一.字典
字典跟列表一样是一组数据的集合。它的特点是什么呢?
特点一:字典具有键(key)和值(value),其中键必须是唯一的,不可重复的,即键必须可以哈希的。对于值没有要求。
特点二:字典是无序的。
1. 字典的定义:
字典通过“{ }”来定义的,并且里面的键和值形式“键:值”,每个键值对用“,”分隔。例子如下:
dict = {"name":"Leo", "age":24, "hobby":["football","basketball"]}
可以看出字典的值可以是任何数据类型
2. 字典的访问
有些同学会疑问,既然有了列表为什么还要设计一个字典出来呢?这就涉及一个空间换时间的问题,字典的查找速度比列表会快很多,并且不会随着字典的键的增加而变慢,很显然列表就不行了,当列表元素增加的时候它的查找速度就会变慢,但是同样的数据字典存储起来一定比列表要占用更多的空间,因为字典都是键值对组成的。再回来继续讨论字典的访问,列表可以通过索引访问,显然字典没有位置索引,但是字典由键值对组成的,它具有键,可以通过唯一的键快速的访问到对应的值。例如:
dict = {"name":"Leo", "age":24, "hobby":["football","basketball"]}
print(dict["name"])
打印结果:“Leo”。
如果想要往上面的字典中添加新的内容,如何做呢?依然通过键值对添加,例子:
dict["alias"] = "erge"
print(dict)
这时候表示将字典dict中的键“alias”赋一个值是“erge”。
打印结果:“{'name': 'Leo', 'age': 24, 'hobby':['football', 'basketball'], 'alias': 'erge'}”
如果想要修改上面字典中的某个值,如何做呢?还是通过键值对实现,比如要修改“name”的值,例子如下:
dict["name"] = "Tom"
print(dict)
这时候其实就是给dict中的键“name”重新赋了一个值是“Tom”。
打印结果:{'name': 'Tom', 'age': 24, 'hobby':['football', 'basketball'], 'alias': 'erge'}
其实从上面可以看出,字典中的键是唯一的,当我们再次重复键的时候,原来的键中的值会被新创建的替换掉,一直保持唯一。
3. 字典的相关方法
a. get()方法:获取值。
dict = {"name":"Leo", "age":24}
print(dict.get("name"))
打印结果:“Leo”。如果get()方法中输入参数的键,在字典中不存在则返回一个None,在实际开发中,有时候如果不存在返回一个特定值其实也是可以的,用法如下:
dict = {"name":"Leo", "age":24}
print(dict.get("abc",'Tom'))
打印结果:“Tom”。get()中第二个参数就表示不存在的时候,返回一个特定值,如果存在就把字典中对应的值返回。
b. setdefault()方法:用法和get()类似,但是当键不存在的时候,会为其设置一个键,并添加一个默认值。
dict = {"name":"Leo", "age":24}
dict.setdefault("abc",'Tom')
print(dict)
打印结果:“{'name': 'Leo', 'age': 24, 'abc': 'Tom'}”,setdefault()中第二个参数就是要设置的默认值,如果不填,默认为None。大家自己试一下。当键存在字典中依然返回的是字典中对应的值。
c. copy()方法:复制,这里的复制依然是浅复制(浅拷贝)
dict = {"name":"Leo", "age":24}
dict2 = dict.copy()
print(dict2)
打印结果:“{'name': 'Leo', 'age': 24}”。
d. update()方法:
dict = {"name":"Leo", "age":24}
dict2 = {"alias":"erge","sex":"F"}
dict.update(dict2)
print(dict)
打印结果:“{'name': 'Leo', 'age': 24, 'alias': 'erge','sex': 'F'}”。如果dict2中的键跟dict中有重复的会是什么结果呢?大家自己试一下。(提示:跟上面说的一样有重复的键,旧的会被新的替代)
e. clear()方法:删除字典所有元素
dict = {"name":"Leo", "age":24}
dict.clear()
print(dict)
打印结果:“{}”。打印出一个空字典。大家要区别 del,这也是删除某个对象,这个删除是彻底的,del会将某个对象的引用全都删除(之后内存就会等着被回收),可以理解为将对象从内存中删除。而clear()只是删除里面的元素,dict的对象依然存在。
f. pop()方法:删除键对应的值,并返回删除的值,如果不存在则返回默认的值。
dict = {"name":"Leo", "age":24}
print(dict.pop("name","Tom"))
print(dict)
打印结果:

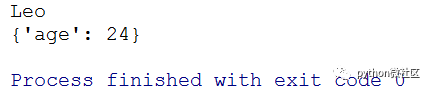
pop()中第二个参数是默认值,当键不存在的时候返回默认值。大家自己试一下,如果要pop一个不存的键,会是什么情况。
g. popitem()方法:随机删除一个键值对。
dict = {"name":"Leo", "age":24}
dict.popitem()
print(dict)
打印结果就不给出了,因为是随机删的,结果不确定,大家试一下,但是通常都会删除字典结尾的键值对,要注意的是,空字典不能使用此方法。
h. fromkeys()方法,创建一个新的字典
seq = ('name', 'age', 'sex')
dict ={}
new_dict = dict.fromkeys(seq,10)
print(new_dict)
打印结果:“{'name': 10, 'age': 10, 'sex': 10}”。fromkeys()中第一个参数列表,是用来做为生成新的字典的键,第二个参数是新字典的值,如果不写,默认为None。通过此方法生成的字典虽然键都是不一样的,但是值都是一样的。对于创建字典,在内置函数中还有一个dict()方法,使用方法如下:
a = dict(name="Leo",age=20)
print(a)
打印结果:“{'name': 'Leo', 'age': 20}”。通过关键字的形式,除此之外,还有如下形式:
a = [('name', 'Leo'), ('age', 20)]
new_dict = dict(a)
print(new_dict)
打印结果:{'name': 'Leo', 'age': 20},通过可迭代对象的方式,大家了解一下即可。其实还有一个映射函数的方式,由于内置方法zip()一直没介绍,这里也就不举例了,感兴趣的自己先行学习一下。
i. __contains__()方法,如果键在字典中返回True,否则返回False.
dict = {"name":"Leo", "age":24}
print(dict.__contains__('name'))
打印结果:“True”。
j. keys()/values()/items()获取字典中的键/值/键值对
dict = {"name":"Leo", "age":24}
print(dict.keys())
print(dict.values())
print(dict.items())
打印结果:

它们的返回值是一些不认识的数据类型(其实返回的是一个迭代器对象,后面结束),可以通过list()将结果变为列表,将print改写一下:
dict = {"name":"Leo", "age":24}
print(list(dict.keys()))
print(list(dict.values()))
print(list(dict.items()))
打印结果:

4. 哈希问题
前面提到过,字典中的键必须是可以哈希的,哈希是什么?就是英文Hash的直译,关于哈希呢。就必须要提到哈希算法:哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,从这个介绍可以看出,哈希是一个能够提高效率的算法,为什么这么说呢?比如有1w篇文章,从里面拿出一篇来,让你确认是否是这1w篇文章中的一个?每篇文章一个个字去比较,想想都可怕,而通过哈希算法可以将每篇文章,变成固定长度的数字,只需要用拿出的文章的数字跟1w篇文章的数字比较,效率是不是高很多。这也是为什么字典中的键需要是可以哈希的,这样会大大提高字典的查找效率,怎么判断一个参数是否是可以哈希的,可以通过内置函数中的hash()方法来确定,如果能偶被哈希会返回一下哈希值,否则会报错。举例:
l = 'abc'
print(hash(l))
打印结果:“1998840242”。对于基础不好的同学,关于哈希问题更多知识大家可以自己去网上了解一下。
二.集合
集合可以看作是一个没有值(value)的字典,特点如下:
特点一:跟字典一样是无需的,
特点二:集合中的元素都是唯一的,即集合中的元素是不可重复的。(当然里面的元素也都是可哈希的)
1. 创建set集合
s = {1,2,3}
print(s, type(s))
打印结果:“{1, 2, 3} <class 'set'>”,打印集合s,并看一下它的类型是否是set集合。
除了上面的方式创建集合,也可以使用内置函数set()方法来创建。
s = [1,2,3]
print(set(s))
打印结果:{1, 2, 3}。
内置函数中还有一个frozenset()函数,创建的是一个不可变的集合。也就是说集合分为可变的set集合和不可变的frozenset集合。
2. set集合相关方法
a. add()方法:添加一个元素
s = {1,2,3}
s.add(6)
print(s)
打印结果:{1, 2, 3, 6}。大家可以试一下往集合中添加一个存在的元素,看是否能添加成功。
b. remove()方法:删除一个元素
s = {1,2,3}
s.remove(2)
print(s)
打印结果:{1, 3}。
c. pop()方法:随机删除一个元素
s = {1,2,3}
print(s.pop(),s)
打印结果:1 {2, 3}。看出pop方法之后返回被删除的元素。
d. discard()方法:删除某个元素
s = {1,2,3}
s.discard(2)
print(s)
打印结果:{1, 3}。这时候dicard()和remove()的用法是一样的,它们二者的区别在于,当你删除一个不存在的元素的时候,remove()会报错,而discard()不会,大家自己试一下。
e. update()方法:扩展集合。
s1 = {1,2,3}
s2 = {4,5,6}
s1.update(s2)
print(s1)
打印结果:{1, 2, 3, 4, 5, 6}。Update()中的参数不一定是集合,也可以是列表,元组,字典,只要是可以迭代的对象就可以。
3. 集合操作
这里的集合操作并不改变原集合,对集合的操除了使用“|”、“&”、“-”、“^”这些操作符之外,也可以通过一些方法实现。
a. 并集 set1|set2
s1 = {1,2,3}
s2 = {4,5,6}
s = s1.union(s2)
print(s)
打印结果:{1, 2, 3, 4, 5, 6}。通过union()方法实现并集。
b. 交集 set1&set2
s1 = {1,2,3,4}
s2 = {3,4,5,6}
s = s1.intersection(s2)
print(s)
打印结果:{3, 4}。通过intersection()方法实现交集。
c. 差集 set1-set2
s1 = {1,2,3,4}
s2 = {3,4,5,6}
s = s1.difference(s2)
print(s)
打印结果:{1, 2}。通过difference()方法实现差集。大家可以试一下s2.difference(s1)的结果。
d. 对称差分 set1^set2
s1 = {1,2,3,4}
s2 = {3,4,5,6}
s = s1.symmetric_difference(s2)
print(s)
打印结果:{1, 2, 5, 6}。通过symmetric_difference ()方法实现差集。
e. 判断子集
s1 = {1,2,3,4}
s2 = {3,4}
s = s1.issuperset(s2)
print(s)
打印结果:True。也就是说s2是s1的子集。除了issuperset()方法外大家自己试一下issubset()方法,也是用来判断子集的。
三.迭代器
前面多次提到了可迭代,什么是可迭代?像我们学过的列表等都可以迭代。可迭代对象都可以使用for循环遍历。即可迭代的对象是一个统称的说法,并不是一个确定的对象或者类型。可迭代的对象内部都有一个迭代器。
而迭代器又是什么?它是一个带状态的对象,他能在你调用next()方法的时候返回容器中的下一个值,任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常,至于它们到底是如何实现的这并不重要。所以,迭代器就是实现了工厂模式的对象,它在你每次你询问要下一个值的时候给你返回。每次调用next()方法的时候做两件事:为下一次调用next()方法修改状态;为当前这次调用生成返回结果。迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。上文参考:https://foofish.net/iterators-vs-generators.html。
通过iter()方法就能获得可迭代对象的迭代器。举例:
l = [1,2,3,4]
a = iter(l)
print(type(a))
打印结果:<class 'list_iterator'>。迭代器既然是一个对象,我们当然可以自己定义迭代器,更多的内容,以后再慢慢介绍。
福利:回复python书,可获得目前python学习的一些认可度比较高的电子书
Tips:上面涉及到的代码。初学者一定要认认真真的自己敲一下,所有的运行的结果我也都在文章中给出来了,千万不要眼高手低。初学者大忌,很多时候自己实现的结果和想象的是不一样的。
特此说明:作者的内容均为原创,转载表明出处。由于本人的能力水平有限,如有发现错误和纰漏请联系作者,拜谢!
如果软件安装、使用python等内容,还有写不明白的同学,可以加入qq群:476581018交流。
