1. 环境准备:
JDK1.8
hive 2.3.4
hadoop 2.7.3
hbase 1.3.3
scala 2.11.12
mysql5.7
2. 下载spark2.0.0
cd /home/worksapce/software wget https://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0-bin-hadoop2.7.tgz tar -xzvf spark-2.0.0-bin-hadoop2.7.tgz mv spark-2.0.0-bin-hadoop2.7 spark-2.0.0
3. 配置系统环境变量
vim /etc/profile
末尾添加
#spark export SPARK_HOME=/home/workspace/software/spark-2.0.0 export PATH=:$PATH:$SPARK_HOME/bin
4. 配置spark-env.sh
cd /home/workspace/software/spark-2.0.0/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh
末尾添加:
export JAVA_HOME=/usr/java/jdk1.8.0_172-amd64 export SCALA_HOME=/home/workspace/software/scala-2.11.12 export HADOOP_HOME=/home/workspace/hadoop-2.7.3 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_HOME=/home/workspace/software/spark-2.0.0 export SPARK_DIST_CLASSPATH=$(/home/workspace/hadoop-2.7.3/bin/hadoop classpath) export SPARK_LIBRARY_PATH=$SPARK_HOME/lib export SPARK_LAUNCH_WITH_SCALA=0 export SPARK_WORKER_DIR=$SPARK_HOME/work export SPARK_LOG_DIR=$SPARK_HOME/logs export SPARK_PID_DIR=$SPARK_HOME/run export SPARK_MASTER_IP=192.168.1.101 export SPARK_MASTER_HOST=192.168.1.101 export SPARK_MASTER_WEBUI_PORT=18080 export SPARK_MASTER_PORT=7077 export SPARK_LOCAL_IP=192.168.1.101 export SPARK_WORKER_CORES=4 export SPARK_WORKER_PORT=7078 export SPARK_WORKER_MEMORY=4g export SPARK_DRIVER_MEMORY=4g export SPARK_EXECUTOR_MEMORY=4g
5. 配置spark-defaults.conf
cd /home/workspace/software/spark-2.0.0/conf cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf
末尾添加
spark.master spark://192.168.1.101:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://192.168.1.101:9000/spark-log spark.serializer org.apache.spark.serializer.KryoSerializer spark.executor.memory 4g spark.driver.memory 4g spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
6. 配置slaves
cd /home/workspace/software/spark-2.0.0/conf cp slaves.template slaves vim slaves
末尾添加
192.168.1.101 192.168.1.102 192.168.1.103
7. 创建相关目录(在spark-env.sh中定义)
hdfs dfs -mkdir -p /spark-log hdfs dfs -chmod 777 /spark-log mkdir -p $SPARK_HOME/work $SPARK_HOME/logs $SPARK_HOME/run
mkdir -p $HIVE_HOME/logs
8.修改hive-site.xml
vim $HIVE_HOME/conf/hive-site.xml
把文件内容修改为
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> <property> <name>hive.exec.scratchdir</name> <value>/hive/tmp</value> <description>Scratch space for Hive jobs</description> </property> <property> <name>hive.querylog.location</name> <value>/hive/log</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.1.103:9083</value> </property> <!--hive server2 settings--> <property> <name>hive.server2.thrift.bind.host</name> <value>192.168.1.103</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.webui.host</name> <value>192.168.1.103</value> </property> <property> <name>hive.server2.webui.host.port</name> <value>10002</value> </property> <property> <name>hive.server2.long.polling.timeout</name> <value>5000</value> </property> <property> <name>hive.server2.enable.doAs</name> <value>true</value> </property> <!--metadata database connection string settings--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.1.103:3308/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> <property> <name>datanucleus.autoCreateSchema </name> <value>false</value> <description>creates necessary schema on a startup if one doesn't exist. set this to false, after creating it once</description> </property> <property> <name>datanucleus.fixedDatastore</name> <value>true</value> </property> <!-- hive on mr--> <!-- <property> <name>mapred.job.tracker</name> <value>http://192.168.1.101:9001</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> --> <!--hive on spark or spark on yarn --> <property> <name>hive.execution.engine</name> <value>spark</value> </property> <property> <name>spark.home</name> <value>/home/workspace/software/spark-2.0.0</value> </property> <property> <name>spark.master</name> <value>spark://192.168.1.101:7077</value> <!-- 或者yarn-cluster/yarn-client --> </property> <property> <name>spark.submit.deployMode</name> <value>client</value> </property> <property> <name>spark.eventLog.enabled</name> <value>true</value> </property> <property> <name>spark.eventLog.dir</name> <value>hdfs://192.168.1.101:9000/spark-log</value> </property> <property> <name>spark.serializer</name> <value>org.apache.spark.serializer.KryoSerializer</value> </property> <property> <name>spark.executor.memeory</name> <value>4g</value> </property> <property> <name>spark.driver.memeory</name> <value>4g</value> </property> <property> <name>spark.executor.extraJavaOptions</name> <value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value> </property> <!--concurrency support--> <property> <name>hive.support.concurrency</name> <value>true</value> <description>Whether hive supports concurrency or not. A zookeeper instance must be up and running for the default hive lock manager to support read-write locks.</description> </property> <property> <name>hive.exec.dynamic.partition.mode</name> <value>nonstrict</value> </property> <!--transaction support--> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> </property> <property> <name>hive.compactor.initiator.on</name> <value>true</value> </property> <property> <name>hive.compactor.worker.threads</name> <value>1</value> </property> <property> <name>hive.stats.autogather</name> <value>true</value> <description>A flag to gather statistics automatically during the INSERT OVERWRITE command.</description> </property> <!--hive web interface settings, I think this is useless,so comment it--> <!-- <property> <name>hive.hwi.listen.host</name> <value>192.168.1.131</value> </property> <property> <name>hive.hwi.listen.port</name> <value>9999</value> </property> <property> <name>hive.hwi.war.file</name> <value>lib/hive-hwi-2.1.1.war</value> </property> --> </configuration>
9. 拷贝hive-site.xml到spark/conf下
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf
10 分发到192.168.1.102,192.168.1.103
cd /home/workspace/software/ scp -r spark-2.0.0 192.168.1.102:/home/workspace/software scp -r spark-2.0.0 192.168.1.103:/home/workspace/software
修改102,103上的SPARK_LOCAL_IP值
vim /home/workspace/software/spark-2.0.0/conf/spark-env.sh
将SPARK_LOCAL_IP分别改为192.168.1.102,192.168.1.103
11 将mysql jar包复制到$SPARK_HOME/lib目录下(每台机器都要做)
cp $HIVE_HOME/lib/mysql-connector-java-5.1.47.jar $SPARK_HOME/lib
注:本例中之前已经安装好hive,如果没有,请到mysql官网网站下载对应的jdbc jar包
12. 启动spark集群
在spark master节点上(本例为192.168.1.101)执行下面语句
$SPARK_HOME/sbin/start-all.sh
192.168.1.101
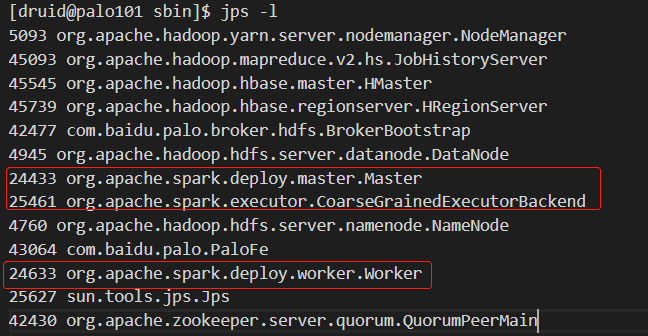
192.168.1.102:
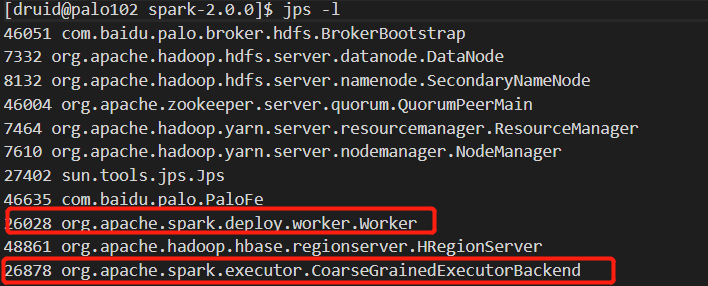
192.168.1.103:

浏览器打开http:192.168.1.101:18080

13.测试使用
[druid@palo101 apache-maven-3.6.0]$ hive /tmp/druid Logging initialized using configuration in file:/home/workspace/software/apache-hive-2.3.4/conf/hive-log4j2.properties Async: true hive> use kylin_flat_db; OK Time taken: 1.794 seconds hive> desc kylin_sales; OK trans_id bigint part_dt date Order Date lstg_format_name string Order Transaction Type leaf_categ_id bigint Category ID lstg_site_id int Site ID slr_segment_cd smallint price decimal(19,4) Order Price item_count bigint Number of Purchased Goods seller_id bigint Seller ID buyer_id bigint Buyer ID ops_user_id string System User ID ops_region string System User Region Time taken: 0.579 seconds, Fetched: 12 row(s) hive> select trans_id, sum(price) as total, count(seller_id) as cnt from kylin_sales group by trans_id order by cnt desc limit 10; Query ID = druid_20190209000716_9676460c-1a76-456d-9bd6-b6f557d5e02c Total jobs = 1 Launching Job 1 out of 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Spark Job = 72720bf1-750d-4f6f-bf9c-5cffa0e4c73b Query Hive on Spark job[0] stages: [0, 1, 2] Status: Running (Hive on Spark job[0]) -------------------------------------------------------------------------------------- STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED -------------------------------------------------------------------------------------- Stage-0 ........ 0 FINISHED 1 1 0 0 0 Stage-1 ........ 0 FINISHED 1 1 0 0 0 Stage-2 ........ 0 FINISHED 1 1 0 0 0 -------------------------------------------------------------------------------------- STAGES: 03/03 [==========================>>] 100% ELAPSED TIME: 10.12 s -------------------------------------------------------------------------------------- Status: Finished successfully in 10.12 seconds OK 8621 33.4547 1 384 15.4188 1 7608 88.6492 1 9166 40.4308 1 9215 63.5407 1 4551 59.2537 1 7041 79.8884 1 522 18.3204 1 5618 78.6241 1 9831 5.8088 1 Time taken: 21.788 seconds, Fetched: 10 row(s) hive>
13 FAQ:
13.1 如果在使用过程中遇到类似下面的错误
Exception in thread "main" java.lang.NoSuchFieldError: SPARK_RPC_SERVER_ADDRESS
通过查看hive的日志文件(在/tmp/{user}/hive.log),这是因为默认使用的spark安装包是继承了hive的包,名字为spark-xxx-bin-hadoopxx.xx.tgz都是继承了hive的包,在hive on spark模式下,会出现冲突,解决办法有两个:
1) 手动编译spark不包含hive的包,具体请参见本人的博文Spark2.0.0源码编译,编译指令为:
./make-distribution.sh --name "hadoop2.7.3-without-hive" --tgz -Dhadoop.version=2.7.3 -Dscala-2.11 -Phadoop-2.7 -Pyarn -DskipTests clean package
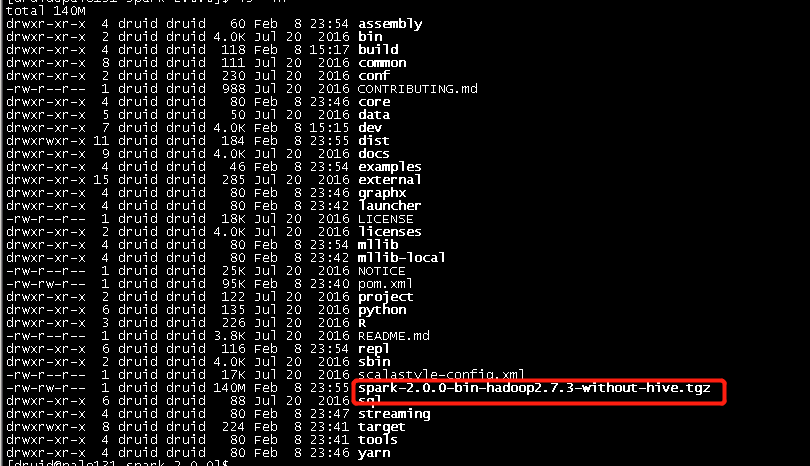
用编译出来的包来安装。
2) 删除预编译包中hive的jar包,具体操作为:
cd $SPARK_HOME/jars rm -f hive-* rm -rf spark-hive_* #删除下面6个文件 # hive-beeline-1.2.1.spark2.jar # hive-cli-1.2.1.spark2.jar # hive-exec-1.2.1.spark2.jar # hive-jdbc-1.2.1.spark2.jar # hive-metastore-1.2.1.spark2.jar # spark-hive_2.11-2.0.0.jar # spark-hive-thriftserver_2.11-2.0.0.jar
注意:每台机器都要做.
13.2 如果出现类似下面的错误
Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/Iterable at org.apache.hadoop.hive.ql.optimizer.spark.SetSparkReducerParallelism.getSparkMemoryAndCores(SetSparkReducerParallelism.java:236) at org.apache.hadoop.hive.ql.optimizer.spark.SetSparkReducerParallelism.process(SetSparkReducerParallelism.java:173) at org.apache.hadoop.hive.ql.lib.DefaultRuleDispatcher.dispatch(DefaultRuleDispatcher.java:90) at org.apache.hadoop.hive.ql.lib.DefaultGraphWalker.dispatchAndReturn(DefaultGraphWalker.java:105) at org.apache.hadoop.hive.ql.lib.DefaultGraphWalker.dispatch(DefaultGraphWalker.java:89) at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:56) at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:61) at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:61) at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:61) at org.apache.hadoop.hive.ql.lib.DefaultGraphWalker.startWalking(DefaultGraphWalker.java:120) at org.apache.hadoop.hive.ql.parse.spark.SparkCompiler.runSetReducerParallelism(SparkCompiler.java:288) at org.apache.hadoop.hive.ql.parse.spark.SparkCompiler.optimizeOperatorPlan(SparkCompiler.java:122) at org.apache.hadoop.hive.ql.parse.TaskCompiler.compile(TaskCompiler.java:140) at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.analyzeInternal(SemanticAnalyzer.java:11273) at org.apache.hadoop.hive.ql.parse.CalcitePlanner.analyzeInternal(CalcitePlanner.java:286) at org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer.analyze(BaseSemanticAnalyzer.java:258) at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:512) at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1317) at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1457) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1227) at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:233) at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:184) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:403) at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136) Caused by: java.lang.ClassNotFoundException: scala.collection.Iterable at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349) at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
这是因为hive无法加载spark的jar包,解决办法为:
$HIVE_HOME/bin/hive
在执行hive之前添加下面的语句,把spark的jar包添加到hive的class path中
SPARK_HOME=/home/workspace/software/spark-2.0.0 for f in ${SPARK_HOME}/jars/*.jar; do CLASSPATH=${CLASSPATH}:$f; done
本人添加的位置为:

或者直接把$SPARK_HOME/jars/spark*复制到$HIVE_HOME/lib下,
cp $SPARK_HOME/jars/spark* $HIVE_HOME/lib
个人感觉修改hive启动脚本更好一些。
14 参考资料