一、OOP和GP的区别(video7)
OOP:面向对象编程(Object-Oriented programming)
GP:泛化编程(Generic programming)
对于OOP来说,我们要实现容器,应该是这样的:

将数据和方法关联在一起,例如排序,用成员方法的方式将其放在容器类中。
对于GP来说,我们将数据和方法分开:

如图中所示,左边是容器的定义,而右边是sort算法的定义。我们用::sort(c.begin(),c.end())就可以调用全局的sort算法,参数代表数据的存放范围(首尾的迭代器来指明范围)。
采用GP有什么好处:
- Containers和Algorithms团队可各自闭门造车,他们之间以Iterator沟通即可。
- Algorithms通过Iterators确定操作范围,并通过Iterators取用Container元素。
例如:
简单的算法,比大小函数min和max:

min和max接受两个对象的引用,然后使用“<”和“>”来比较大小,这是算法团队实现的。但是至于如何比对,就需要由数据团队自己来实现,例如比较两个石头(stone)的大小,是比较直径呢还是比较重量,这不是算法团队关心的。
对于某些容器,可能并不适合使用全局算法,例如list容器:

list容器不能采用全局的sort来进行排序,这是为什么?因为全局的sort方法,要正确使用,对迭代器有一定的要求,必须要求迭代器是随机访问迭代器(Random Access Iterator),但是list的node在内存中是离散分布的(用指针链接起来),所以他的迭代器不满足随机访问这个需求,所以list自己提供了成员方法sort(),那么我们要对list排序,就要使用它自己的sort()。
能够使用全局::sort()的容器有array、deque、vector等内存是连续分配的容器。
标准库提供的不同版本的算法:
max函数,标准库提供了两种版本:

第一种版本是利用类的操作符重载来完成大小的比对,但如果比对的是语言本身带的类型,可能只提供了一个默认的比较方式,例如string默认是按字符一个一个比对的。可能不能满足我们的个性化需求。
第二种版本的参数除了提供要比对的数据,还可以提供一个方法,这个方法我们可以自定义如何比对数据,例如我们可以比对string的长度。
二、分配器Allocator(video11)
了解operator new、operator delete、malloc、free:

在VC6.0里,operator new的实现如图中所示,底层是调用的malloc。而malloc分配的内存如图中右边所示,详细解释可参照 C++程序设计1(侯捷video 7-13)中的第五节。
在VC6.0中,标准库提供的容器所使用的默认Allocator都是出于头文件<xmemory>中的allocator。如图:

VC6.0中Allocator是怎么工作的:
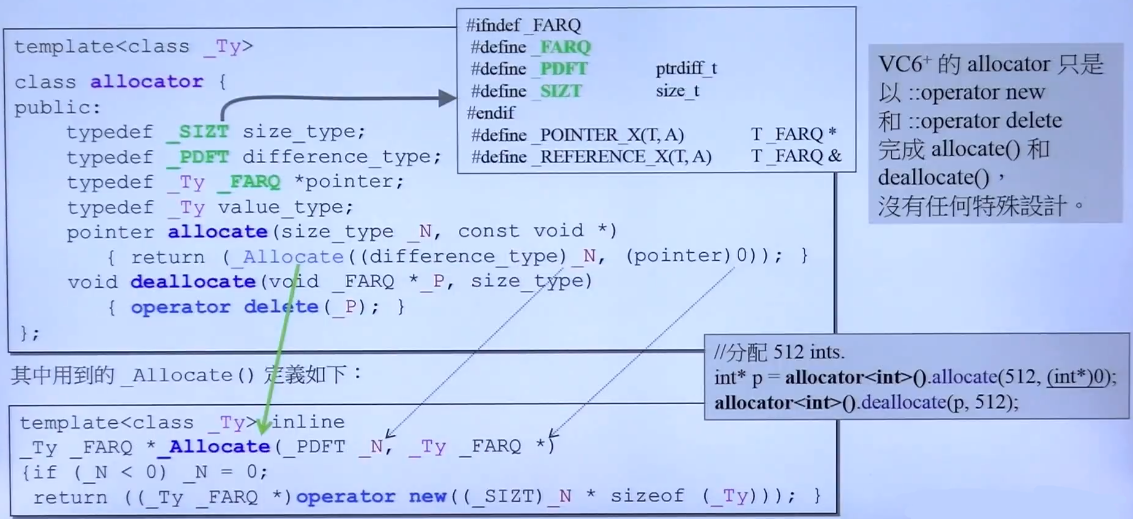
allocator类中最重要的就是allocate()方法和deallocato()方法。
在allocate()方法中,使用的是operator new来进行内存分配,而我们知道operator new的底层是使用的malloc,所以内存的分配流程就比较清晰了。
图中,右边部分有一个书写代码的技巧:

使用allocator<int>()可以产生一个临时的allocator对象,然后直接调用allocate来分配512个字节的空间。第二个参数是什么呢,注意,在allocate成员方法的定义中,第二个参数只有类型,而没有形参名,这就说明这个参数不会被使用,他是利用这个参数来获取需要分配的数据类型(不深入探讨)。
除了VC6.0,在BC++5中同样是这种结构:
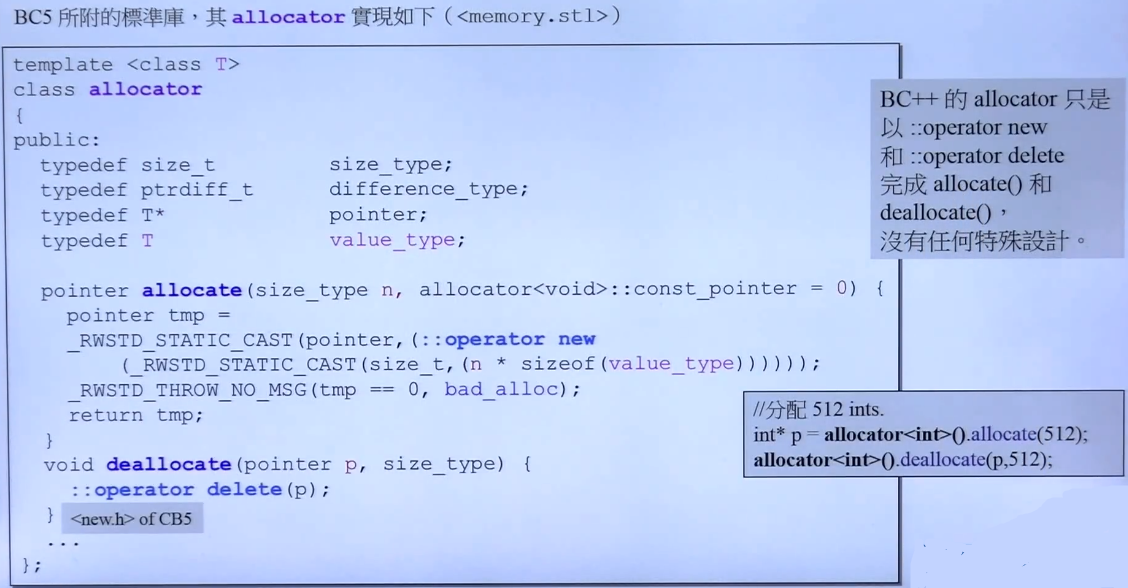
从这个图可以看出deallocate的实现方式,就是调用operator delete。然后operator delete再调用free来释放内存。
但是在deallocate的实现中,参数需要指明归还内存的大小,这就是为什么不建议直接使用分配器来申请内存的原因,allocator和deallocator是提供给容器实现用的,而不是为了提供给用户使用的。
再看GNU C2.9的allocator实现:

在GNU C的实现中,同样采用了一样的方法来实现,但是右下角的说明表示:
GNU C虽然实现了标准库规定的默认allocator,但是并未在任何的容器中将其运行为默认分配器。
为什么不用这种allocator呢?
因为我们在实际应用中,所需要分配的空间一般都是比较小的,那么就一定对应大量的allocate调用(也就对应malloc调用次数),每次malloc分配的空间都有额外开销(参照 C++程序设计1(侯捷video 7-13)中的第五节 ),当需要的空间小时,额外空间占的比例就大,所以我们需要尽量减少分配的次数。
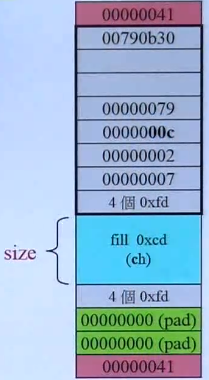
额外开销:
Debug模式下,额外开销就是除蓝色部分以外的所有(包含红色、灰色和绿色部分)。
Release模式下,额外开销就是红色部分(cookie)。cookie是用来供malloc记录分配内存的代销的,使用free释放时就不要指定大小了。
在GNU C中有另外一种更好的默认Allocator,供容器作为默认选项:
这种叫做alloc的分配器尽量减少malloc的调用,避免cookie占太多额外空间。计算一下,当分配100W个空间时,可以节省100W*8=800Wbytes的空间,也就是8MB的空间。那么如果是10亿呢,那就大约是8GB的内存空间。(当然,这里计算的节省值只是一个直观的表现,实际并不会节省这么多,因为alloc毕竟还是需要使用malloc来拿内存,只是次数相对少一些)
alloc的实现流程简介:
如图所示,alloc中维护了一个长度为16的数组,该数组中放了16个指针,每个指针都指向一块内存区域(这个内存区域也是使用malloc拿到的,当然也带cookie)。在这个数组中,每个指针所指向内存的单位大小是不同的,例如#0指向的内存块大小都是8bytes,#1指向的都是16bytes,以此类推,#15指针指向的是128bytes。当一个容器需要申请内存时,alloc会根据容器所需存放的数据类型来决定从哪一个指针指向的内存块中来分配,当然,数据类型的大小需要调整为8的倍数。例如容器需要的类型大小为50,alloc会选择#7号指针指向的内存中来分配。
从上面的工作过程中可以看出alloc有一定的优点,但肯定也有一定的缺点。比如什么时候使用free来归还指针指向的一大块内存。比如容器释放内存后,这块内存是否立即free,还是保留在alloc中供下次分配。比如,当容器需要的内存大于alloc现在拥有的内存块,alloc是重新申请更大的块,还是采用何种机制扩充。(这些我们内存管理中来剖析)
上面所述的这种比较好的alloc实在GNU C2.9版本中作为默认allocator的,但到了4.9版本,他的默认allocator又用回了标准库规定的allocator(也就是和VC6.0、BC++5中一样的实现)。具体原因不得而知,在GNU C4.9版本中allocator的标准实现在new_allocator中。如图所示:

那么在2.9版本中作为默认使用的alloc还在不在呢?答案是还在,只是将其改为_gnu_cxx::__pool_alloc(观察其工作过程,有内存池的感觉)。
我们可以在今后的使用中,自己制定使用这个__pool_alloc,具体使用方法,在前面的章节中已经示范过,可以自行参考。
三、容器之间的关系(video12)
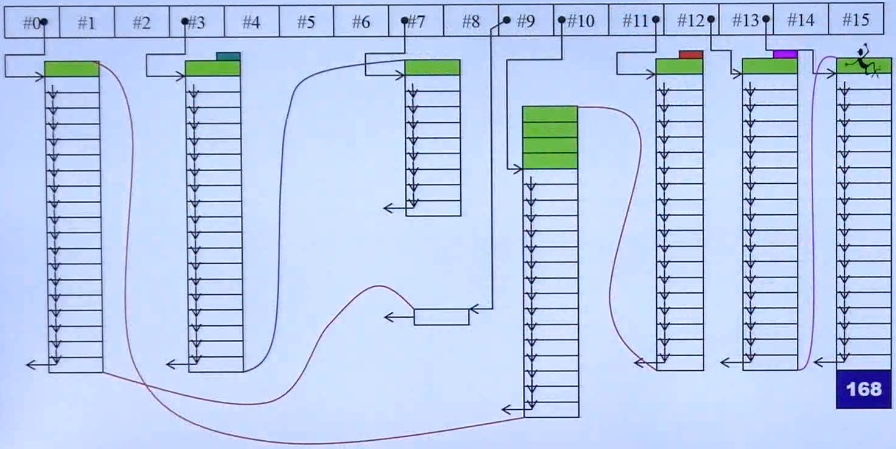
在STL提供的如此丰富的容器之间是否存在一定的联系,如下图所示:

解释:
1.上图所述内容是基于GNU C2.91版本。
2.缩进表示复合关系,而不是继承关系,例如set和map中包含有rb-tree,stack和queue中包含一个deque。
3.非标准的意思是在C++1.0的时候未纳入标准库。例如slist、hash_**。
4.图的下方描述了C++11中对标准库容器的改变,一些非标容器转正,并新增array。
5.左右两边的蓝色框中的数字表示在GNU C2.9和4.9版本下,容器本身所占大小的比对。容器本身所占大小的意思是不包含容器中存放数据的空间,而仅指自己用于控制或其他功能所消耗的空间。
四、深度探索list容器(video13)
在GNU C2.9版本中,list容器如下图所示:
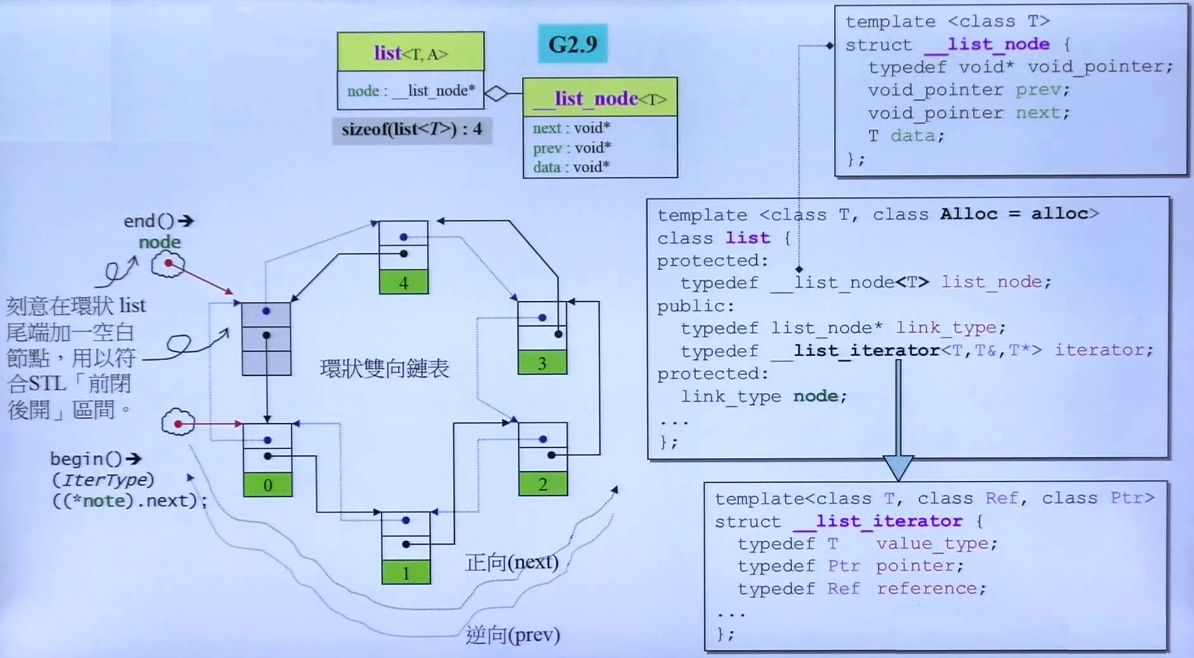
解释:
1.标准库中的list容器是一个双向环状链表。
2.list的定义中只有一个成员变量,就是node,类型是link_type,实际就是__list_node*。
3.__list_node的结构如图右上角所示,除了包含一个数据意外,还有指向前一个node的指针,以及指向后一个node的指针。但在2.9版本中,设计得不够好,他使用了void指针,按理说应该使用__list_node*会更好。
4.list的定义中还有begin()、end()等可以获取Iterator的方法,list搭配使用的Iterator是定义在全局中的__list_iterator,这个迭代器应该重载“++”、“--”等指针常用的操作符,但由于list的内存分布是离散的,所以这里的“++”操作符必须实现得更聪明,调用iterator++的时候,iterator应该指向下一个node的指针(其实就是检查本节点的next指针)。
5.在__list_interator的结构体实现中,模板传入了三个参数T、T&、T*,实际上只需要传入一个T就可以了,引用和指针都可以在使用的时候再定义,没必要通过参数传入。后面我们可以看到,在4.9版本有所改善。
6.由于标准库提供的list是一个环状双向链表,为了实现前闭后开区间的规定,所以最后一个node是一个空白节点,如图中左边文字描述,我们使用begin()获取链表首个节点地址,使用end()获取最后一个非空节点的下一个节点地址(空白节点地址)。
__list_iterator的实现:

上图中对“++”的重载有两个方法,分别为前++(prefix)和后++(postfix):

解释:
1.为了区分前++和后++两种重载,使用一个int参数才区分。不带int参数的是前++,带int参数的是后++。
2.前++是比较好理解的,先取到本节点的next指针,并赋值给node。在返回自己的引用,可以前++是可以连续使用的,例如++++i。
3.后++不是很好理解,后++的意思是先保留目前的数据,然后再实现+1。所以第一步就是将当前状态的自己记住,使用self tmp = *this,这里的*this并不会调用重载后的“*”(获取节点中data的指针),而是因为“=”已经被重载过,现在是拷贝构造的作用,所以*this会被解释为迭代器构造函数的参数,所以取得是当前的自己,然后拷贝构造了一份tmp。
4.然后调用++*this,使用已经重载的前++,让node指向下一个节点(next)。
5.最后返回tmp对象。为什么这里返回的不是引用(前++返回的是引用),是因为为了迎合C++中后++不能连续使用的
规定或习惯。也就是不能使用i++++这种方式,如图中左下角,我们已整数为标准,整数不支持的操作符功能,我们也遵循其规格。
__list_iterator迭代器对“*”和“->”的重载:
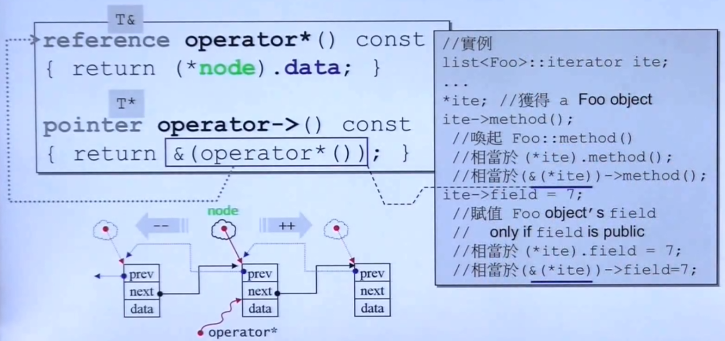
“*”和“->”的重载比较简单,分别返回里面存放数据data的引用和指针。
__list_iterator在GNU C2.9和4.9的不同:
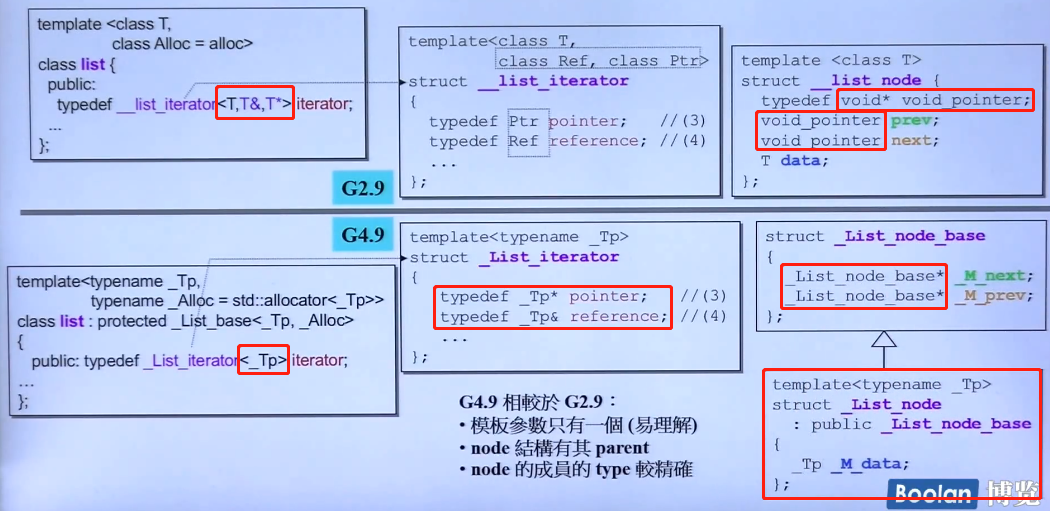
解释:
1.在2.9版本中出现的同时传入T、T&和T*的问题得到了改善,4.9中只传入一个_Tp,然后在内部进行typedef。
2.在2.9版本的__list_node定义中出现的void指针也得到了改善,替换成了_list_node的父类指针。当然,__list_node也变为了有有继承关系的_List_node和_List_node_base。
五、Iterator Traits萃取机(video15)
Traits的概念比较抽象,我们一步一步来引导出这个概念。
前面我们看到标准库在__list_iterator的定义中,使用了多个typedef,如图所示:

这些typedef到底有什么用呢?
这里的typedef所定义的类型,例如iterator_category、value_type、pointer、reference和difference_type,他表示了一个Iterator的属性。比如有些容器需要双向可移动的迭代器(实现了++和--),有些容器只需要单向移动的迭代器,还有些容器的迭代器支持多步跳着走,那么这些迭代器就可以通过typedef定义iterator_category来分类。当算法要通过迭代器作用于这个容器数据时,就可以通过这个iterator_category询问迭代器他所属的类型。
例如上图中,这个迭代器是bidirectional_iterator_tag,表示双向迭代器。
上述的五种类型,就是C++标准库所规定和设计出的5种算法提问。
我们看下面这张图:

解释:
1.图中的iterator_category就是迭代器的类型。
2.value_type顾名思义就是迭代器指向数据的类型。
3.pointer和reference就是value_type的指针和引用。
4.difference_type就是一个用于描述两个迭代器之间距离大小的类型,例如两个迭代器相差100W个数据,那么difference_type这个类型必须要能够支持100W这么大的数据,比如int。更大的话可能就需要long。在标准库中,选择的是ptrdiff_t这个类型,具体是什么需要查看源代码。
5.图右边的算法可以直接通过I::iterator_category来获得他想问的结果。
6.但是,我们使用标准库提供的算法,不是一定会传给他迭代器,也有可能会传给他一个原始的指针,但是原始的指针内部没有定义这些类型(问题的答案)。所以我们要引入Traits。
什么是Traits?如下图所示:
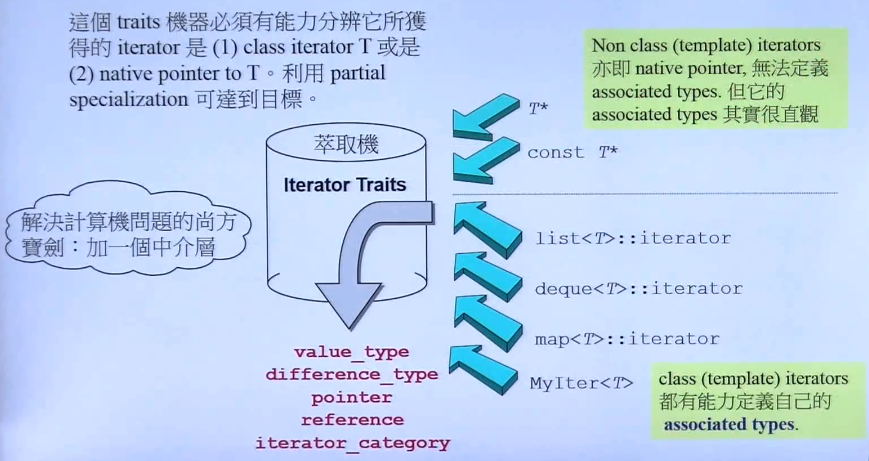
Traits要能够区分class iterators和non-class iterators。
Traits是如何实现的:

解释:
1.当算法想要询问value_type时,会通过iterator_traits中转。
2.如果算法要问的东西是一个迭代器,那么会通过iterator_traits的泛化定义(图中的黑一)。
3.如果算法要问的东西是一个指针,那么会通过iterator_traits的范围特化定义(图中的黑二)。
4.如果算法要问的东西是一个常量指针,那么会通过iterator_traits的范围特化定义(图中的黑三),注意这里返回的是T而不是const T,见图中右边黄色框的解释。
5.这里只展示了value_type,其他4个问题,也是一样的。
完整的iterator_traits:

Traits的简单总结:
Traits是一个算法与迭代器(或指针)之间的中间层,当算法需要询问问题的时候,如果询问对象是指针,那么由Traits来代替其回答。如果询问对象是迭代器,那么就由Traits帮算法询问,并返回答案。
其他的一些Traits:

六、深度探索Vector容器(video16)
Vector是一个可以动态扩展容量的数组(始终是连续空间)。但是,没有什么东西可以在原地扩充内存,所以在vector中,当空间不足时,会从内存中找到另外一块2倍大的空间,然后把原来的数据都搬过去,从而实现空间的扩充。如图:

如图中左边所示,空间仅剩两个单位,但要存放一个占用三个单位的数据。vector找到另外一个2倍大的空间,然后将原本的数据搬进去,再存放新的数据。
代码解释:
1.vector通过三根指针来控制空间和数据,start、finish和end_of_storage。分别对应左图中的位置。
2.begin()返回start,end()返回finish,满足前闭后开的规范。
3.size()返回目前数据所占空间的大小,capacity()返回vector目前总共可用空间大小。
4.empty()返回vector是否为空,用begin()==end()来判断是否有数据。
5.提供operator [],[]中可以传入index。
6.front()和back()分别返回第一个元素和最后一个元素的迭代器。
vector的基本实现:
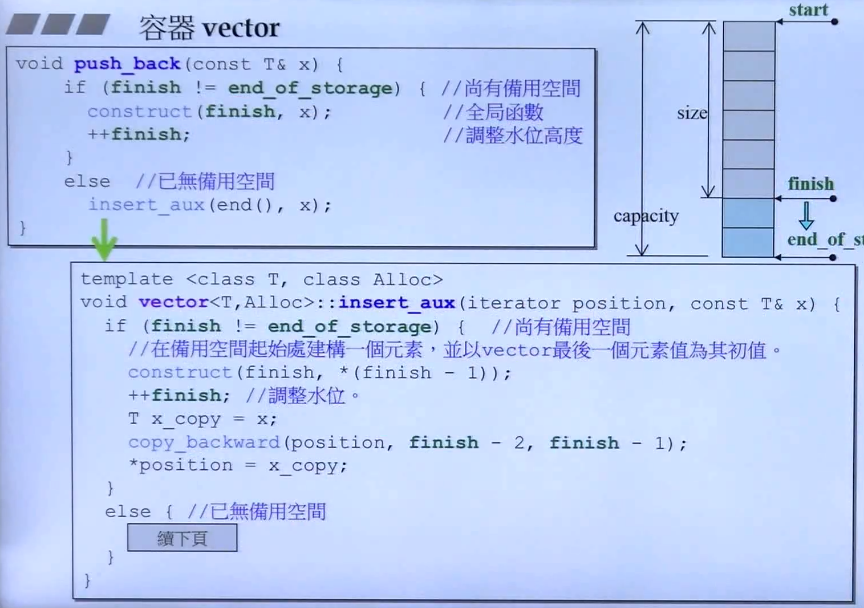

解释:
1.调用push_back()的时候(调用insert()的时候也一样),检查空间是否足够,如果足够就放入x,然后调整finish的位置。
2.如果空间不够,则调用insert_aux(),在insert_aux()中再次检查是否还有空间,这里的再次检测主要是提供给其他函数调用的,例如insert()函数,所以我们可以看到,在检测到有空间的时候,将position这个位置(insert插入点)的后面所有数据全部朝后移动了一格。最后在position的地方放入x。
3.如果在insert_aux()中检测到没有空间了,那么就需要扩充空间。见第二个图。
4.先记住旧的size,然后判断size是否为0,如果不为0,则扩充为2倍,新size为len。
5.新申请一个长度为len的空间,将其头指针赋值给new_start。
6.然后开始拷贝旧的数据到新的空间中,这里也是为了兼容insert,所以先拷贝的position之前的,然后插入x,再拷贝position之后的数据。
7.数据全部拷贝完后,使用destroy()释放旧空间。
8.最后调整start、finish以及end_of_storage的指针位置。
vector iterator中的traits:
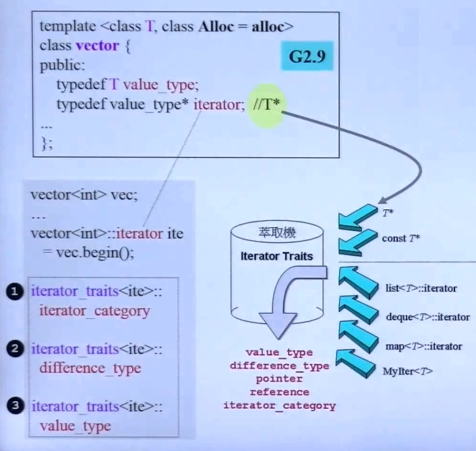
工作过程和list差不多,可以参考list的traits原理。
七、深度探索Array容器(video17)
为了让普通的数组也能享受标准库带来的优秀的算法等功能,在C++2.0版本中,把数组做了封装的,产生了容器array。

在array的TR1版本(technology reportor 1,是一个C++1.0和C++2.0之间的过度版本)中,array设计的结构是比较简单的。
解释:
1._M_instance就是内部的数组,类型就是_Tp,也就是定义array时元素类型模板参数。
2._Nm是定义array时给定的大小,当_Nm为0时,内部的数组的size定义为1,因为不存在size为0的数组。当_Nm不为0的时候,则size为_Nm。
3.同样实现一堆操作函数,都是模拟普通数组的。
4.array的迭代器,直接使用指针来代替,所以算法询问问题得时候,Traits代替指针进行回答(参考list traits解释)。
在GNU C4.9版本中,array的设计结构复杂了很多,没有太多参考价值,因为不懂实现团队的远期目标,不知道为什么要搞那么复杂。
八、深度探索deque容器(video18)
deque是双向队列,即前后都可以扩展空间,他的实现方式是比较复杂的一种。如图所示:
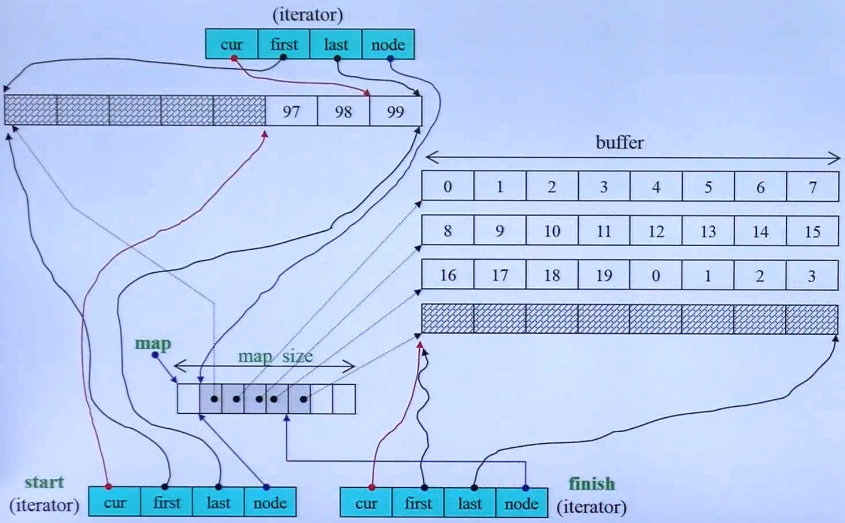
解释:
1.deque又一个控制中心和多个内存块组成,控制中心是一个vector,里面按顺序存放每个内存块的地址。又这些地址串联起来形成整个deque的空间。并且面向用户展现的是类似连续空间的表征。
2.deque的iterator结构如图所示,由4个指针组成,cur表示当前数据的位置,也就是其他iterator中数据指针的位置。first表示iterator所在的当前内存块的首地址,last表示当前内存块的尾地址。最重要的是node,node指向控制中心存放当前内存块地址的那一格的指针,也就是通过node,iterator知道自己所处在哪个内存块。
3.向后扩展:当iterator的node指向的是控制中心中最后一个内存块的指针,当cur==last时,就需要向后扩展内存了。此时,会新申请一块内存块,并将内存块的地址存放到控制中心的最后面,然后该iterator的node向后移一格,然后first为当前新内存块的首地址,last为新内存的最后,然后cur调整为等于first,再写入数据。
4.向前扩展:当iterator的node指向的是控制中心中第一个内存块的指针格,此时,当cur=first时,就需要向前扩展内存了,新申请一块内存,将内存块的地址插入到控制中心的最前面,然后该iterator的node指向新内存的指针格,将first调整为新内存的首地址,last为新内存的尾地址,cur调整为等于last,然后再last-1放入数据。
deque具体实现代码:

解释:
1.deque定义中有4个成员属性,start表示处于第一块内存块的iterator,其中的cur指向第一个数据。
2.finish表示处于最后一个内存块的iterator,其中的cur指向最后一个数据。
3.map指向控制中心的vector,他的类型是T**,T是模板参数,表示deque中数据的类型,比如int。map中存放的是指向内存块的指针,在这里就是int*类型。然后map又是指向vector的指针,vector中存放的是int*,所以map就是int**,也就是T**。map占用大小为4bytes。
4.map_size表示控制中心vector的大小。map_size占用大小为4bytes。
5.deque带3个模板参数,第一个是数据类型,第二个是分配器,第三个是每个内存块的大小,默认为0。具体为多少,参照图中灰色框里的说明。(新版本的deque实现貌似不允许用户指定内存块大小)
deque iterator实现:

解释:
1.iterator中也有4个属性,cur表示当前指向的数据位置。所占大小为4bytes。
2.first指向的是该iterator当前所处内存块的首地址。所占大小为4bytes。
3.last指向的是该iterator当前所处内存块的尾地址。所占大小为4bytes。
4.node指向的是控制中心map中它目前所在内存块对应的指针块,类型是T**。node所占大小为4bytes。
5.所以,一个deque iterator所占的空间为16bytes。
6.我们可以推出,定义一个空的deque,他自身所占空间大小为两个iterator的大小加上控制器指针的大小,再加上控制器vector的map_size大小,一共是40bytes。
7.iterator要提供给算法使用,必须满足traits要求,也即定义5种类型。在deque的iterator中,iterator_category是random_access_iterator_tag,因为deque对外宣称他的内存是连续的(实际上是分散的),iterator也提供了“++”“--”等random access的操作。
deque的insert操作:


解释:
1.首先两个判断,是否在deque的最前段或是最后段,如果是,那就直接插入就好了。
2.如果不是,交给insert_aux()函数处理。
3.计算插入的位置离deque的头近还是尾近。离哪边近,数据就往哪边推。
4.确定往哪边推后,就开始搬移数据,以离头近为例。先在最前面加一个元素,值等于现在的第一个数据,然后依次将后面的数据向前挪一个位置,将需要insert的位置腾出来。然后再插入值x。往后推同理。
deque是如何实现空间连续的假象:
主要是通过operator的重载来实现的,当我们使用“++”或“--”这些指针操作时,内部实现应该是能够自动的在不同的内存块之间切换,形成内存地址连续的假象。
具体实现参照video19。
九、深度探索stack和queue(video19)
stack和queue都默认使用deque作为底层结构。
例如queue:

queue使用Sequence模板参数,默认选择就是deque作为底层结构,queue中所有的方法实现,都是通过deque来实现的。stack也是同理。
stack和queue也可以选择其他的容器作为底层结构,例如list等。只要选择的容器支持上图中被调用的方法,就可以作为底层结构。但是默认采用的deque应该效率最高的。

注意:
queue不能选择vector作为底层结构,而stack可以采用vector作为底层结构。
queue和stack都不可以选用set和map作为底层结构。
stack和queue都不提供遍历功能,也不提供iterator:

十、RB-TREE红黑树(video20)
红黑树的一些特性:
1.是平衡二叉搜索树,不会出现一条臂很深的情况,可以保证查询效率
2.可以支持遍历操作以及iterators,按正常情况遍历出的结果是有序的
3.尽量不要修改元素的值,因为值被修改了,树的机构会改变,而改变的效率是比较低的(在编程层面并不拒绝这个操作,只是不推荐),在set中最好不要修改值,而在map中,可以修改value的值,但最好不要修改key的值。
4.红黑树提供两种插入,一种是key不重复的insert_unique(),一种是可以重复的insert_equal()。
红黑树代码简要介绍:
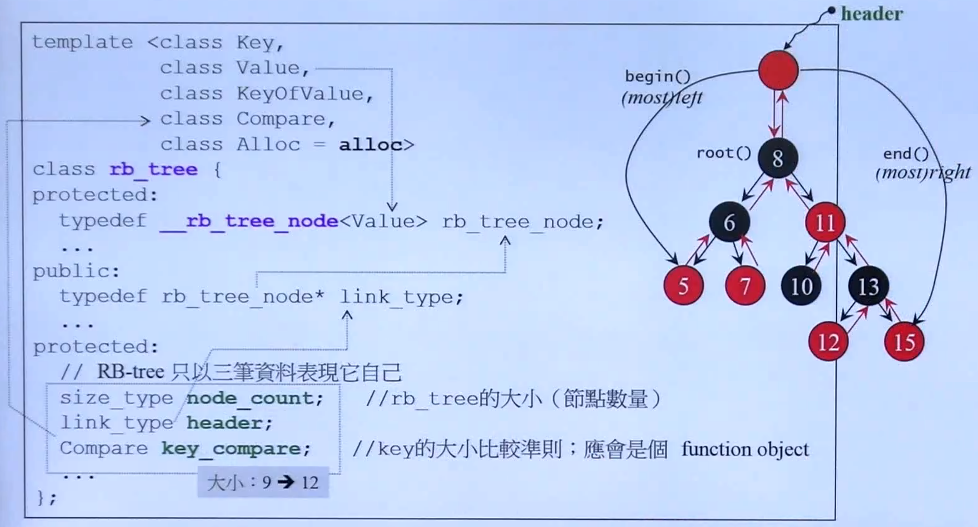
解释:
1.红黑树的实现要传入5个模板参数,第一个是node中key的类型,例如int。第二个Value,并不是我们想象中key:value中的value,这里的value是指key:data的组合。第三个参数KeyOfValue是提供一个函数,告诉他如何从Value组合中获得key。第四个参数Compare是告诉他如何比较key的大小。第五个参数是分配器。
2.rb_tree中的数据部分:node_count用来记录树种一共有多少个节点。header是一个空的节点,从这里开始访问树,有这个header,也方便代码的设计。key_compare是比大小的一个函数。
3.在GNU C++2.9版本中,一个rb-tree的大小为9字节,其中node_count占4bytes,header是一个指针,也占4bytes,key_compare是一个函数,大小应该是0,但编译器都会将其变为1byte。加起来一共是9bytes。
如何直接使用标准库中的rb-tree:
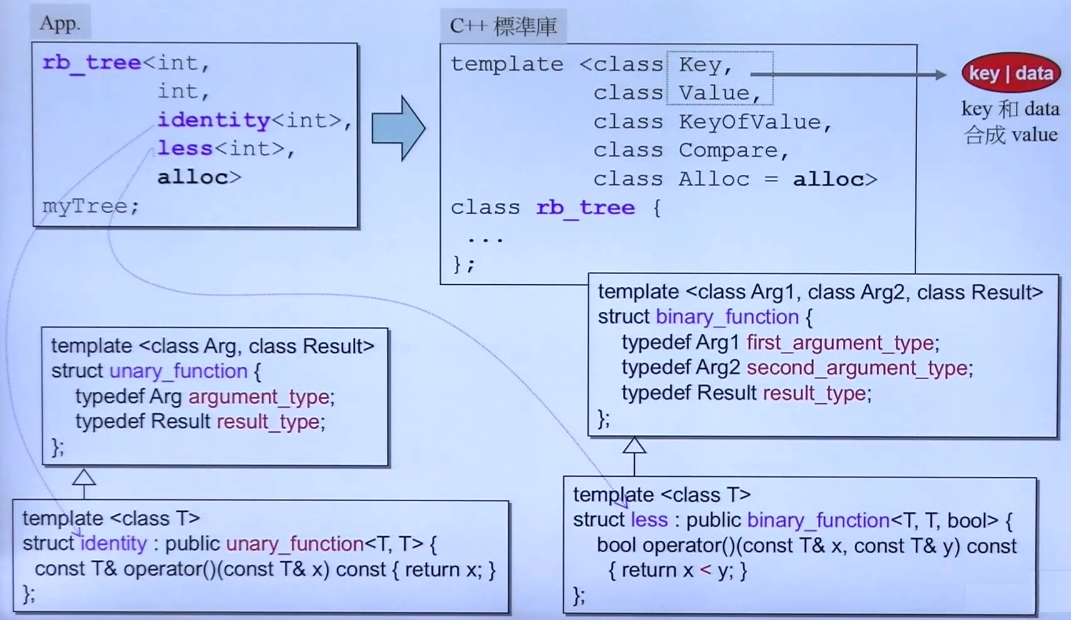
解释:
1.传入key的类型为int,value的类型为int,表示key和value是同一个,也就是set。KeyOfValue,传入的是identity<int>类,实际上是一个仿函数。compare传入的是less<int>,这是标准库提供的,也是作为一个仿函数。
2.在identity类中,实现了operator(),就相当于把该类变为了一个仿函数,而这个函数就是将参数返回出去,也就是说明从value里获取key的方法,value就是key。
3.less类中,也实现了operator(),这是使用小于符号比较大小,可以用来比较int。
4.identity和less类都继承了父类,而父类里只有类型定义,这在标准库中叫做可适配的,不用深究。
以下是在GC++2.9中使用rb-tree的代码:
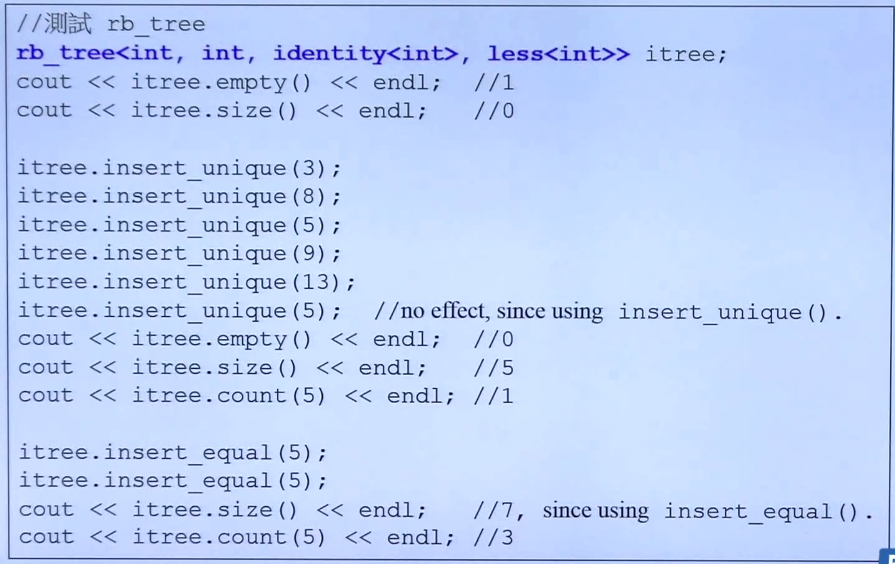
注意:该代码只能在GNU C++2.9中使用,如果要在其他编译器使用,需要自己实现identity类,可以参照上一个图中的代码。在VC6.0中,这个函数叫_Kfn()。
十一、set、multiset深度探索(video21)
1.set和multiset以rb-tree为底层结构,因此元素时自动有序排列的。排序是根据key来排的,而set和multiset元素的value就是key,key就是value。
2.set和multiset提供iterator遍历操作,可以直接获得排序的数据。
3.无法通过iterator来修改元素的值,因为在set和multiset中,key就是value。在rb-tree底层实现中使用的是const iterator。
4.set的元素必须是独一无二的,他的insert()使用的是rb-tree的insert_unique()。multiset的元素可以是重复的,他的insert()使用的是rb-tree的insert_equal()。
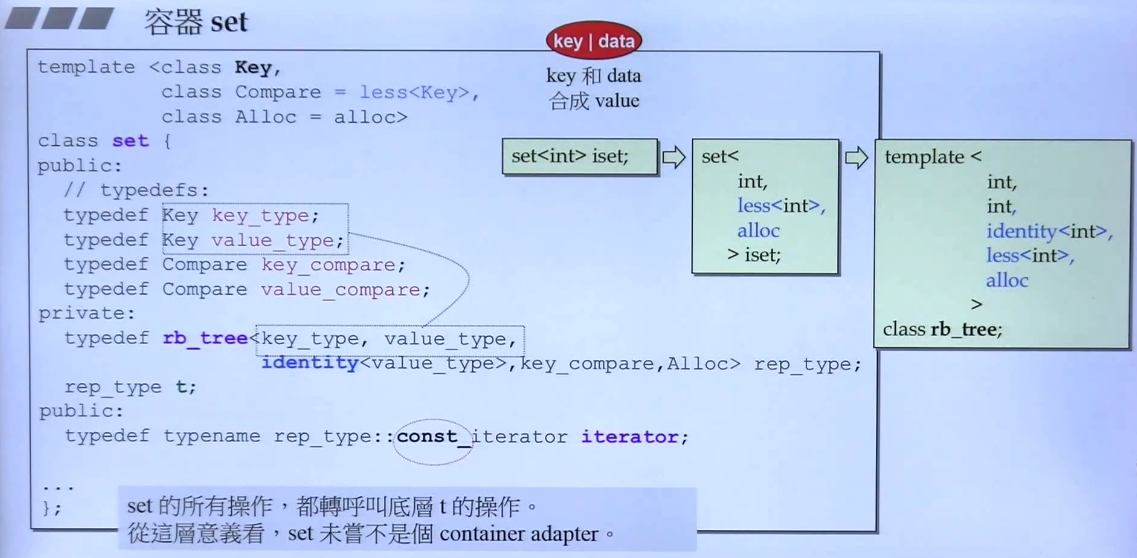
解释:
1.图中绿色方框中描述的是,我们创建一个数据为int类型的set,实际上还有两个默认的模板参数。
2.对应底层rb-tree,会自动将需要的5个模板参数给填充好。
3.如果我们创建的set中存放的元素不是int类型,而是我们自动定义的类,例如Stone,那么我们就要考虑到less函数中是使用小于号比对大小的,那么我们就需要在Stone中重写operator <(或者自己实现对应的仿函数),从而满足其要求。
4.set类中所提供的iterator的类型,实际上是rb-tree所提供的const_iterator,所以在rb-tree底层是一个不可改变其指向值的迭代器。
5.由于set的所有操作都转到rb-tree来做,所以我们可以称set和multiset是一个容器适配器。
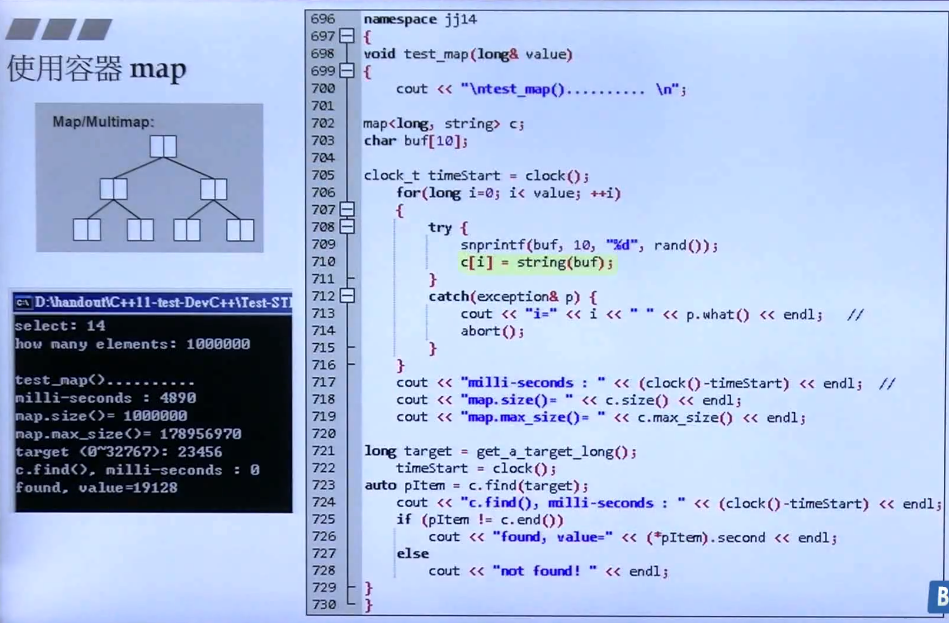
使用multiset示例:
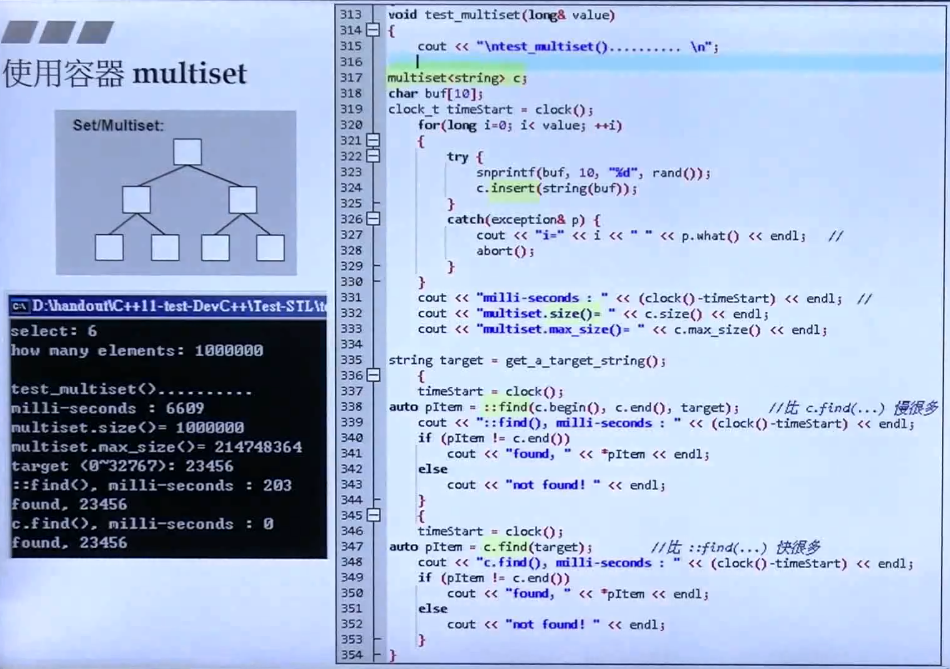
上述代码是往multiset中放入100W个元素,这些元素都是0-3W+的随机数,理论上应该都有重复。放入multiset后,数量还是100W(如果放入set的话,估计就只有3W多)。调用全局的find函数(::find())比调用自己提供的find函数(c.find())要慢很多,所以如果自己提供了算法,优先使用自己的(效率一定更高)。
十二、map、multimap深度探索(video22)
1.map和multimap以rb-tree为底层结构,因此元素时自动有序排列的。排序是根据key来排的。
2.map和multimap提供iterator遍历操作,可以直接获得排序的数据。
3.无法通过iterator来修改key的值,但却可以修改key对应元素中data的值。
4.map中元素的key必须是独一无二的,他的insert()使用的是rb-tree的insert_unique()。multimap中元素的key可以是重复的,他的insert()使用的是rb-tree的insert_equal()。

解释:
1.图中绿色方框中描述的是,我们创建一个key为int类型、data为string类型的map。
2.对应底层rb-tree,会自动将需要的5个模板参数给填充好。
3.注意看rb-tree的第二个参数,他将key和data组合成了一个pair。而且key的类型是const int,就说明key不能修改。
4.rb-tree的第三个参数,使用select1st函数来获取pair中的第一个元素,就可以获取到key。
5.由于set的所有操作都转到rb-tree来做,所以我们可以称map和multimap是一个容器适配器。
使用multimap示例:

map独特的操作符operator []:
方括号中传入的参数是key,用于查找或插入data。
使用方法:
当map中存在对应key的元素时,返回该元素,获取其中的data。
当map中不存在对应key的元素时,如果我们有赋值操作,则创建一个等于指定key的元素,并且存入data。
使用代码如下: