原文地址:https://blog.csdn.net/dashuniuniu/article/details/51072795
引子
最近一直回顾自己曾经写的一些文档,有一篇是关于 Clang Rewriter 的源码分析文档,其中用到了 B+ 树来组织整个代码改写结果。Clang Rewriter 是用于代码改写主要的接口,例如源码级别的代码插桩就要用到 Rewriter 接口,源码修改会带来很多随机的增删,肯定不可能直接在源码字串上增删代码,这样子串频繁移动的开销太大,所以Clang就使用B+树来组织整个过程。由于B+树的叶子节点使用链表链接,所以当增删完成后,先沿着最左子节点一路到达叶子节点(即链表头),然后沿着链表将结果连接起来就会得到最终的结果。
B+ Trees
在写 Clang Rewriter 文档的时候并没有去深入思考这里为什么会选用 B+ Trees 而不是 B Trees,这篇文章中我们稍微解释下选用B+ Trees的优点。B+ Trees的结构如下所示:
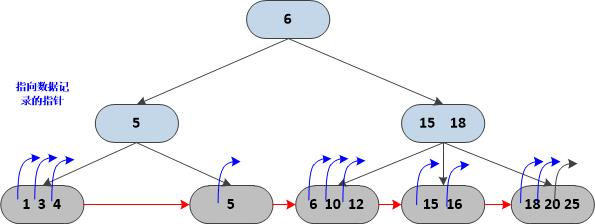
注:该图盗自此处
注意叶子节点是使用链表链接起来的,所以这个很方便最后的修改结果收集,否则需要遍历树中所有节点。
B+ Trees与B Trees一个很大的不同就是B+ Trees的内部节点是不存储数据,存储只是键值,在相同空间下,一个内部节点可以存储到更多的子节点。也就是说可以让整棵树更低。
- It’s all about branching factor. Because of the way B+-Trees store records( called “satellite information”) at the leaf level of the tree, they maximize the branching factor of the internal nodes. High branching factor allows for a tree of lower height. Lower tree height allows for less disk I/O. Less disk I/O means better performance.
注:上面的英文源自此处
上面的英文描述中提到了”branch factor”可以使树高更低,在处理磁盘数据的时候可以减少访问磁盘的次数。磁盘是机械运动比主存(DRAM)慢几个数量级,所以需要尽可能的减少访问磁盘的次数。这个和虚拟内存中,磁盘页和物理页使用全相联的道理是一样的,都是尽可能减少访问磁盘次数。
另外叶子节点使用链表连接起来,只需要一次叶子节点的线性访问就可以获取所有数据。
- The leaf nodes of B+ trees are linked, so doing a full scan of all objects in a tree requires just one linear pass through all the leaf nodes. A B tree, on the other hand, would require a traversal of every level in the tree. This full-tree traversal will likely involve more cache misses than the linear traversal of B+ leaves.
上面的英文描述中提到,B+ Trees另一个优点就是和B Trees相比,cache miss 比较低。
曾经很疑惑 B+ Trees 这么多优点为什么还会有二叉树以及B树或者红黑树的存在呢?
重点在于:B+ Trees 不能在内部节点中存储数据,这就意味着访问所有数据都需要向下访问到叶子节点才能获取到数据。虽然这会带来比较平均的访问性能,但是不能针对某项数据进行优化。例如上个图中,访问数字 1 和 5 开销是一样的,即使你访问了数字 1 1000次,而访问数字 5 只有一次。但是B Trees 和 二叉树就没有这个问题,内部节点可以关联卫星数据,也就是说可以利用 hot spot 的信息,将热区域向根节点靠近。这样访问热区域的时候就可以更快。这个思想类似于霍夫曼树,根据收集到的信息来实时调整这棵树,或者说和 JIT 也很相似。
B Trees
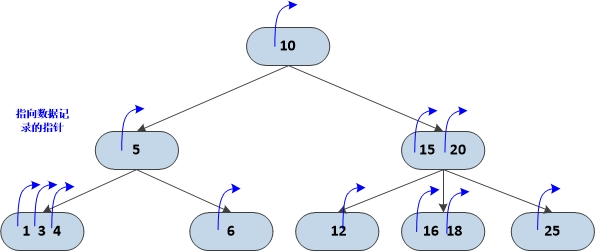
B Trees 和 B+ Trees的重要区别就是内部节点可以存储信息,前面已经提到过 B+ Trees 和 B Trees 主要用于大数据的存储,所以存储场景多是存储在磁盘上。而对于 B+ Trees来说,能够缓存到主存中的数据只能是内部节点,而内部节点只有key值。但是对于 B Trees 来说,内部节点包含有卫星数据,可以缓存到主存中。
- Because B Trees contain data with each key, frequently accessed nodes can lie closer to the root, and therefore can be accessed more quickly.
-
B-Trees on the other hand can be faster when you do a seek (looking for a specific piece of data by key) especially when the tree resides in RAM or other non-block storage. Since you can elevate commonly used nodes in the tree there are less comparisons required to get to the data.
-
But since both data structures have huge fanouts, the vast majority of your matches will be on leaf nodes anyway, making on average the B+ more efficient.
总体对比
Stackoverflow上有一个关于两者对比的回答非常简洁,我这里引用过来,原网址见B trees, B+ trees difference.
(1) In a B tree search keys and data stored in internal or leaf nodes. But in B+-tree data store only leaf nodes.
(2) Searching any data in a B+ tree is very easy because all data are found in leaf nodes. In a B tree, data cannot be found in leaf nodes.
(3) In a B tree, data may be found in leaf nodes or internal nodes. Deletion of internal nodes is very complicated. In a B+ tree, data is only found in leaf nodes. Deletion of leaf nodes is easy.
(4) Insertion in B tree is more complicated than B+ tree.
(5) B+ trees store redundant search key but B tree has no redundant value.
(6) In a B+ tree, leaf nodes data are ordered as a sequential linked list but in B tree the leaf node cannot be stored using a linked list.Many database systems’ implementations prefer the structural simplicity of a B+ tree.
所以整体来说B+ Trees较优一点。
技术之间是相通的,计算机科学方面的问题都是为了解决资源有限的问题,例如主存和CPU之间运算差距很大,而寄存器和CPU一个速度量级的,所以呢,只能选择一部分数据放到寄存器中,如何放呢?这个问题就交给编译器了,编译器使用寄存器分配算法将能够最大化的提高程序运行效率的数据放到寄存器中。后来又提出了cache思想,在运行时根据局部性原理适当的选择一部分数据缓存到cache中,这个方法也是会选择一部分数据放入cache中。
霍夫曼树也是这样的思想,也是选择一部分数据分配给较短的编码,这里的选择依据就是数据出现的概率,变长指令编码和数据压缩也是这个道理。虚拟机中 JIT 技术,也会选择一部分代码编译到native code,这样会相应的提高虚拟机的执行效率。计算机技术中,这样的例子还有很多很多。
同样,在科研中,这样的思想也很适用,就是对某些场景做”特别处理”,重点就是如何找出这些特殊点,当然很多时候都是 瞎碰 ,不停地调优代码,运行并查看结果。你可以根据某个标准挑选 一部分特殊数据 ,但是这些特殊数据肯定也有对比,有高有低,然后就会不停再去其中挑选,所以就出现了 L1 cache, L2 Cache, L3 Cache等等,直到复杂到无法控制为止。