转自:https://www.cnblogs.com/dtmobile-ksw/p/11988132.html
安装Flink standalone集群
1.下载flink https://flink.apache.org/downloads.html
2.官网参考 https://ci.apache.org/projects/flink/flink-docs-release-1.8/ops/deployment/cluster_setup.html
另外,如果已有hadoop平台,并且想使用flink读写hadoop上的数据,那要下载相对应的兼容hadoop的jar包

2.安装JDK8、配置ssh免密

3. 选择节点作为master(job manager)和slave(task manage)
比如这里有三个节点,其中10.0.0.1为master,其他两个为slaves,右边为相关配置应设置的内容

4.修改配置文件 flink-1.8.2/conf/flink-conf.yaml
相关的配置,端口号,内存根据实际配置调整,此外还可以在此文件中export JAVA_HOME=/path/to/you

jobmanager.rpc.address: master01.hadoop.xxx.cn # The RPC port where the JobManager is reachable. jobmanager.rpc.port: 6123 # The heap size for the JobManager JVM jobmanager.heap.size: 1024m # The heap size for the TaskManager JVM taskmanager.heap.size: 1024m # The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.每台机器可用的cpu数量,如果只是计算集群,16核的服务器可以配置14个,留2个给系统 taskmanager.numberOfTaskSlots: 1 # The parallelism used for programs that did not specify and other parallelism.默认情况下task的并行度 parallelism.default: 1
比较重要的配置参数(完整配置参数详解可参加官网链接):
the amount of available memory per JobManager (jobmanager.heap.mb), the amount of available memory per TaskManager (taskmanager.heap.mb), the number of available CPUs per machine (taskmanager.numberOfTaskSlots), the total number of CPUs in the cluster (parallelism.default) and the temporary directories (io.tmp.dirs)
5.修改配置文件 flink-1.8.2/conf/masters和slaves
masters文件:指定master所在节点以及端口号
master01.hadoop.xxx.cn:8081
slavers文件:指定slavers所在节点
worker01.hadoop.xxx.cn worker02.hadoop.xxx.cn
6. 分发flink包到各个节点
scp .....
7. 启动standalone集群
bin/start-cluster.sh
查看状态:
在master节点jps
50963 StandaloneSessionClusterEntrypoint
在work节点jps
3509 TaskManagerRunner
查看ui界面
http://master01.hadoop.xxx.cn:8081
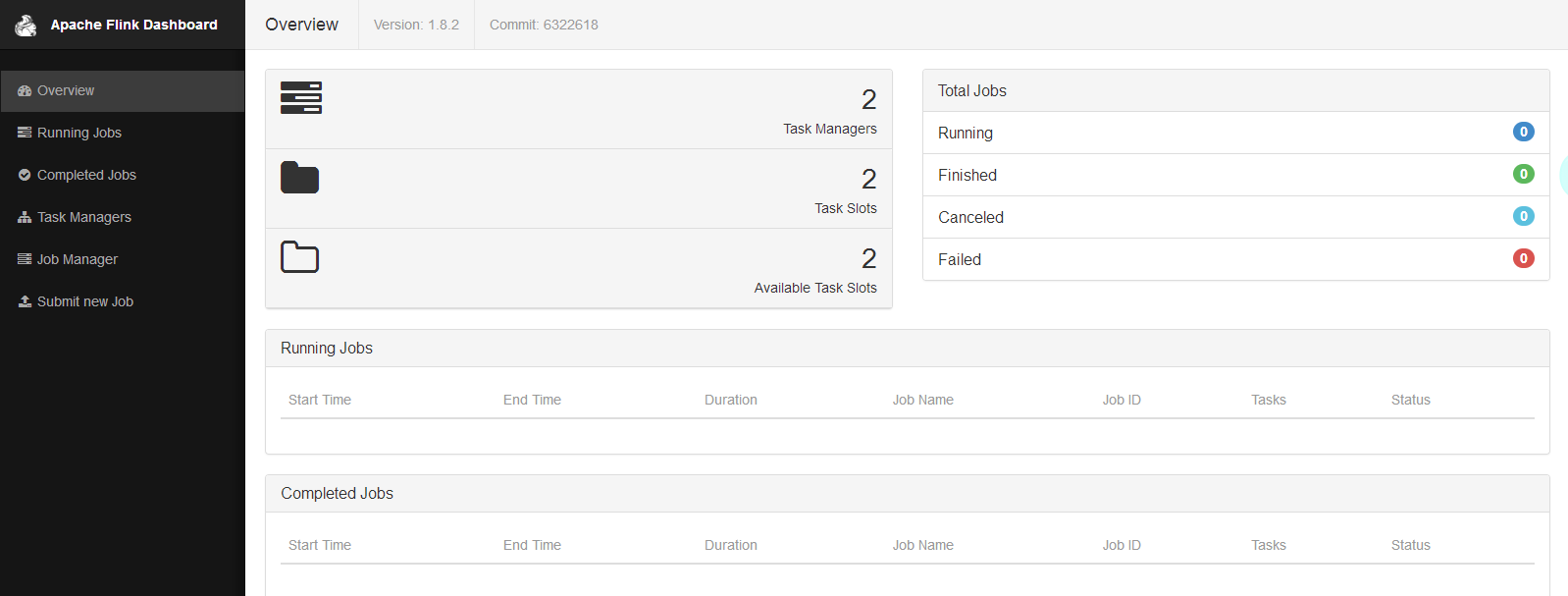
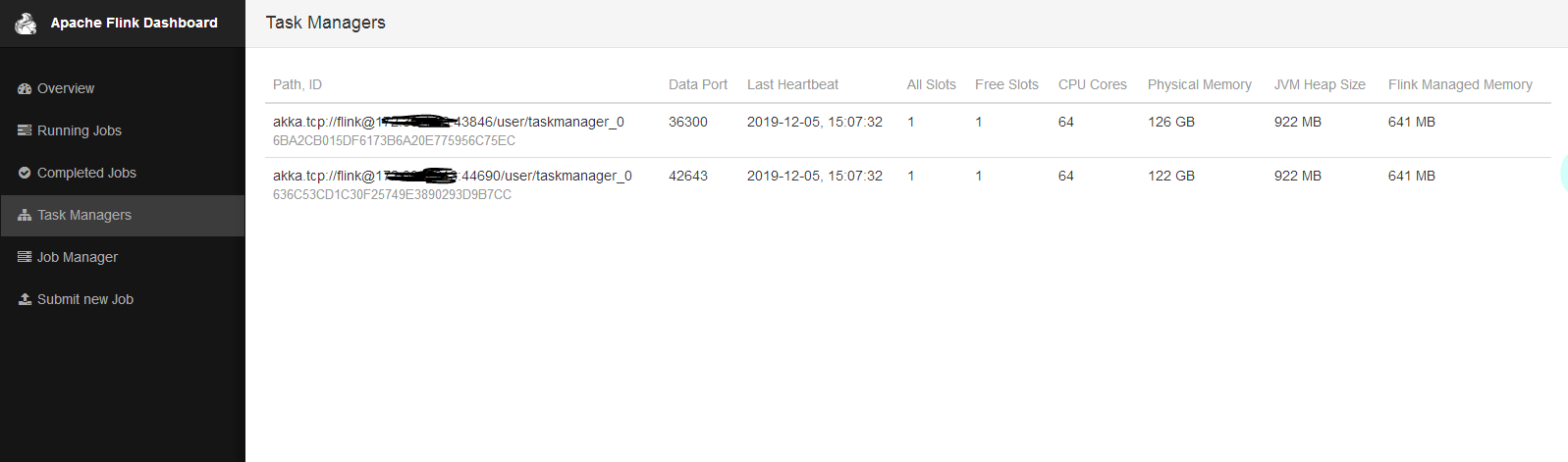
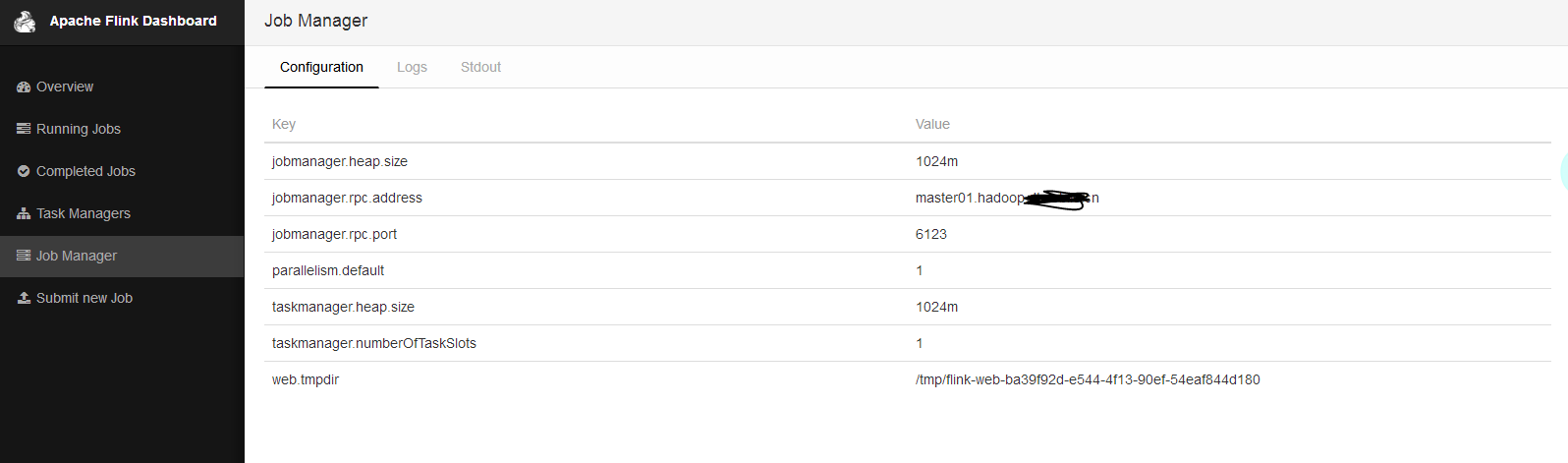
运行flink自带的wordcount例子
nc -l 9999
bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname 172.xx.xx.xxx --port 9999
界面:
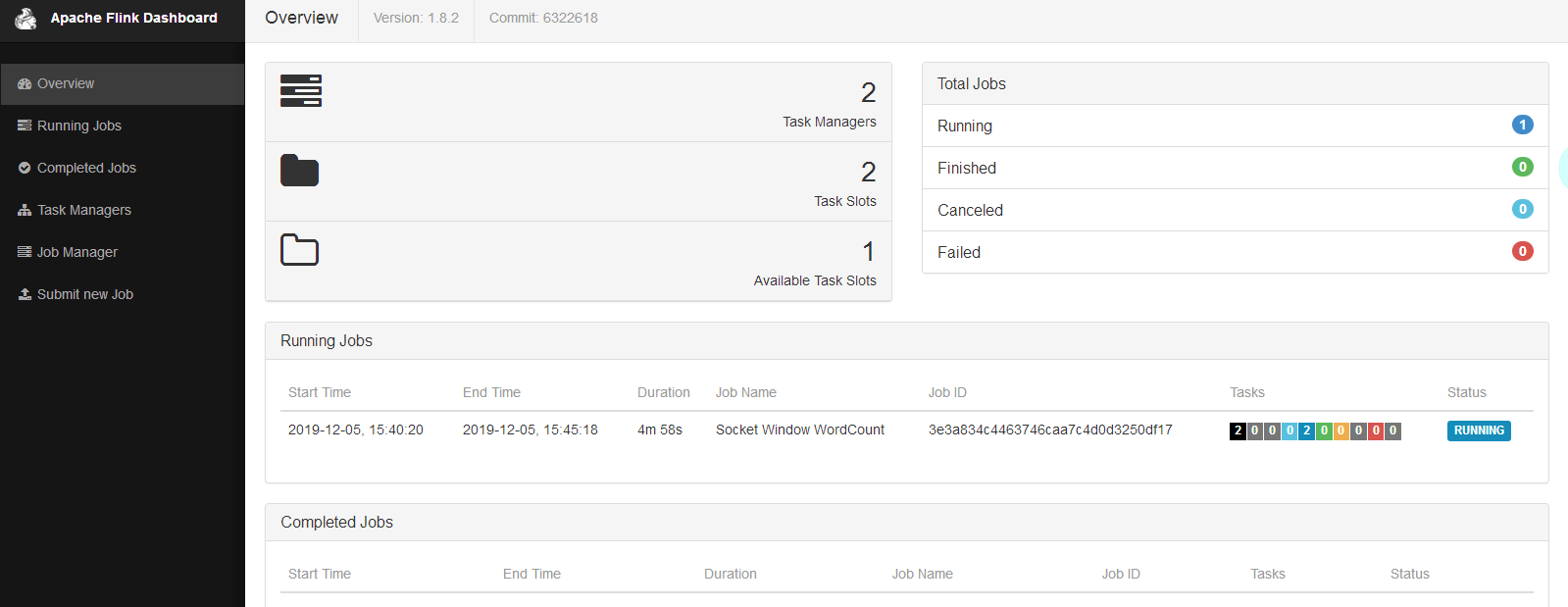
flink standalone集群中job的容错
1.jobmanager挂掉的话,正在执行的任务会失败,所以jobmanager应该做HA。
2.taskmanager挂掉的话,如果有多余的taskmanager节点,flink会自动把任务调度到其他节点上执行。