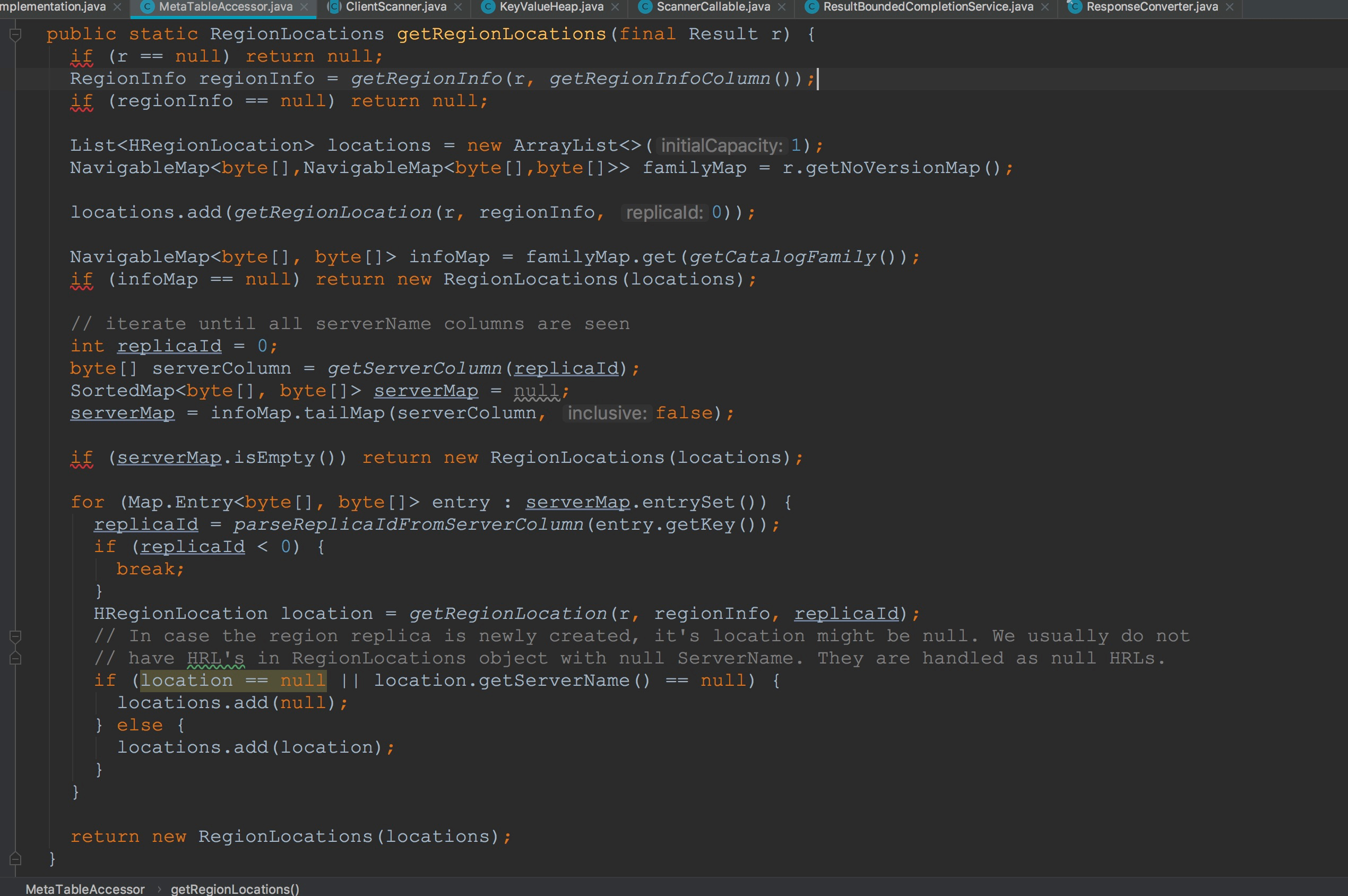
首先让我们来到Result.binarySearch。大家可以看到这里使用的kvs[0]的rowKey,然后使用了传入的family(info)与qualifier(regioninfo)。大家可能比较迷惑,为什么这里的逻辑是这样的。原因很简单,因为这里传入的Cell数组的rowKey都是一样的,要利用Arrays.binarySearch搜索指定family:qualifier。因此首先使用这些信息构造了一个封装了以上信息的FirstOnRowColCell。这里需要注意的是,新建的cell.getTimestamp返回值为HConstants.LATEST_TIMESTAMP = Long.MAX_VALUE。这里,大家可能会对Arrays.binarySearch的返回值比较新奇,为什么结果是负值包括后面为什么有表达式(pos = (pos+1) * -1)。大家感兴趣的可以追一下源码,我只简单说一下结论。在调用Arrays.binarySearch方法时,如果所要搜索的数组中包含键,则返回键在该数组的位置,然而,如果数组中不包含键,那么就返回-(insertion point) - 1。这里的insertion point就是该数组中第一个元素大于键的索引位置(the index of the first element greater than the key)。如果大家还是不懂,在网上搜一下就明白了,我在这里就不详述了。后面通过表达式(pos = (pos+1) * -1)也就获取的Arrays.binarySearch后的insertion point。看到这里大家可能还有点迷惑,不过,相信我在介绍完CellComparatorImpl后,大家可能就恍然大悟了。
接下来让我们来到CellComparatorImpl.compare方法。这里主要调用了compareRows与compareWithoutRow。compareRows比较简单,就是比较传入Cell的rowKey。真正重要的是compareWithoutRow。
接下来让我们来到CellComparatorImpl.compareWithoutRow方法。这里比较容易误会的是compareTimestamps。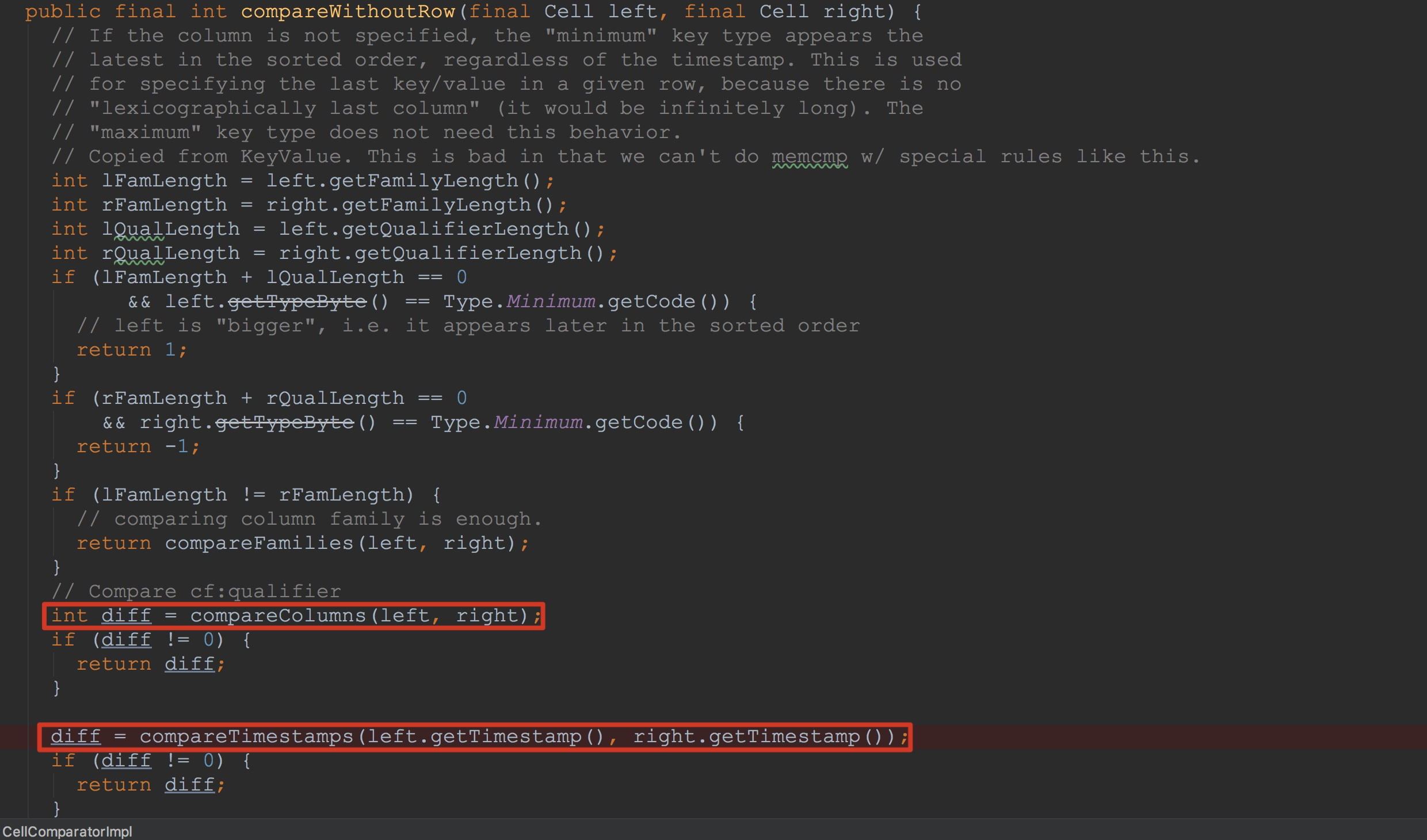
接下来让我们来到CellComparatorImpl.compareTimestamps。正如截图中注释所说,交换顺序以实现将相同的family:qualifier按照时间戳的降序来排列(family与qualifier都是按照升序来排列的)。看到这里,相信大家就能够明白为什么构建的Cell时间戳为Long.MAX_VALUE。
不过,我还是在这里再简单介绍一下。上面我已经提到Arrays.binarySearch中insertion point是该数组中第一个元素大于键的索引位置(the index of the first element greater than the key)。假如,如果说这里的CellComparatorImpl.compareTimestamps为升序排列,那么,上面构造的key的insertion point为数组中相同family:qualifier的index + 1。而这里改为降序之后,构造的key的insertion point为数组中相同family:qualifier的index。而这个结果正是我们需要的。
到这里,大家可能就明白了Result.getColumnLatestCell方法的含义——获取指定family:qualifier中时间戳最接近Long.MAX_VALUE的cell。
接下来我插入一个知识点——Result.getMap与Result.getNoVersionMap。这里获取的是含version信息的列。通过其中的versionMap.put方法我们就可以知道,这里将不同version的value值保存在map中了。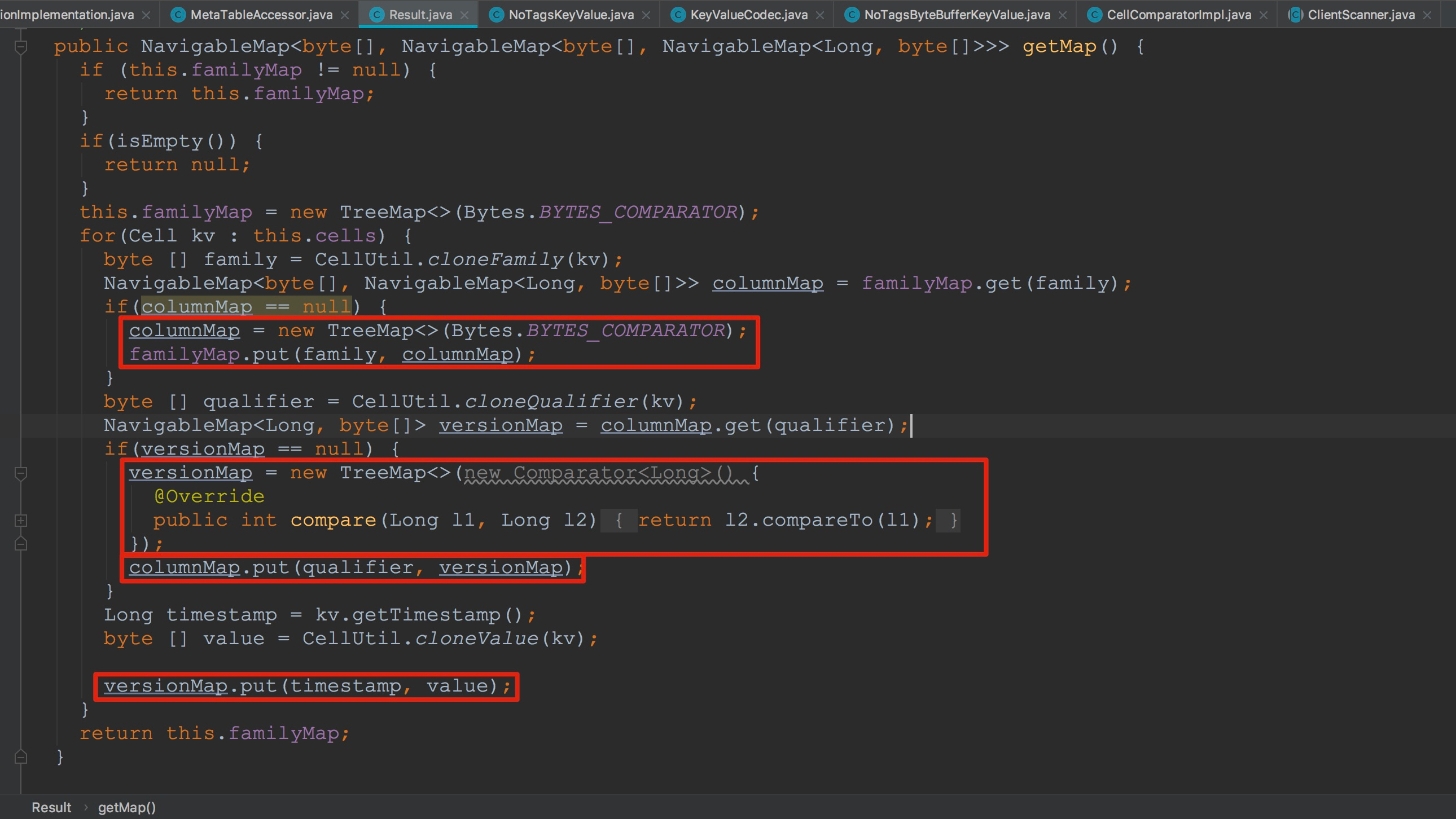
然后来到Result.getNoVersionMap。在这里获取的是不含version的列。由于上面在构造versionMap时传入的Comparator为倒序排序,因此,这里通过qualifierEntry.getValue().firstKey()获得的是最新版本的value。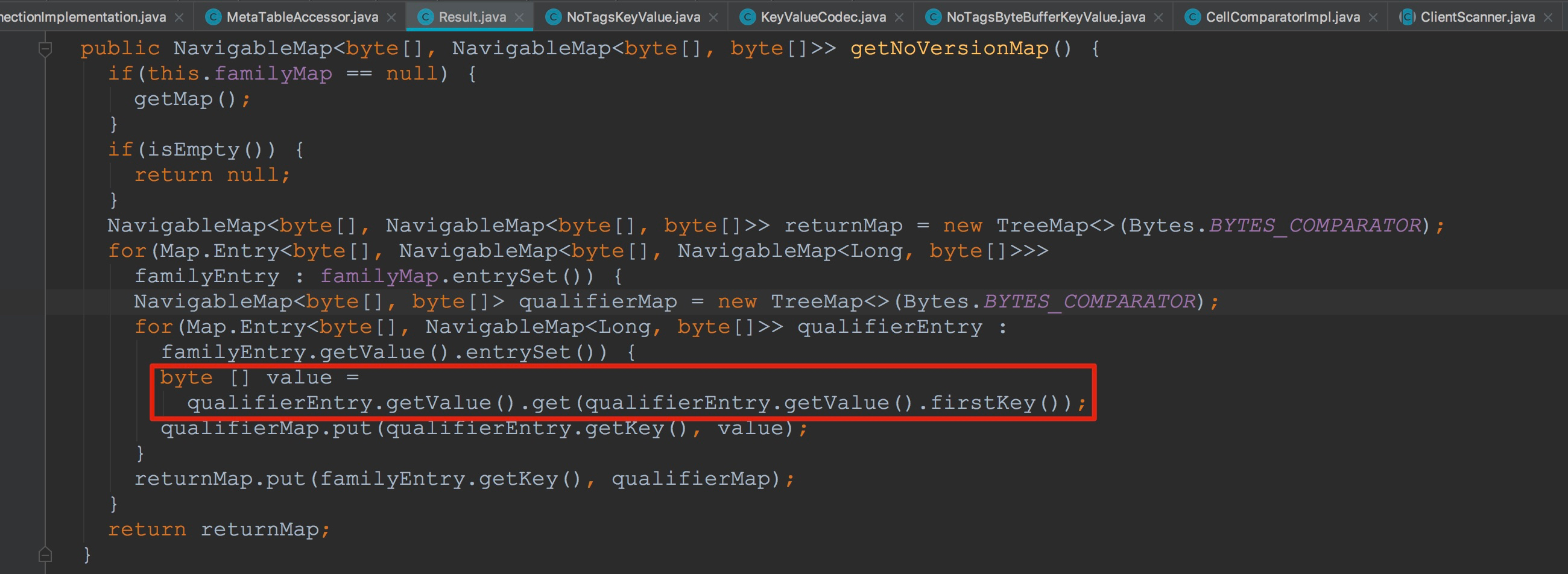
接下来,让我们来到本节中另外一个也是最后一个重要的方法ConnectionImplementation.cacheLocation。由于其主要调用了MetaCache.getCachedLocation,因此,我在这里贴出MetaCache.getCachedLocation源码,如下图所示。其中比较重要的方法是MetaCache.getTableLocations。
接下来让我们来到MetaCache.getTableLocations,如下图所示。如果看过我的上篇博文《HBase之Table.put客户端流程》,大家可能知道,我埋了一个伏笔,也就是这里的最后一个入参。上一篇中的与这里的入参类型不同,但是方法的调用流程是一样的,我就在这里详细讲解。
上图中最后一个入参是java.util.function.Supplier。如下图所示。
上图中的最后一个入参类型是Runnable。看到这里,大家可能就明白了。如果在MetaCache.cachedRegionLocations中并没有相应的key,value对,那么就会调用supplier.get方法,也就是getTableLocations的最后一个入参,重新构建一个CopyOnWriteArrayMap,并且将内部的比较器设置为Bytes.BYTES_COMPARATOR。然后将其放到MetaCache.cachedRegionLocations。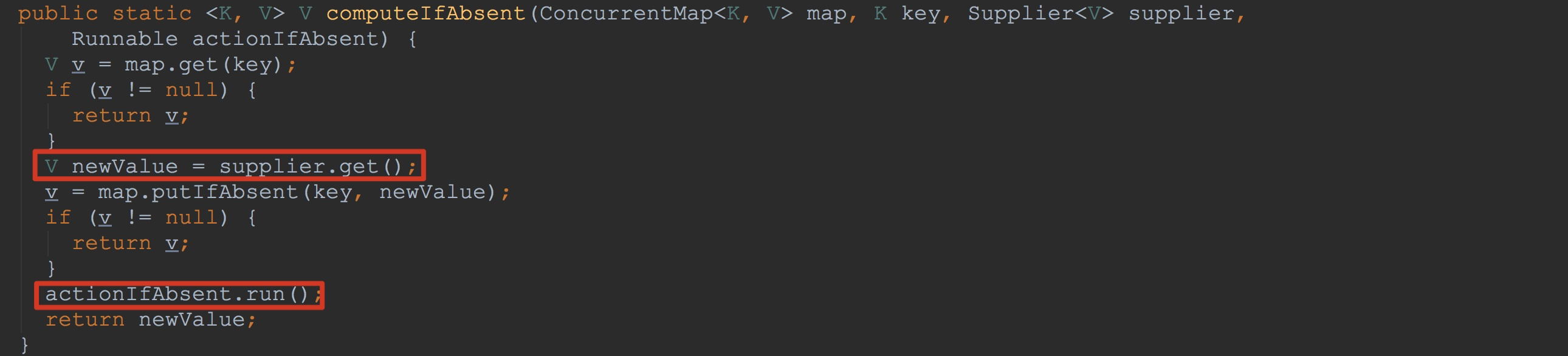
到此为止,完整的《HBase之Table.put客户端流程》就结束了。大家如果有什么疑问或者大数据相关的问题可以发送至我的邮箱15935152719@163. com。
从下一节起,也就是本周末,我将为大家带来HBase的第二章内容——Hbase之Client协议。届时,Client协议中的服务端与客户端的完整流程将为大家一一奉上。如果比较关注其中的内容可以关注我,或者成为我的粉丝,都是就可以及时收到更新啦。