首先,让我们从HTable.put方法开始。由于这一节有很多方法只是简单的参数传递,我就简单略过,但是,关键的方法我还是会截图讲解,所以希望大家尽可能对照源码进行流程分析。另外,在这一节,我单单介绍put操作在客户端的流程,毕竟,这个内容已经很多了。至于具体服务端的流程,我会在后面的章节中介绍到,欢迎大家到时候阅读。
由于这一节的方法还是比较复杂的,我特地画了一张思维导图,大家可以先通过思维导图来对本节的内容有一个大概的了解,置于具体的流程,我在下面将对照源码的贴图一一为大家讲解(在这里声明一点,我在这一节只介绍单个put操作的流程,至于put批处理,大家有兴趣可以自己研究一下)。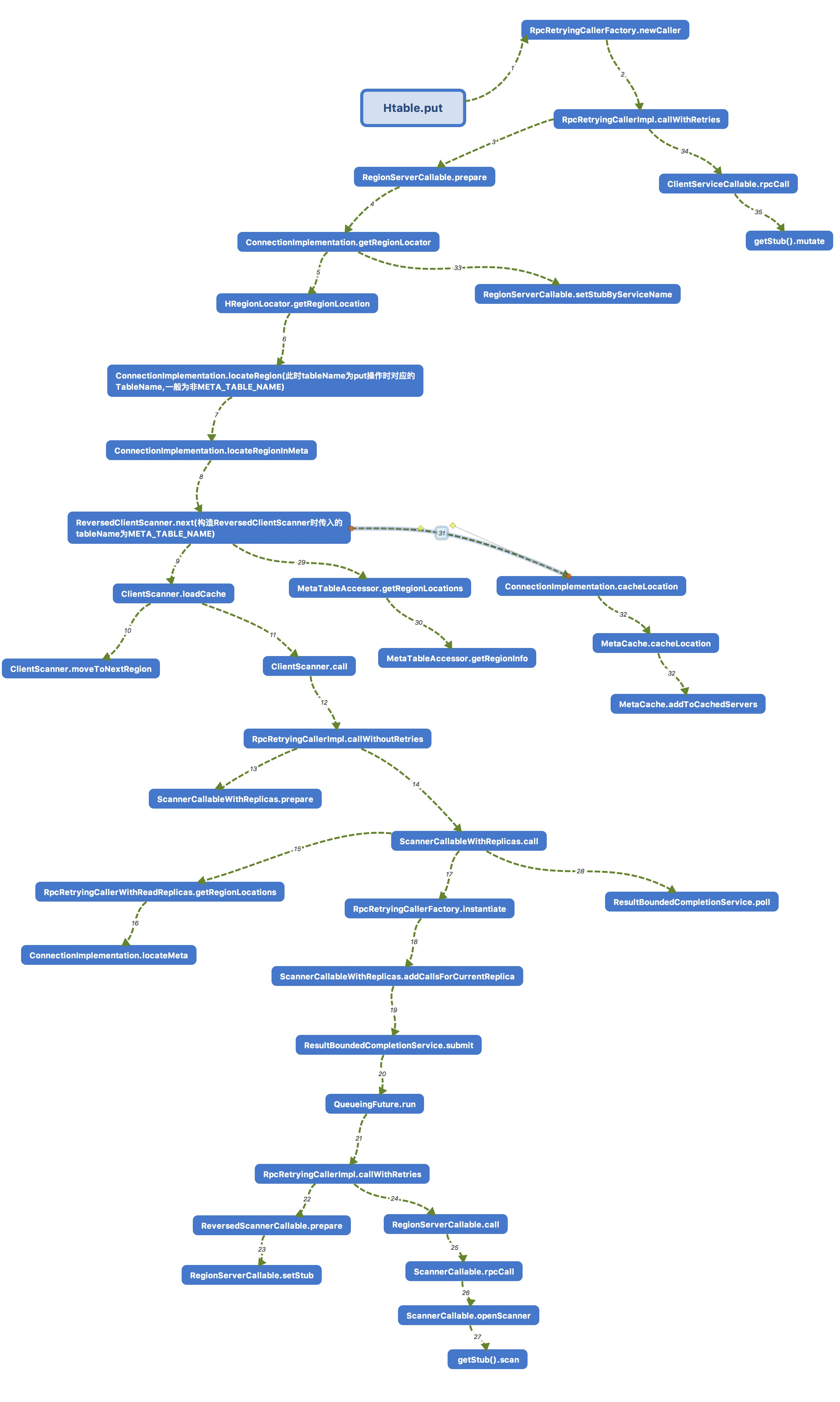
首先,让我们来到HTable.put方法,如下图所示: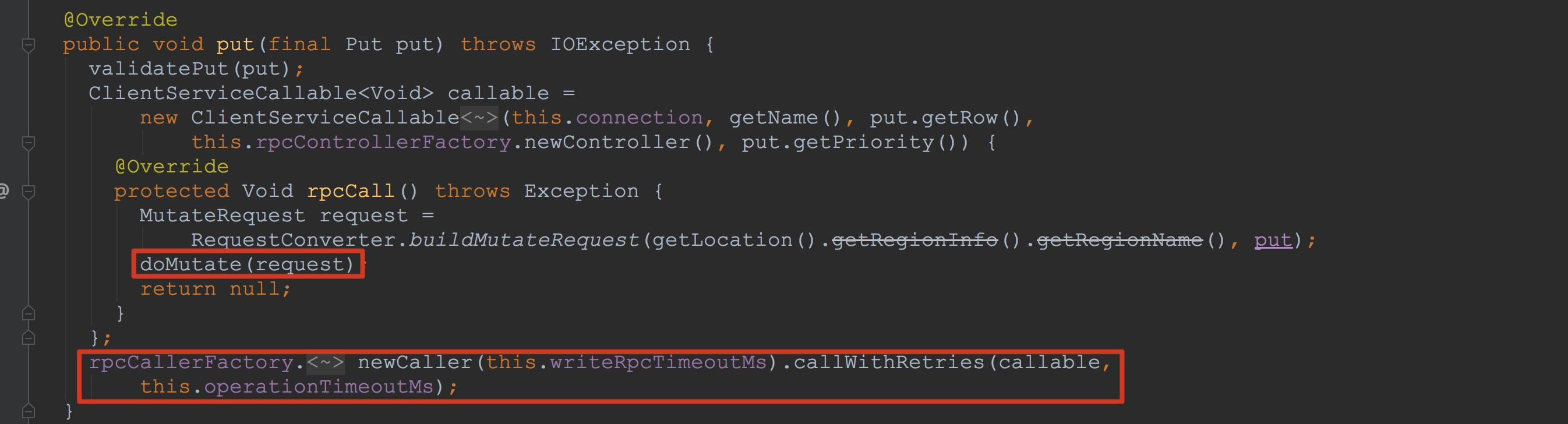 这里我先讲一下这一节的最后调用流程,也同时让大家明确一下在本节我着重要讲解的流程是哪块。在上图中我已经表示出来了,后面方法的调用最后调用到了上面新创建的ClientServiceCallable中覆写的rpcCall方法,也就是调用到了ClientServiceCallable.doMutate。关于这个方法中具体与服务端的交互流程在本节我就略过,但是,在后面的内容中,我会谈到类似的情况,如果大家感兴趣的话,可以继续后面的内容。
这里我先讲一下这一节的最后调用流程,也同时让大家明确一下在本节我着重要讲解的流程是哪块。在上图中我已经表示出来了,后面方法的调用最后调用到了上面新创建的ClientServiceCallable中覆写的rpcCall方法,也就是调用到了ClientServiceCallable.doMutate。关于这个方法中具体与服务端的交互流程在本节我就略过,但是,在后面的内容中,我会谈到类似的情况,如果大家感兴趣的话,可以继续后面的内容。 接下来让我们回到本节的重点。首先是RpcRetryingCallerFactory.newCaller方法的调用,该方法使用RpcRetryingCallerFactory的成员参数创建了RpcRetryingCaller,用于后面对于RetryingCallable的调用(该方法在后面也会多次调用,在后面我就不贴图了)。
接下来让我们回到本节的重点。首先是RpcRetryingCallerFactory.newCaller方法的调用,该方法使用RpcRetryingCallerFactory的成员参数创建了RpcRetryingCaller,用于后面对于RetryingCallable的调用(该方法在后面也会多次调用,在后面我就不贴图了)。 接下来让我们来到RpcRetryingCallerImpl.callWithRetries。这个方法是本节中最为重要的方法,在后面也会多次用到。方法虽然比较长,但大多是异常的情况的解决,在本节中我们就单单介绍callable.prepare与callable.call两个方法。至于interceptor.intercept,由于在构造RpcRetryingCallerFactory时默认的interceptor类型为RetryingCallerInterceptorFactory.NO_OP_INTERCEPTOR,在本节并不会有其它影响,所以我们暂时不需要关注。
接下来让我们来到RpcRetryingCallerImpl.callWithRetries。这个方法是本节中最为重要的方法,在后面也会多次用到。方法虽然比较长,但大多是异常的情况的解决,在本节中我们就单单介绍callable.prepare与callable.call两个方法。至于interceptor.intercept,由于在构造RpcRetryingCallerFactory时默认的interceptor类型为RetryingCallerInterceptorFactory.NO_OP_INTERCEPTOR,在本节并不会有其它影响,所以我们暂时不需要关注。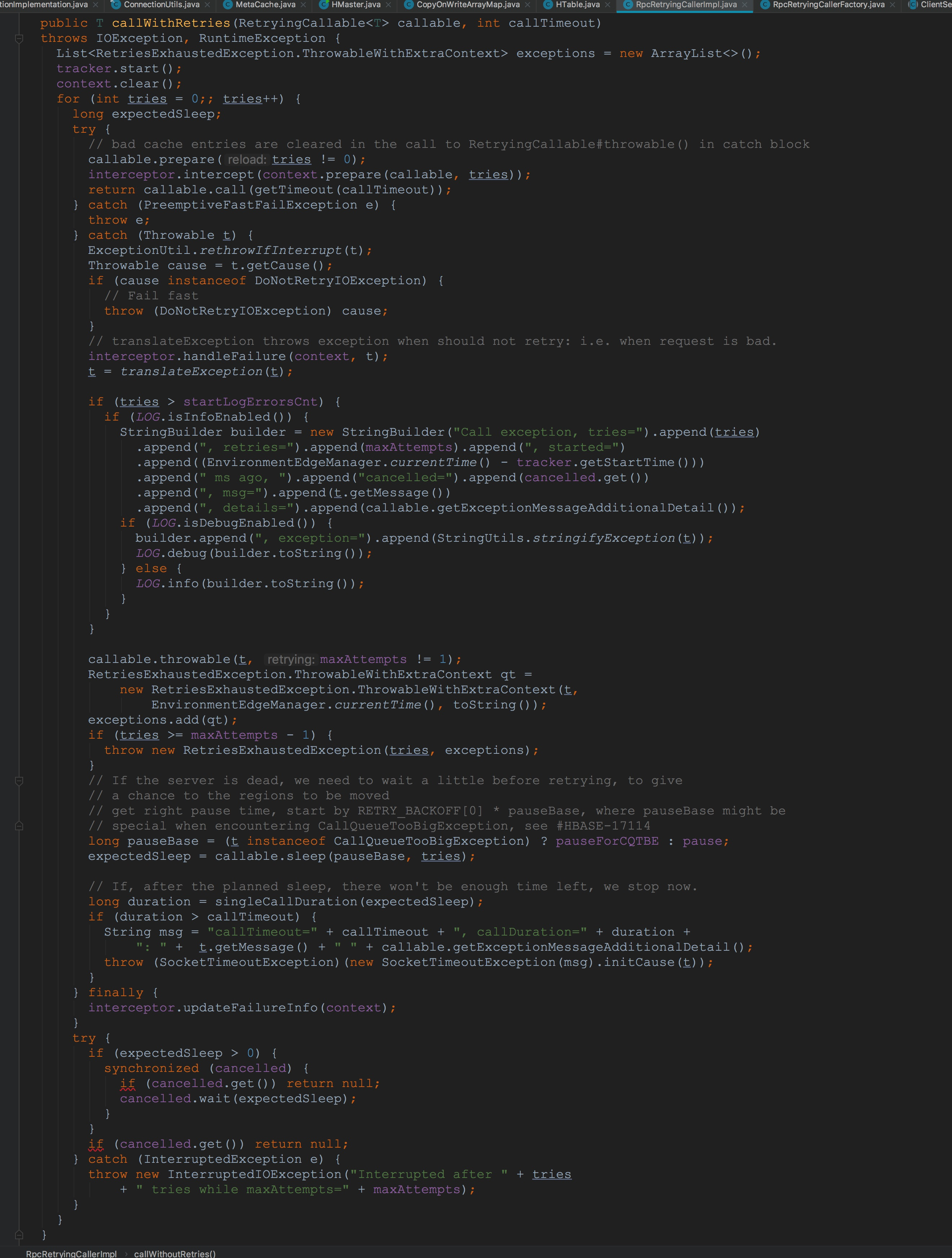 上面的方法调用的callable具体类型为覆写了rpcCall方法的ClientServiceCallable,下面让我们来到ClientServiceCallable类的内部。ClientServiceCallable继承自RegionServerCallable,因此,上面方法实际调用的是RegionServerCallable.prepare与RegionServerCallable.call。
上面的方法调用的callable具体类型为覆写了rpcCall方法的ClientServiceCallable,下面让我们来到ClientServiceCallable类的内部。ClientServiceCallable继承自RegionServerCallable,因此,上面方法实际调用的是RegionServerCallable.prepare与RegionServerCallable.call。 首先让我们来到RegionServerCallable.prepare方法。这里比较重要的方法我已经框选出来了。需要大家特别留意的是最后的setStubByServiceName,一是因为他比较重要,二是我在后面的内容才会介绍,大家到时候可能忘记了,所以在这里特别提醒一下大家。
首先让我们来到RegionServerCallable.prepare方法。这里比较重要的方法我已经框选出来了。需要大家特别留意的是最后的setStubByServiceName,一是因为他比较重要,二是我在后面的内容才会介绍,大家到时候可能忘记了,所以在这里特别提醒一下大家。
这里我先讲一下这一节的最后调用流程,也同时让大家明确一下在本节我着重要讲解的流程是哪块。在上图中我已经表示出来了,后面方法的调用最后调用到了上面新创建的ClientServiceCallable中覆写的rpcCall方法,也就是调用到了ClientServiceCallable.doMutate。关于这个方法中具体与服务端的交互流程在本节我就略过,但是,在后面的内容中,我会谈到类似的情况,如果大家感兴趣的话,可以继续后面的内容。 接下来让我们回到本节的重点。首先是RpcRetryingCallerFactory.newCaller方法的调用,该方法使用RpcRetryingCallerFactory的成员参数创建了RpcRetryingCaller,用于后面对于RetryingCallable的调用(该方法在后面也会多次调用,在后面我就不贴图了)。 接下来让我们来到RpcRetryingCallerImpl.callWithRetries。这个方法是本节中最为重要的方法,在后面也会多次用到。方法虽然比较长,但大多是异常的情况的解决,在本节中我们就单单介绍callable.prepare与callable.call两个方法。至于interceptor.intercept,由于在构造RpcRetryingCallerFactory时默认的interceptor类型为RetryingCallerInterceptorFactory.NO_OP_INTERCEPTOR,在本节并不会有其它影响,所以我们暂时不需要关注。 上面的方法调用的callable具体类型为覆写了rpcCall方法的ClientServiceCallable,下面让我们来到ClientServiceCallable类的内部。ClientServiceCallable继承自RegionServerCallable,因此,上面方法实际调用的是RegionServerCallable.prepare与RegionServerCallable.call。 首先让我们来到RegionServerCallable.prepare方法。这里比较重要的方法我已经框选出来了。需要大家特别留意的是最后的setStubByServiceName,一是因为他比较重要,二是我在后面的内容才会介绍,大家到时候可能忘记了,所以在这里特别提醒一下大家。 容易看到,首先调用了connection.getRegionLocator获得一个新构建的HRegionLocator(这里就不截图了,因为实在是没有什么内容需要讲),不过大家需要注意的是,这里的tableName是我们实际要查询到tableName,而后面会用到META_TABLE_NAME,容易混淆,我在这里简单提一下。接下来调用了HRegionLocator.getRegionLocation。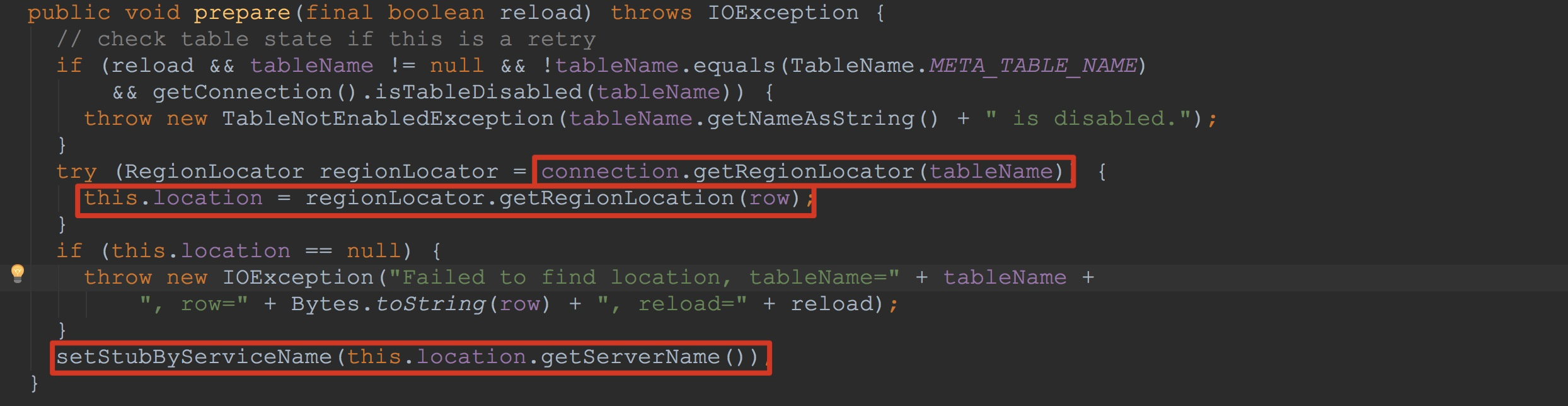 在调用HRegionLocator.getRegionLocation时,这里会有一系列简单方法的调用,由于在上面的导图中我并没有画出,在这里我就一一贴图描述。
在调用HRegionLocator.getRegionLocation时,这里会有一系列简单方法的调用,由于在上面的导图中我并没有画出,在这里我就一一贴图描述。



在调用HRegionLocator.getRegionLocation时,这里会有一系列简单方法的调用,由于在上面的导图中我并没有画出,在这里我就一一贴图描述。

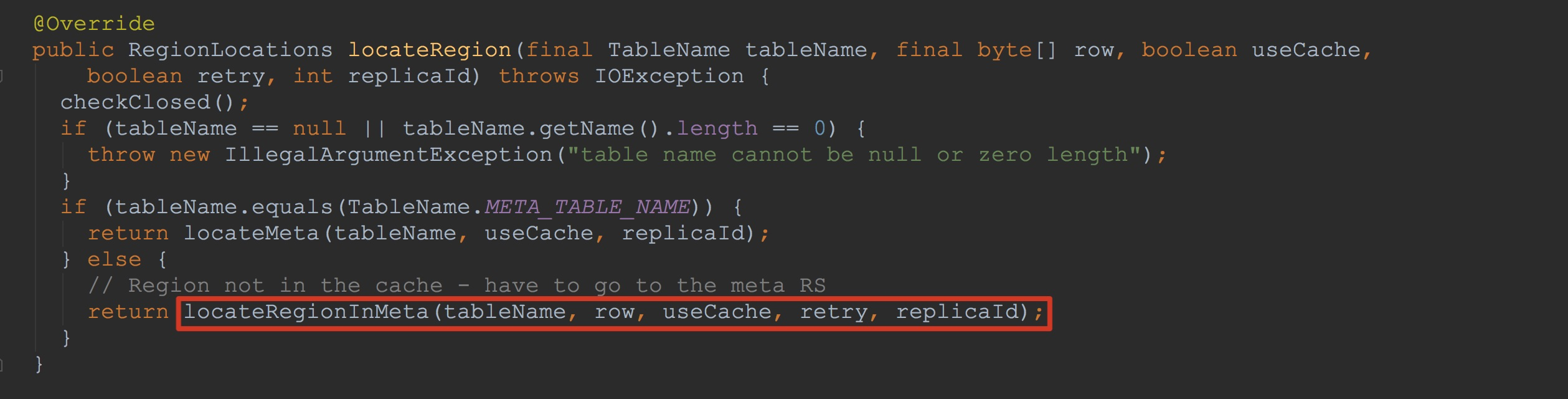 一系列方法走下来,到这里就到了比较重要的方法。由于这个是长图,没有办法框选除重点,我就在文字中一一介绍该方法中调用的比较好重要的方法。
一系列方法走下来,到这里就到了比较重要的方法。由于这个是长图,没有办法框选除重点,我就在文字中一一介绍该方法中调用的比较好重要的方法。 1.getCachedLocation,该方法简介调用到了metaCache.getCachedLocation,但此时,由于我们是第一次调用该表的信息,并没有放到缓存中,因此,这里返回的locations = null。
2.然后我们来到RegionInfo.createRegionName,需要注意的是,其入参row就是我们put操作创建的rowKey,也就是我们常说的行键。另外,在metaStartKey中传入的id为HConstants.NINES(NINES = "99999999999999"),而在metaStopKey中传入的id为空字符串。
3.接着构造了Scan。其中withStartRow与withStopRow中的inclusive入参都为true。将reversed设置为true,并且将catalog family设置为"info"(CATALOG_FAMILY_STR = "info")。大家可能注意到了,这里的info列族在我们的表中并不一定存在。到了这里,大家可能就猜到我在前面埋的伏笔了。没错,这里构建的Scan是为了后面的查询后面的META_TABLE_NAME做准备。
4.紧接着来到fro循环中,这里连着调用了两次getCachedLocation,后面的那次调用加了锁,类似我们在单例设计模式中流程,加锁以确保对象不会重复。
5.然后构建了ReversedClientScanner对象。(鉴于之前经验,贴太多图容易扰乱大家的思维,我在这里尽量用文字来介绍)。ReversedClientScanner是ClientScanner的子类,另外,大家需要注意的是,在构造ReversedClientScanner时传入的tableName为TableName.META_TABLE_NAME。在ReversedClientScanner的构造过程中,虽然有一些需要注意的地方,不过,我还是放在后面来描述,以便大家能够更好的理解整个流程。
6.接下来调用了ReversedClientScanner.next,大家千万不要小看这个方法,这个方法里面的一系列调用时非常复杂的,也是本节的另外一个重点,我将在后面详细介绍。
7.然后调用了MetaTableAccessor.getRegionLocations,其入参为ReversedClientScanner.next的返回值。这个方法的详细流程也比较重要,同样,我放到后面为大家讲解。
8.最后调用了cacheLocation,也就是将当前tableName放到缓存中。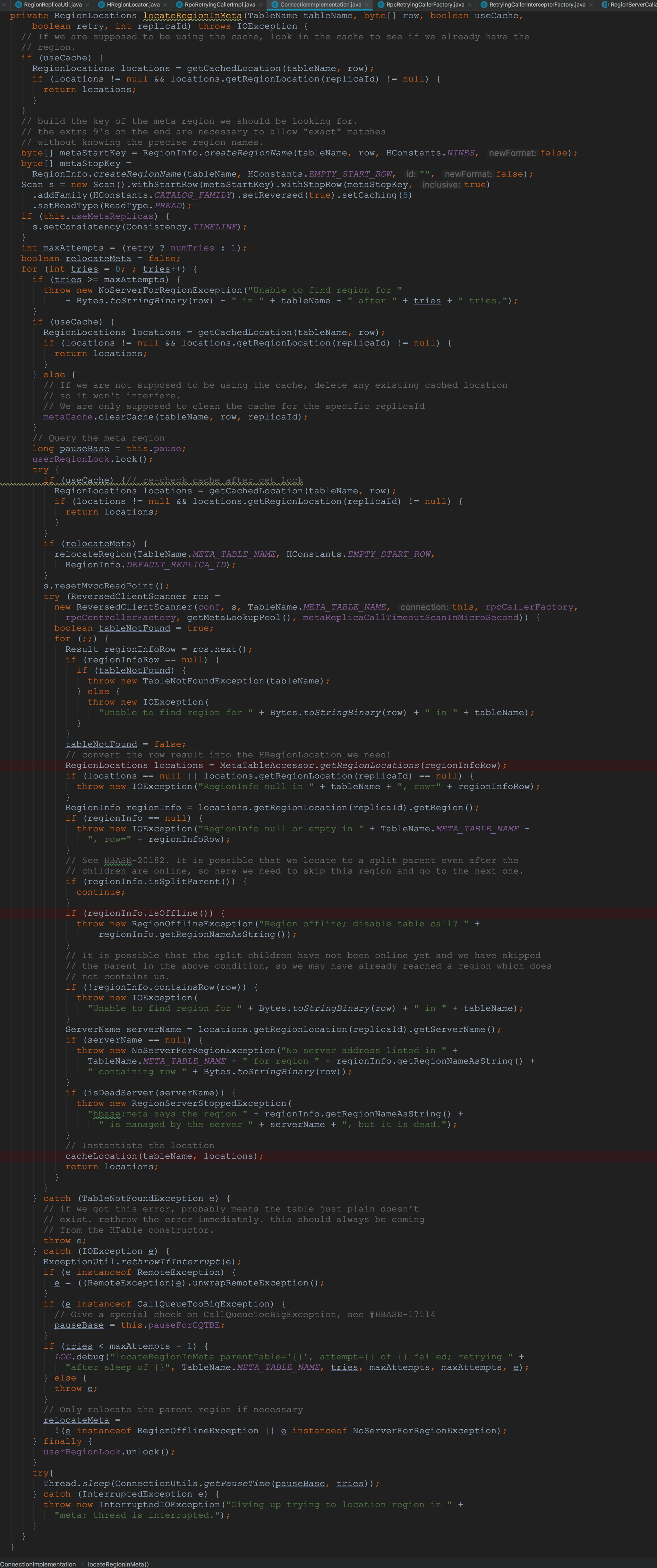 上面,我将ConnectionImplementation.locateRegionInMeta方法中调用的各个流程都简单介绍了一下,下面,我就选择其中比较重要的方法来详细描述。
上面,我将ConnectionImplementation.locateRegionInMeta方法中调用的各个流程都简单介绍了一下,下面,我就选择其中比较重要的方法来详细描述。
上面,我将ConnectionImplementation.locateRegionInMeta方法中调用的各个流程都简单介绍了一下,下面,我就选择其中比较重要的方法来详细描述。 首先让我们来到ReversedClientScanner.next。这个方法调用了ClientScanner.nextWithSyncCache,如下图所示: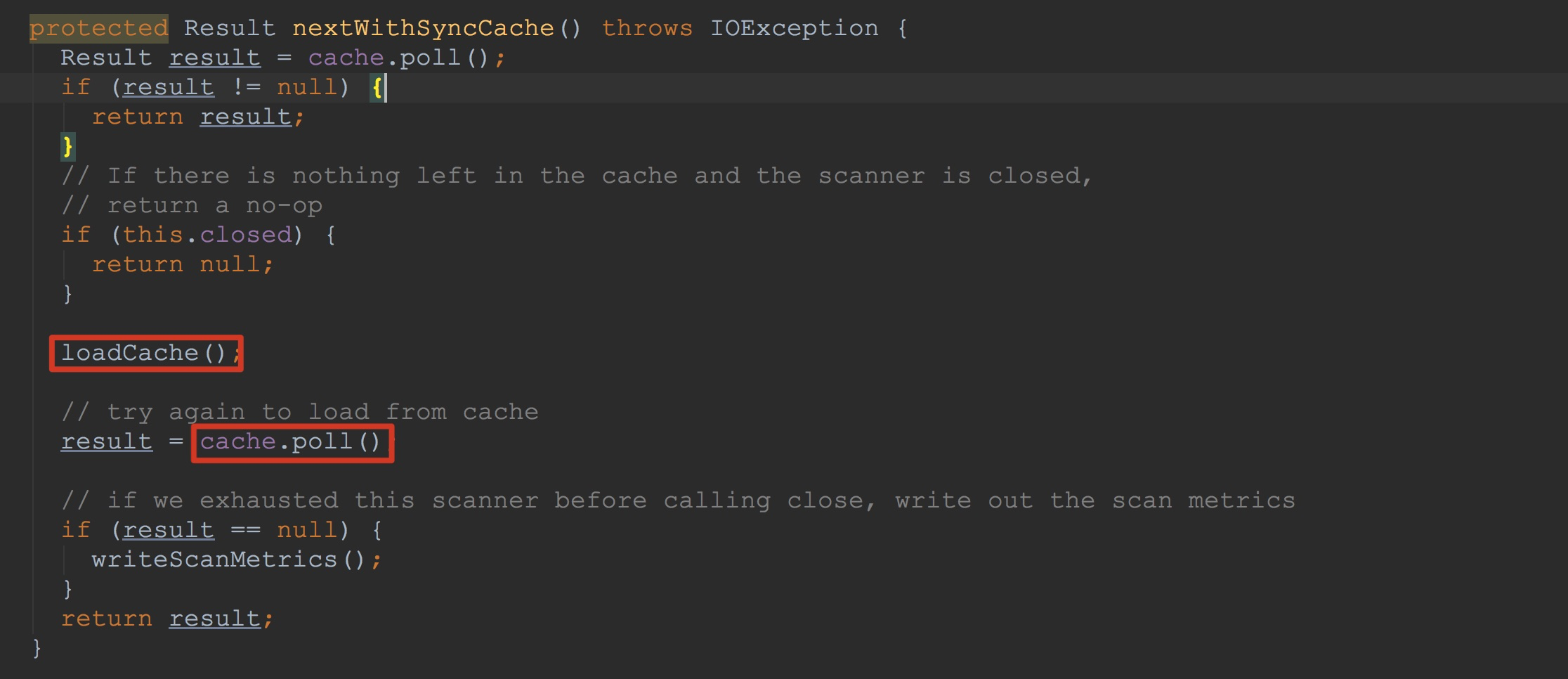 上图框选的两个方法都比较重要,让我们首先介绍比较复杂的loadCache,如下图所示。
上图框选的两个方法都比较重要,让我们首先介绍比较复杂的loadCache,如下图所示。
上图框选的两个方法都比较重要,让我们首先介绍比较复杂的loadCache,如下图所示。 看到这个方法大家可能比较慌,没有关系,我会在这里为大家一一介绍。
1.首先调用了moveToNextRegion。该方法首先调用closeScanner(其间首先调用了成员变量callable.setClose方法,然后调用了ClientScanner.call方法,这个方法我在后面也会提到,最后将当前成员变量callable中的值置为null,简而言之,将成员变量callable.setClose置为null)。
然后构造了ScannerCallableWithReplicas并赋给成员变量callable。在构造ScannerCallableWithReplicas时需要注意的是其中创建了ReversedScannerCallable。也就是说ScannerCallableWithReplicas的成员变量currentScannerCallable为ReversedScannerCallable。顺便提一下,ScannerCallableWithReplicas的成员变量scan为我们在上面构造的scan。
2.接着调用了ClientScanner.call方法。这里的调用流程比较繁琐。为了更清楚的解释清楚loadCache方法,我们先跳过这里,假设其中已经有了返回值。
3.然后调用了scanResultCache.addAndGet。简单提示一下我们这里的scanResultCache类型为CompleteScanResultCache。
4.然后将结果集中的内容遍历放到成员变量cache中。这里我们可以回过头来看看上面的图。上面图中我框选了cache.poll方法。也就是说cache.poll将在loadCache方法中放入的结果集取出来。
 上面我提到过很多次ClientScanner.call方法,但是都没有详细描述,下面我就特意来讲解该方法。其实这个方法很简单,只是调用了方法RpcRetryingCaller.callWithoutRetries。这里的caller是在ReversedClientScanner方法构造时创建的(上面只是提到说构造ReversedClientScanner有需要注意的地方,也就是这里,其截图我在上面也已经贴出来了)。
上面我提到过很多次ClientScanner.call方法,但是都没有详细描述,下面我就特意来讲解该方法。其实这个方法很简单,只是调用了方法RpcRetryingCaller.callWithoutRetries。这里的caller是在ReversedClientScanner方法构造时创建的(上面只是提到说构造ReversedClientScanner有需要注意的地方,也就是这里,其截图我在上面也已经贴出来了)。 接下来让我们来到RpcRetryingCallerImpl.callWithoutRetries。这里的入参callable我在上面的方法loadCache已经介绍过了。其类型为ScannerCallableWithReplicas。由于ScannerCallableWithReplicas.prepare方法为空实现,我在这里就不贴图了,接下来将重点放在ScannerCallableWithReplicas.call。
接下来让我们来到RpcRetryingCallerImpl.callWithoutRetries。这里的入参callable我在上面的方法loadCache已经介绍过了。其类型为ScannerCallableWithReplicas。由于ScannerCallableWithReplicas.prepare方法为空实现,我在这里就不贴图了,接下来将重点放在ScannerCallableWithReplicas.call。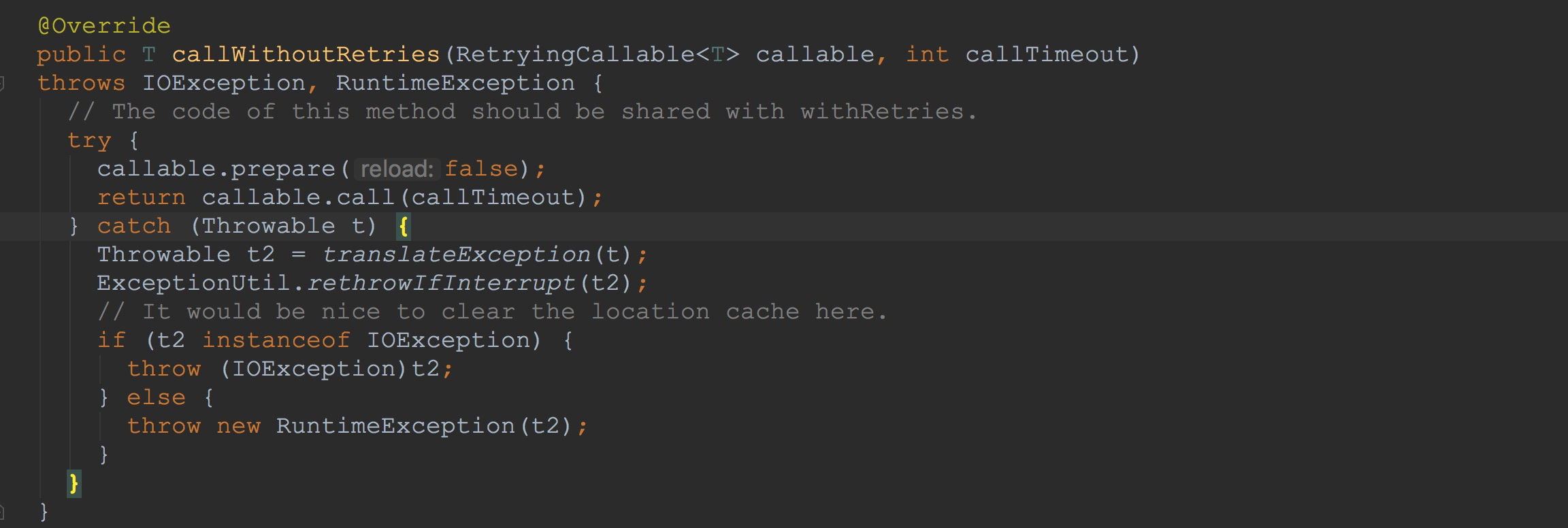 让我们来到ScannerCallableWithReplicas.call,如下图所示。
让我们来到ScannerCallableWithReplicas.call,如下图所示。 1.在ClientScanner.closeScanner方法调用时,会走上面的if判断。由于currentScannerCallable.closed的值为true。
2.由于默认的成员变量regionReplication,因此会调用RpcRetryingCallerWithReadReplicas.getRegionLocations。这个方法的调用与我们今天的主要流程并没有什么太多的联系,因此,在这里简单略过。该方法我可能会放在后面的章节中讲到。
3.构造了ResultBoundedCompletionService。这个方法比较重要,在后面的流程中我会反复讲到。
4.调用了addCallsForCurrentReplica,将成员变量currentScannerCallable封装到ScannerCallableWithReplicas.RetryingRPC中,并交由ResultBoundedCompletionService提交。
5.接着调用cs.poll,获取其提交的任务的返回值。
后面我将详细讲解。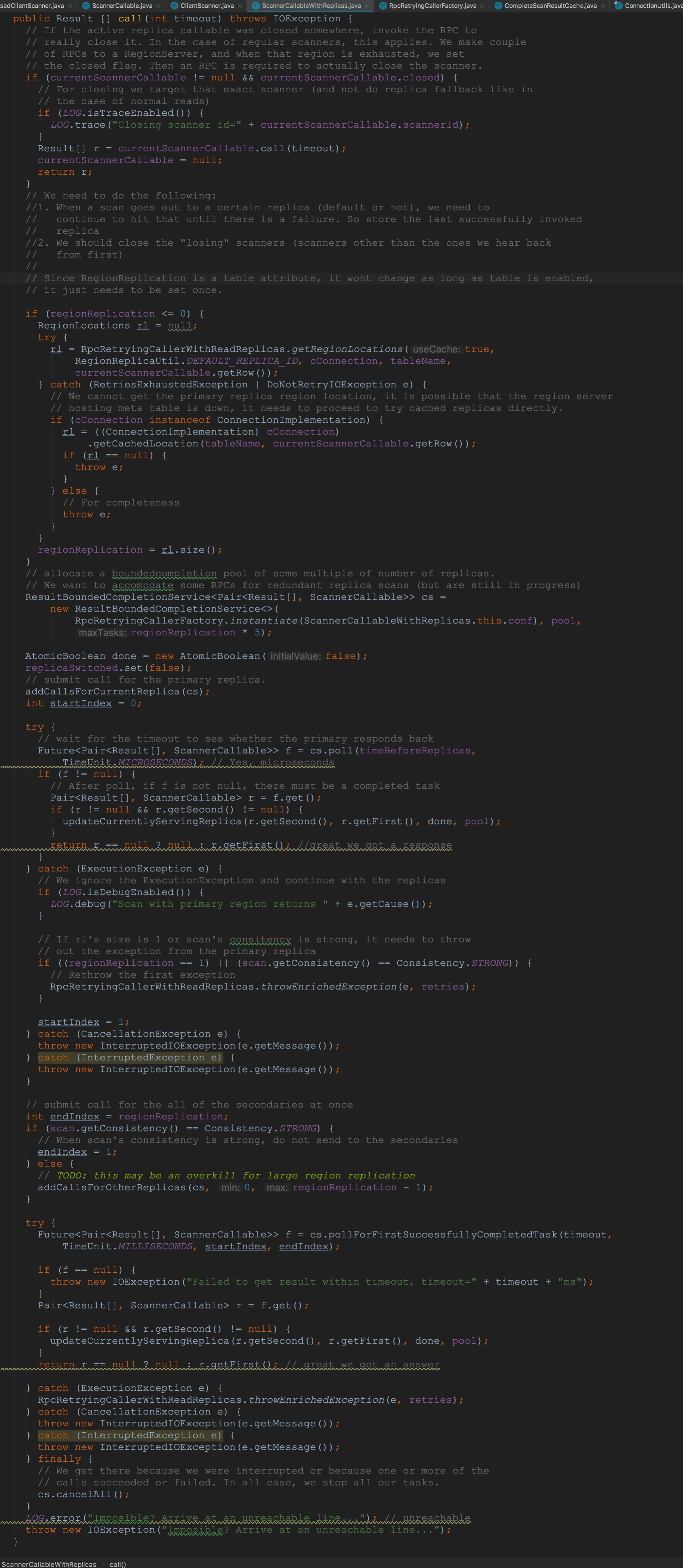 首先来到ScannerCallableWithReplicas.addCallsForCurrentReplica方法。容易看到,将成员变量currentScannerCallable封装到RetryingRPC中。然后调用了ResultBoundedCompletionService.submit。这里着重提醒一下大家,这里的currentScannerCallable类型为ReversedScannerCallable。
首先来到ScannerCallableWithReplicas.addCallsForCurrentReplica方法。容易看到,将成员变量currentScannerCallable封装到RetryingRPC中。然后调用了ResultBoundedCompletionService.submit。这里着重提醒一下大家,这里的currentScannerCallable类型为ReversedScannerCallable。 接着让我们来到ResultBoundedCompletionService.submit,如下图所示。
接着让我们来到ResultBoundedCompletionService.submit,如下图所示。
首先来到ScannerCallableWithReplicas.addCallsForCurrentReplica方法。容易看到,将成员变量currentScannerCallable封装到RetryingRPC中。然后调用了ResultBoundedCompletionService.submit。这里着重提醒一下大家,这里的currentScannerCallable类型为ReversedScannerCallable。 接着让我们来到ResultBoundedCompletionService.submit,如下图所示。 这里将传入的RetryingRPC封装到QueueingFuture,然后调用了executor.execute。由于QueueingFuture继承自java.util.concurrent.RunnableFuture,也就是在调用executor.execute时,QueueingFuture.run方法会执行。 接下来让我们来到QueueingFuture。在下图中,我框选出了其中比较重要的方法。
接下来让我们来到QueueingFuture。在下图中,我框选出了其中比较重要的方法。
接下来让我们来到QueueingFuture。在下图中,我框选出了其中比较重要的方法。 首先这里调用了RpcRetryingCallerImpl.callWithRetries方法(由于这个方法我在上面已经提到过了,因此在这里就不贴图了)。重要的是其中的入参future类型为ScannerCallableWithReplicas.RetryingRPC。另外后面将当前QueueingFuture添加到ResultBoundedCompletionService成员变量completedTasks中。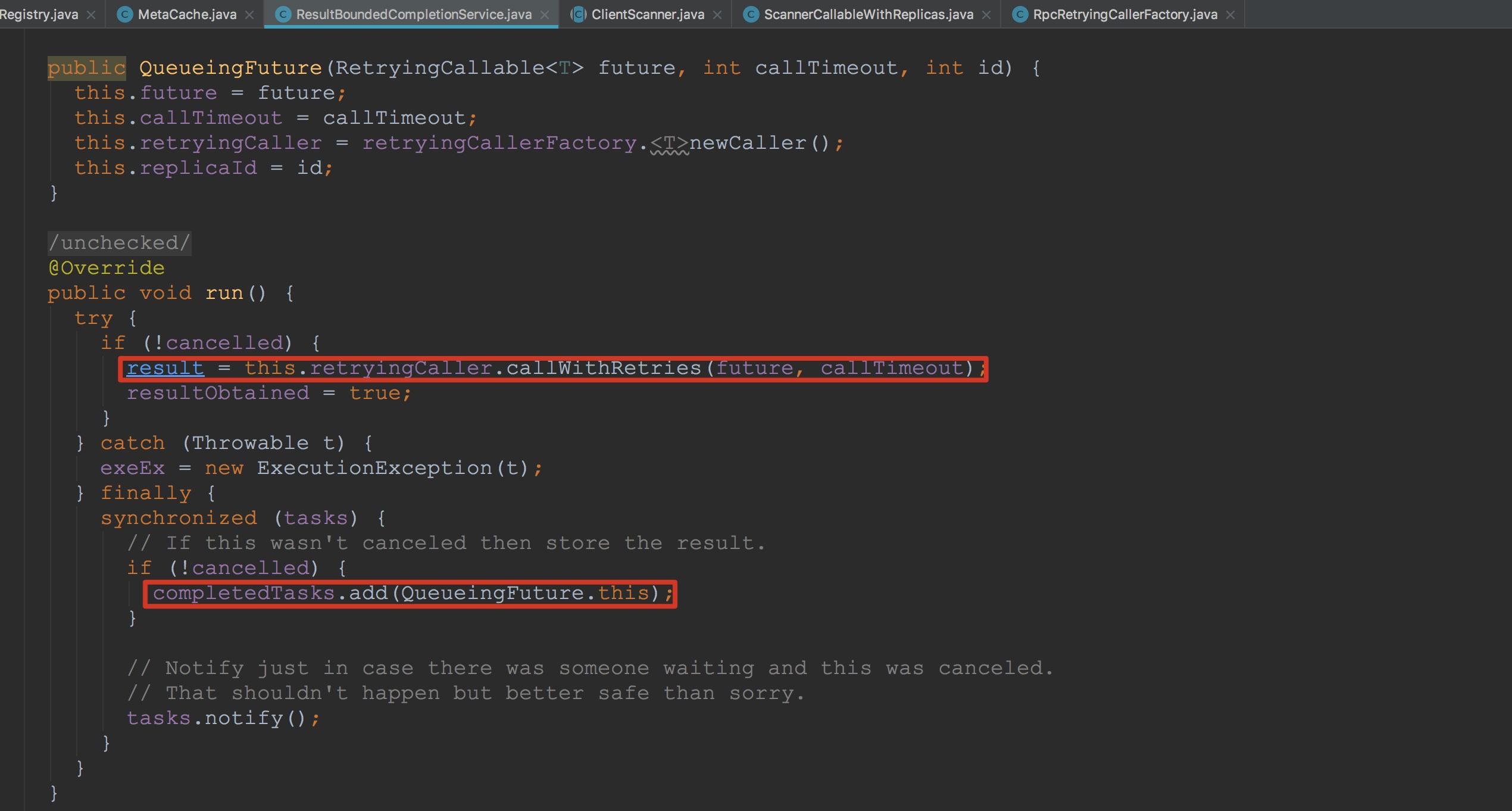 让我们来到ScannerCallableWithReplicas.RetryingRPC.prepare方法。如下图所示。大家可能对这里的成员变量callable比较模糊了,大家可以往上翻到方法addCallsForCurrentReplica的描述,没错这里的callable就是ScannerCallableWithReplicas的成员变量currentScannerCallable。而ScannerCallableWithReplicas.currentScannerCallable正是在构造ScannerCallableWithReplicas时传入的ReversedScannerCallable。
让我们来到ScannerCallableWithReplicas.RetryingRPC.prepare方法。如下图所示。大家可能对这里的成员变量callable比较模糊了,大家可以往上翻到方法addCallsForCurrentReplica的描述,没错这里的callable就是ScannerCallableWithReplicas的成员变量currentScannerCallable。而ScannerCallableWithReplicas.currentScannerCallable正是在构造ScannerCallableWithReplicas时传入的ReversedScannerCallable。 接下来让我们来到ReversedScannerCallable.prepare。由于这是第一次调用prepare方法,因此其成员变量instantiated为false。这里简单提一下,这里的getRow方法获取的是我们调用put时的行键,也就是我们对于目标表的rowKey。由于这里的tableName为TableName.META_TABLE_NAME,其rowKey在后面并没有用到。
接下来让我们来到ReversedScannerCallable.prepare。由于这是第一次调用prepare方法,因此其成员变量instantiated为false。这里简单提一下,这里的getRow方法获取的是我们调用put时的行键,也就是我们对于目标表的rowKey。由于这里的tableName为TableName.META_TABLE_NAME,其rowKey在后面并没有用到。
让我们来到ScannerCallableWithReplicas.RetryingRPC.prepare方法。如下图所示。大家可能对这里的成员变量callable比较模糊了,大家可以往上翻到方法addCallsForCurrentReplica的描述,没错这里的callable就是ScannerCallableWithReplicas的成员变量currentScannerCallable。而ScannerCallableWithReplicas.currentScannerCallable正是在构造ScannerCallableWithReplicas时传入的ReversedScannerCallable。 接下来让我们来到ReversedScannerCallable.prepare。由于这是第一次调用prepare方法,因此其成员变量instantiated为false。这里简单提一下,这里的getRow方法获取的是我们调用put时的行键,也就是我们对于目标表的rowKey。由于这里的tableName为TableName.META_TABLE_NAME,其rowKey在后面并没有用到。 然后调用了ReversedScannerCallable.setStub方法。为成员变量stub的赋值。其值为getConnection().getClient(getLocation().getServerName())调用的返回值。 让我们来到ConnectionImplementation.getClient方法。看过我博文《HBase之HRegionServer启动(含与HMaster交互)》的同学看到这里可能就比较熟悉。 没错,这里正是通过ClientProtos.ClientService.newBlockingStub构造了协议ClientProtos.ClientService的客户端stub。关于与服务端交互的流程,我在《HBase之HRegionServer启动(含与HMaster交互)》中已经具体介绍了,大家感兴趣的可以去看一下,我们这里来描述比较重要一个点。
让我们来到ConnectionImplementation.getClient方法。看过我博文《HBase之HRegionServer启动(含与HMaster交互)》的同学看到这里可能就比较熟悉。 没错,这里正是通过ClientProtos.ClientService.newBlockingStub构造了协议ClientProtos.ClientService的客户端stub。关于与服务端交互的流程,我在《HBase之HRegionServer启动(含与HMaster交互)》中已经具体介绍了,大家感兴趣的可以去看一下,我们这里来描述比较重要一个点。
让我们来到ConnectionImplementation.getClient方法。看过我博文《HBase之HRegionServer启动(含与HMaster交互)》的同学看到这里可能就比较熟悉。 没错,这里正是通过ClientProtos.ClientService.newBlockingStub构造了协议ClientProtos.ClientService的客户端stub。关于与服务端交互的流程,我在《HBase之HRegionServer启动(含与HMaster交互)》中已经具体介绍了,大家感兴趣的可以去看一下,我们这里来描述比较重要一个点。 就是computeIfAbsentEx的最后一个入参IOExceptionSupplier。他类似于java中的Supplier(类似的方法调用我在后面讲解方法MetaTableAccessor.getRegionLocations)。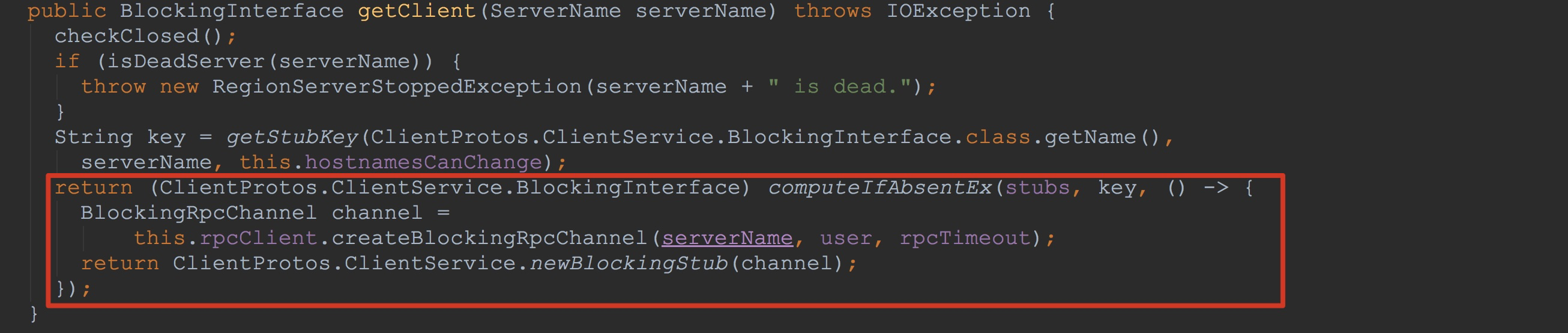 在第一次调用时,我们的stubs中并没有到该serverName的客户端stub,因此调用了入参supplier的get方法。也就是我们上面看到的lambda表达式方法内容被调用。
在第一次调用时,我们的stubs中并没有到该serverName的客户端stub,因此调用了入参supplier的get方法。也就是我们上面看到的lambda表达式方法内容被调用。 到这里,ReversedScannerCallable.prepare方法就调用完成了。这个还有一个需要注意的点就是ReversedScannerCallable.prepare方法的最后将其成员变量instantiated置为true。
到这里,ReversedScannerCallable.prepare方法就调用完成了。这个还有一个需要注意的点就是ReversedScannerCallable.prepare方法的最后将其成员变量instantiated置为true。
在第一次调用时,我们的stubs中并没有到该serverName的客户端stub,因此调用了入参supplier的get方法。也就是我们上面看到的lambda表达式方法内容被调用。 到这里,ReversedScannerCallable.prepare方法就调用完成了。这个还有一个需要注意的点就是ReversedScannerCallable.prepare方法的最后将其成员变量instantiated置为true。 接下来让我们来到ScannerCallableWithReplicas.RetryingRPC.call方法(这里的callable类型为ReversedScannerCallable)。
这里再次调用了RpcRetryingCallerImpl.callWithRetries,由于ReversedScannerCallable.prepare方法已经调用,并且其成员变量instantiated被置为true,所以上面描述的内容并不会再次调用(这里框选的内容作为后面的伏笔)。 也就是说,接下来应该调用的是ReversedScannerCallable.call。由于其并没有call方法,因此,会一直调用到其父类RegionServerCallable.call。如下图所示。这里的rpcController类型为HBaseRpcControllerImpl。接下来调用了rpcCall方法。由于ReversedScannerCallable中并没有rpcCall方法的实现,而在其父类ScannerCallable有实现rpcCall。
也就是说,接下来应该调用的是ReversedScannerCallable.call。由于其并没有call方法,因此,会一直调用到其父类RegionServerCallable.call。如下图所示。这里的rpcController类型为HBaseRpcControllerImpl。接下来调用了rpcCall方法。由于ReversedScannerCallable中并没有rpcCall方法的实现,而在其父类ScannerCallable有实现rpcCall。 接下来,让我们来到ScannerCallable.rpcCall。由于默认的成员变量scannerId为-1,因此,会调用openScanner。由于openScanner方法仅仅是通过Client协议发送到服务端。关于rpc流程我在博客《hbase之RPC调用流程简介》中已经介绍过了,感兴趣的同学可以去看一下,那篇博文讲的比较浅显,我会在春节期间将那篇内容更新,大家可以关注我,到时候有更新大家也就收到通知了。
接下来,让我们来到ScannerCallable.rpcCall。由于默认的成员变量scannerId为-1,因此,会调用openScanner。由于openScanner方法仅仅是通过Client协议发送到服务端。关于rpc流程我在博客《hbase之RPC调用流程简介》中已经介绍过了,感兴趣的同学可以去看一下,那篇博文讲的比较浅显,我会在春节期间将那篇内容更新,大家可以关注我,到时候有更新大家也就收到通知了。
也就是说,接下来应该调用的是ReversedScannerCallable.call。由于其并没有call方法,因此,会一直调用到其父类RegionServerCallable.call。如下图所示。这里的rpcController类型为HBaseRpcControllerImpl。接下来调用了rpcCall方法。由于ReversedScannerCallable中并没有rpcCall方法的实现,而在其父类ScannerCallable有实现rpcCall。 接下来,让我们来到ScannerCallable.rpcCall。由于默认的成员变量scannerId为-1,因此,会调用openScanner。由于openScanner方法仅仅是通过Client协议发送到服务端。关于rpc流程我在博客《hbase之RPC调用流程简介》中已经介绍过了,感兴趣的同学可以去看一下,那篇博文讲的比较浅显,我会在春节期间将那篇内容更新,大家可以关注我,到时候有更新大家也就收到通知了。 然后调用了ResponseConverter.getResults,将服务端的返回的ScanResponse转换为Result。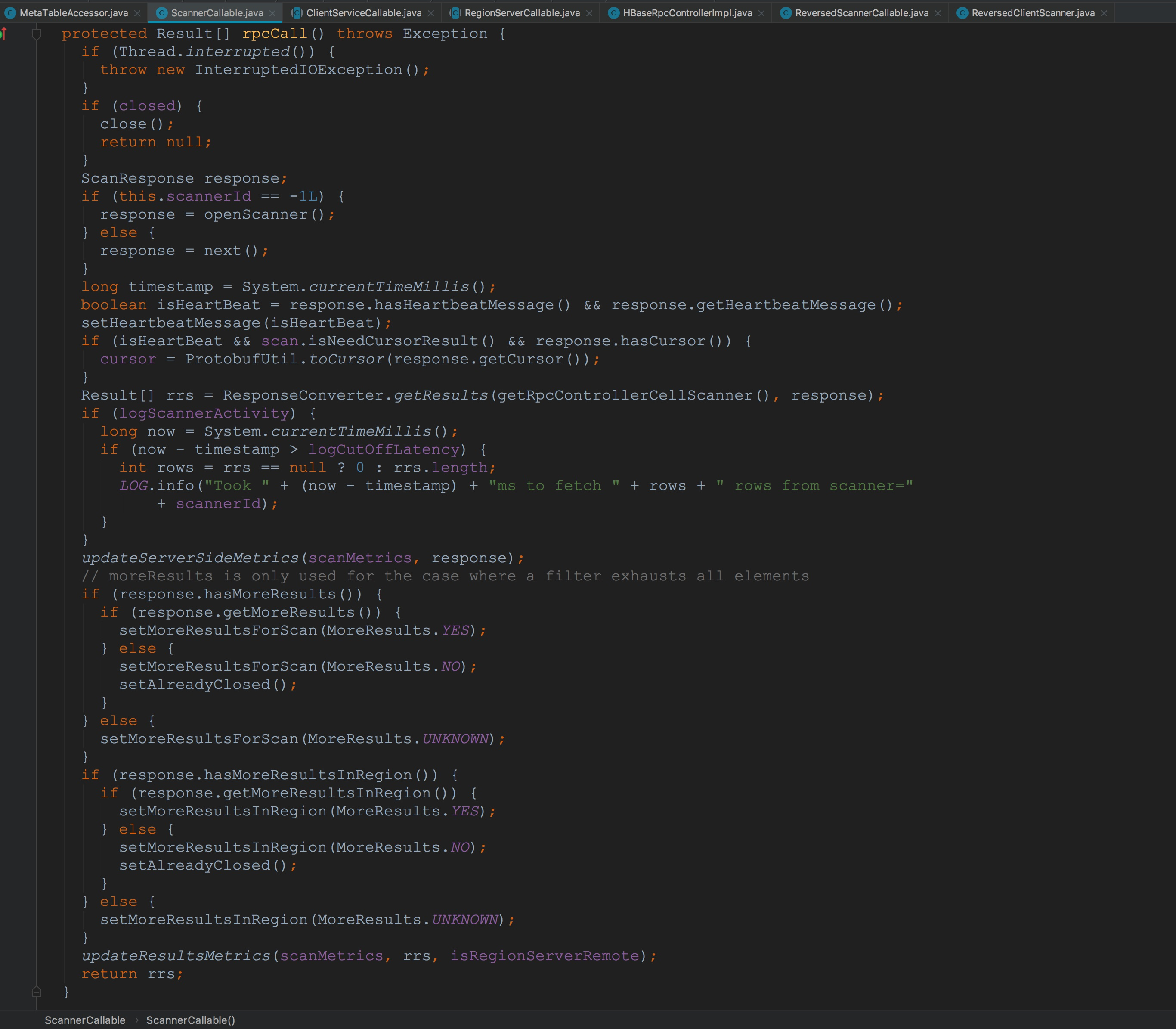 让我们来到ResponseConverter.getResults。这个方法的主要作用是将CellScanner中Cell的或ScanResponse中的PB类型的results转换为java类型的Result。至于该方法的详细描述我要放到后面开设的第二章节,也就是HBase中客户端协议各个操作中来讲解,因为这里流程是比较复杂的,要结合上服务端的流程才能讲述清楚。所以这里暂时略过。
让我们来到ResponseConverter.getResults。这个方法的主要作用是将CellScanner中Cell的或ScanResponse中的PB类型的results转换为java类型的Result。至于该方法的详细描述我要放到后面开设的第二章节,也就是HBase中客户端协议各个操作中来讲解,因为这里流程是比较复杂的,要结合上服务端的流程才能讲述清楚。所以这里暂时略过。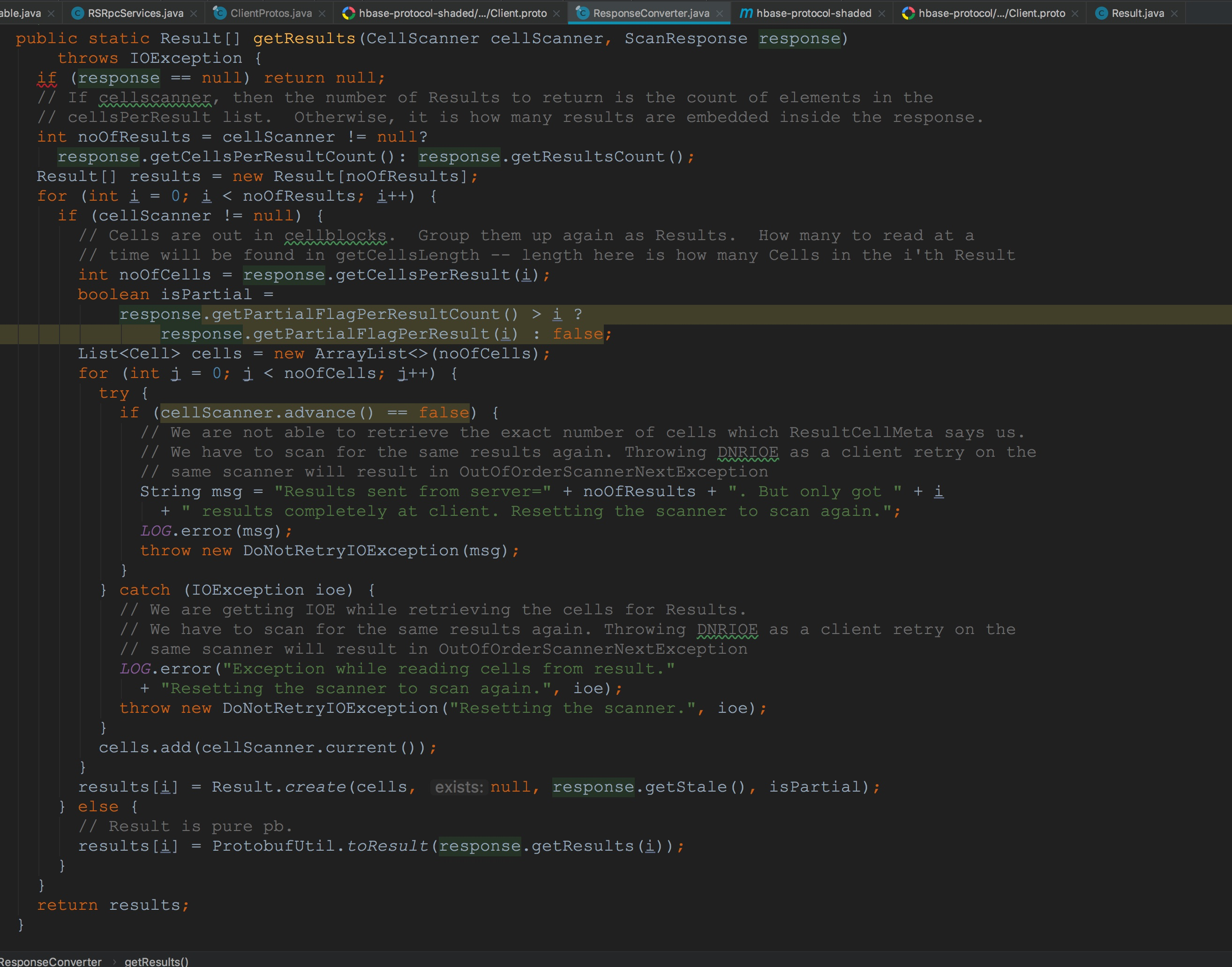 到这里,一个完整的RpcRetryingCallerImpl.callWithRetries方法调用流程可以说是完结了。然后在ResultBoundedCompletionService.QueueingFuture.run方法的后面,将当前QueueingFuture添加到ResultBoundedCompletionService成员变量completedTasks中(虽然我在上面提到过,但这里还是重述一下,以便我们后面的理解)。
到这里,一个完整的RpcRetryingCallerImpl.callWithRetries方法调用流程可以说是完结了。然后在ResultBoundedCompletionService.QueueingFuture.run方法的后面,将当前QueueingFuture添加到ResultBoundedCompletionService成员变量completedTasks中(虽然我在上面提到过,但这里还是重述一下,以便我们后面的理解)。
让我们来到ResponseConverter.getResults。这个方法的主要作用是将CellScanner中Cell的或ScanResponse中的PB类型的results转换为java类型的Result。至于该方法的详细描述我要放到后面开设的第二章节,也就是HBase中客户端协议各个操作中来讲解,因为这里流程是比较复杂的,要结合上服务端的流程才能讲述清楚。所以这里暂时略过。 到这里,一个完整的RpcRetryingCallerImpl.callWithRetries方法调用流程可以说是完结了。然后在ResultBoundedCompletionService.QueueingFuture.run方法的后面,将当前QueueingFuture添加到ResultBoundedCompletionService成员变量completedTasks中(虽然我在上面提到过,但这里还是重述一下,以便我们后面的理解)。 而在我们本节描述的整体流程中,ScannerCallableWithReplicas.addCallsForCurrentReplica方法调用完结。
接下来让我们来到ResultBoundedCompletionService.poll,由于其间接调用了ResultBoundedCompletionService.pollForSpecificCompletedTask,如下图所由于在QueueingFuture.run方法的最后,将自身添加到了completedTasks。因此,上面的方法获取的正是刚刚添加的QueueingFuture。接着调用了ResultBoundedCompletionService.QueueingFuture.get方法。如下图所示。也就是说,这里将result返回。这里result的类型我们需要注意一下,以便后面在类型上面的理解。由于这里QueueingFuture成员变量future的实际类型为ScannerCallableWithReplicas.RetryingRPC。大家可以往上翻到ScannerCallableWithReplicas.RetryingRPC.call,就可以发现,这里的result是从ResponseConverter.getResults获得的Result数组与成员变量callable封装后的Pair对象。接着,将r.getFirst(),也就是实际获得的结果返回。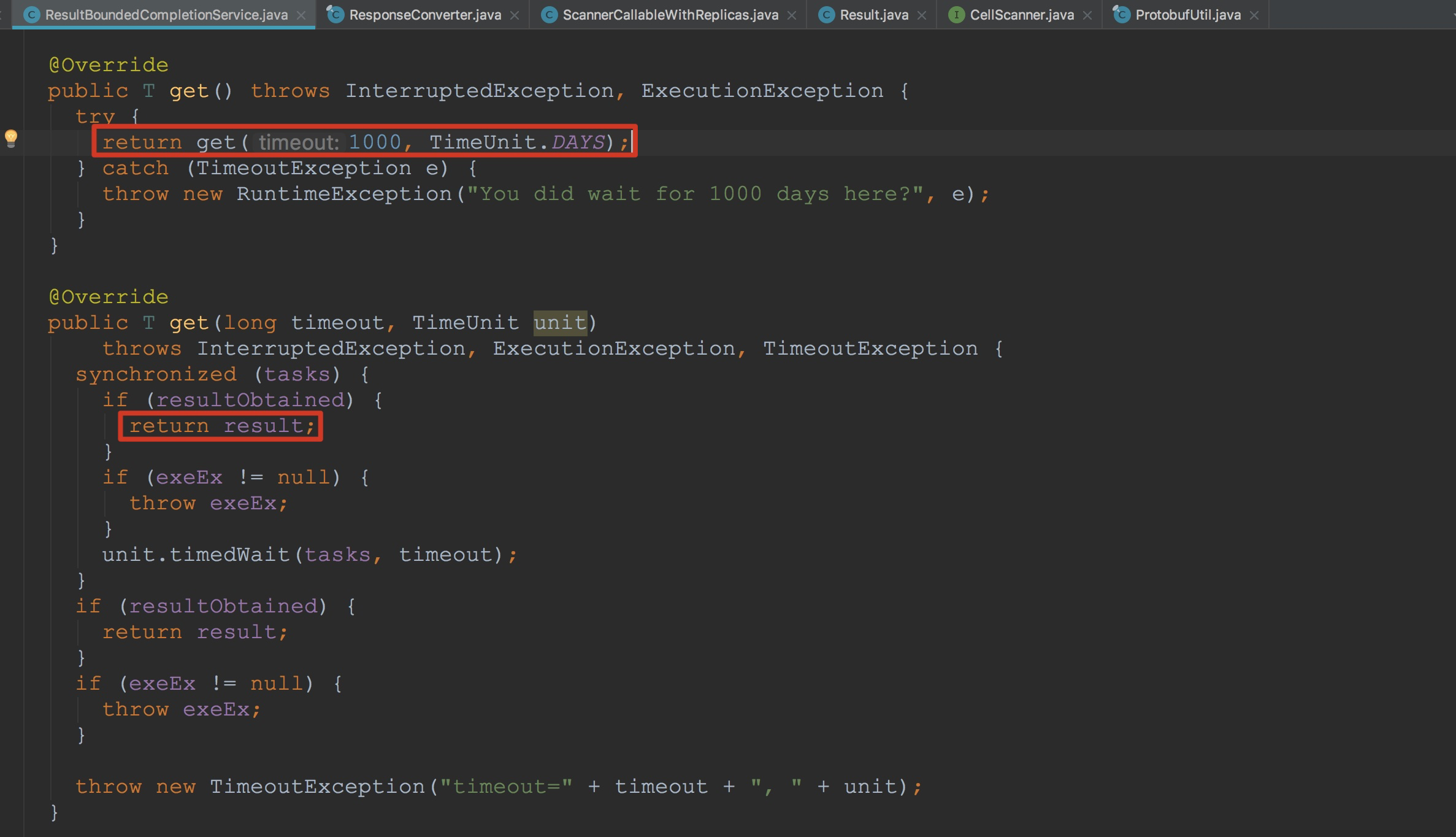
到这里,大家可能以为要结束了,很遗憾,这里只是到了ClientScanner.call方法的返回。
由于接下来的是两个单独的流程了。一个是MetaTableAccessor.getRegionLocations,另外一个是ConnectionImplementation.cacheLocation。至于这两个流程之外的后续流程比较简单,我就不一一叙述了,相信大家跟着源码与我在前面的提示很容易就可以弄清楚了。而前面提到的那两个单独的流程我将放在后面的一节《HBase之Table.put客户端流程(续)》中介绍。到时候欢迎大家阅读。
大家可以关注我的博客,或者发送邮件到我的邮箱15935152719@163.com来沟通交流大数据相关的知识。感谢大家的阅读,如果觉得不错,希望您可以点击下面的推荐。