一、套接字编程基础
1、套接字地址结构
通用的地址结构是
struct sockaddr{ unsigned short sa_family; char sa_data[14]; }
IPv4的套接字地址结构是
struct in_addr{ uint32_t s_addr; }; struct sockaddr_in{ short int sin_family; //TCP的协议族是AF_INET unsigned short int sin_port; struct in_addr sin_addr; unsigned char sin_zero[8]; };
2、字节排序函数
小端字节序:低位字节存储在起始地址(即变量第一个字节的内存地址)。
大端字节序:高位字节存储在起始地址。
主机的字节序可能是大端,也可能是小端。网络字节序下面介绍。下面4个函数是实现主机序和网络序的转换:
uint16_t htons(uint16_t); uint32_t htonl(uint32_t); uint16_t ntohs(uint16_t);uint32_t ntohl(uint32_t);
这是搜到的关于网络字节序的描述:UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处);由此可见,多字节数值在发送之前,在内存中应该是以大端法存放的;所以说,网络字节序是大端字节序。
但是我做过实验,即使本机是大端序,调用htonl等字节序还是会变。所以,并不像网上说的,这些函数先判断字节序,大端序就直接返回,小端序就翻转。所以我觉得只要双方的字节序一样,就不需要转换,不过,转换也没关系,不过要双方都转换。最好是都转换,但是如果做过测试,通信双方不转换也可以通信,那也可以不使用上面的函数。
但是有的情况,比如serv_addr.sin_port = htons(port);就必须用上面的函数。
3、地址转换函数
为了方便字符串地址和网络字节序的二进制地址之间转换,提供了相应的转换函数
int inet_aton(const char*strptr, struct in_addr *addrptr);//返回:1 串有效 2 串无效 char *inet_ntoa(struct in_addr inaddr);//返回点分十进制的字符指针,其所指字符串在静态内存,所以该函数不可重入。
二、TCP编程接口
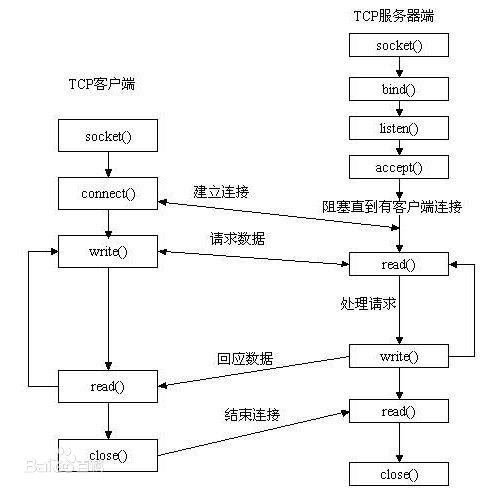
1、socket
#include <sys/socket.h> int socket(int family, int type,int protocal);
family:AF_INT,AF_INT6,AF_UNIX等。
type:SOCK_STREAM 字节流套接字
SOCK_DGRAM 数据报套接字
protocal:一般为0
返回值是一个文件描述符。
2、connect
#include <sys/socket.h> int connect(int sockfd, const struct sockaddr*servaddr, socklen_t addrlen);//socklen_t 定义为uint32_t
客户端向目的ip+port发起三次握手。
3、bind
#include <sys/socket.h> int bind(int sockfd, const struct sockaddr*myaddr, socklen_t addrlen);
把本地的一个地址协议赋给一个套接字。
4、listen
#include <sys/socket.h> int listen(int sockfd, int backlog)
只能服务器端调用该接口,创建套接字时,默认是主动套接字。listen函数将套接字转换成被动套接字,指示内核接受指向改套接字的连接。
5、accept
#include <sys/socket.h> int accept(int sockfd, struct sockaddr*cliaddr,socklen_t *addrlen);
返回值是一个连接套接字,参数sockfd是监听套接字,如果对客户端地址不感兴趣后面两个参数可以设为NULL。
6、close
#include <unistd.h> int close(int fd);
关闭一个文件描述符。
注意:服务器端调用listen函数后,客户端就可以跟服务器端建立TCP连接,并且已经建立的TCP连接会被存放在一个队列中,当调用accpt时,只是返回队头的TCP连接,如果此时队列为空,accpyt默认是阻塞的,进程将被投入睡眠。
三、send和recv函数
1 #include <sys/socket.h> 2 ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags); 3 ssize_t send(int sockfd, const void *buff, size_t nbytes, int flags);
nbyte表示buff的大小,flags一般为0。
1.send函数
1) send先比较发送数据的长度nbytes和套接字sockfd的发送缓冲区的长度,如果nbytes > 套接字sockfd的发送缓冲区的长度, 该函数返回SOCKET_ERROR;
2) 如果nbtyes <= 套接字sockfd的发送缓冲区的长度,那么send先检查协议是否正在发送sockfd的发送缓冲区中的数据,如果是就等待协议把数据发送完,如果协议还没有开始发送sockfd的发送缓冲区中的数据或者sockfd的发送缓冲区中没有数据,那么send就比较sockfd的发送缓冲区的剩余空间和nbytes
3) 如果 nbytes > 套接字sockfd的发送缓冲区剩余空间的长度,send就一起等待协议把套接字sockfd的发送缓冲区中的数据发送完
4) 如果 nbytes < 套接字sockfd的发送缓冲区剩余空间大小,send就仅仅把buf中的数据copy到剩余空间里(注意并不是send把套接字sockfd的发送缓冲区中的数据传到连接的另一端的,而是协议传送的,send仅仅是把buf中的数据copy到套接字sockfd的发送缓冲区的剩余空间里)。
5) 如果send函数copy成功,就返回实际copy的字节数,如果send在copy数据时出现错误,那么send就返回SOCKET_ERROR; 如果在等待协议传送数据时网络断开,send函数也返回SOCKET_ERROR。
6) send函数把buff中的数据成功copy到sockfd的改善缓冲区的剩余空间后它就返回了,但是此时这些数据并不一定马上被传到连接的另一端。如果协议在后续的传送过程中出现网络错误的话,那么下一个socket函数就会返回SOCKET_ERROR。(每一个除send的socket函数在执行的最开始总要先等待套接字的发送缓冲区中的数据被协议传递完毕才能继续,如果在等待时出现网络错误那么该socket函数就返回SOCKET_ERROR)
7) 在unix系统下,如果send在等待协议传送数据时网络断开,调用send的进程会接收到一个SIGPIPE信号,进程对该信号的处理是进程终止。
2.recv函数
1) recv先等待s的发送缓冲区的数据被协议传送完毕,如果协议在传送sock的发送缓冲区中的数据时出现网络错误,那么recv函数返回SOCKET_ERROR
2) 如果套接字sockfd的发送缓冲区中没有数据或者数据被协议成功发送完毕后,recv先检查套接字sockfd的接收缓冲区,如果sockfd的接收缓冲区中没有数据或者协议正在接收数据,那么recv就一起等待,直到把数据接收完毕。当协议把数据接收完毕,recv函数就把s的接收缓冲区中的数据copy到buff中(注意协议接收到的数据可能大于buff的长度,所以在这种情况下要调用几次recv函数才能把sockfd的接收缓冲区中的数据copy完。recv函数仅仅是copy数据,真正的接收数据是协议来完成的)
3) recv函数返回其实际copy的字节数,如果recv在copy时出错,那么它返回SOCKET_ERROR。如果recv函数在等待协议接收数据时网络中断了,那么它返回0。
4) 在unix系统下,如果recv函数在等待协议接收数据时网络断开了,那么调用 recv的进程会接收到一个SIGPIPE信号,进程对该信号的默认处理是进程终止
总之,一个TCP连接有自己的接收缓冲区和发送缓冲区,send和recv都是和缓冲区之间进行数据的拷贝。
四、阻塞和非阻塞
进程的状态有就绪,休眠(阻塞),运行。当进程期待一个事件时,就会进入休眠状态。
linux的经典IO模型有五种,平时用到的有3种:阻塞IO,非阻塞IO和IO多路复用。
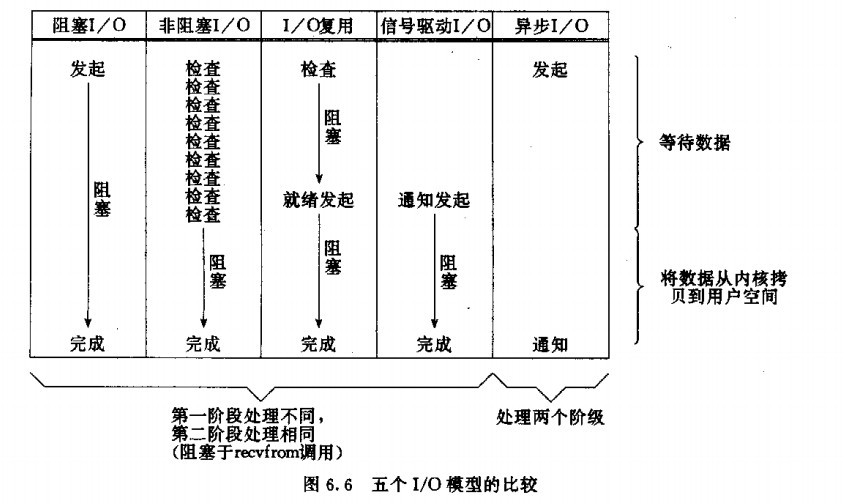
在W. Richard Stevens的《UINX网络编程》中,将IO操作分成两个阶段,以recv为例,分别是等待数据阶段和将数据从内核区拷贝到用户空间。并且认为第二阶段,recv系统调用会使进入内核态,完成数据从内核到用户空间的拷贝,期间应用进程是被阻塞的。
阻塞IO:进程从调用到返回都是阻塞。
非阻塞IO:当IO操作非要把进程投入睡眠才能完成时,不要把进程投入睡眠,而是返回一个错误。
IO多路复用:首先阻塞于select、epoll,等待套接字可读,然后再阻塞于recv,拷贝数据。所以IO多路复用调用两次系统调用,这样看来并不比阻塞IO强多少,但是它的优势是可以等待多个描述符。
前四种都是同步IO,只有最后一种是异步IO。对于同步,异步是这样区分的:
同步IO:会导致进程阻塞,直到操作完成的IO操作。
异步IO:不会导致进程阻塞的IO操作。
阻塞和睡眠:
阻塞和非阻塞IO的区别是否会导致进程睡眠,而同步和异步IO的区别是否会导致进程阻塞。所以阻塞和睡眠的区别就很重要了,如果进程阻塞就意味着进程睡眠,那么阻塞就是同步,非阻塞就是异步了。其实,进程睡眠是进程的一种状态(TASK_INTERRUPTIBLE或UNTASK_INTERRUPTIBLE),而进程阻塞是进程的一种外在表现,即在我们看来进程在某一条语句"卡住了"或"卡了很长时间",没有立即返回。就是程序员的一种主观感受,在程序中没有明确判断标准。所以,进程睡眠肯定是进程阻塞了,但除了进程睡眠之外,请求自旋锁,从内核缓冲区向进程空间拷贝数据(即recv函数),都是进程阻塞。所以,阻塞只是方便程序员们之间的交流,只要在某一条语句没有立即返回,我们都可以说进程被阻塞了。
下面介绍四个套接字函数对于阻塞和非阻塞套接字的区别:
- 输入操作:read,recv等函数,阻塞:缓冲区没有数据可读时,进程睡眠;非阻塞:没有数据可读时,报错 EWOULDBLOCK。
- 输出操作:write,send等函数,阻塞:缓冲区没空间时,进程睡眠; 非阻塞:缓冲区没空间时,报错 EWOULDBLOCK。
- 接收连接:accept函数, 阻塞:没新连接到达时, 进程睡眠; 非阻塞:没新连接到达时,报错 EWOULDBLOCK。
- 发起连接:connect函数, 阻塞:睡眠,等待三次握手完成; 非阻塞:报错EINPROGRESS(也有可能连接成功,比如同机器的情况)
其实,阻塞还是非阻塞是对于套接字而言。
五、select和epoll
多路复用IO相对阻塞IO的优点是能够同时处理多个描述符,相对于多线程阻塞IO的优点是占用的资源少,能够处理描述符多。
1、int select(
int nfds,
fd_set* readfds,
fd_set* writefds,
fd_set* exceptfds,
const struct timeval* timeout
);
select实现I/O多路复用过程:
1、将所有的描述符复制到内核。
2、然后进入一个循环:
for(;;)
{
遍历描述符集合,并将描述符挂到相应的等待队列中。
if(有描述符就绪 || 超时时间到 || 有信号)
break;
睡眠一段时间,直到超时或有设备就绪
}
首先会遍历一遍描述符集合,遍历的过程会进程添加到相应设备的等待队列中,并且返回就绪的描述符。
如果有就绪的就退出循环(或者超时时间到,或者有信号要处理)。
如果没有就绪的就会睡眠一段时间,直到时间到或者有描述符就绪,就会唤醒进程,继续遍历描述符集合。(这个“一段时间”应该不是select参数的超时时间)
3、将2中返回的已就绪的描述符集合复制到应用缓冲区。
这样看来select的实现思想也就是将进程放在相应设备的等待队列中,当设备就绪时,通知进程,进程将相应的描述符返回。也没什么嘛。
select的缺点也都知道:1、描述符集合要复制到内核,然后将就绪的描述符从内核再复制到应用区;2、要多次遍历描述符集合;3、描述符集合的大小有限。
关键是select需要不断反复调用,而且描述符的集合有时会很大,所以select 的缺点会被放大
但是select是所有平台都实现了的机制,再者在描述符不多,而且比较活跃的情况下,select的效率很不错的。
2、
epoll一共三个函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
1. struct epoll_event 结构体epoll_event被用于注册所感兴趣的事件和回传所发生待处理的事件,定义如下: typedef union epoll_data { void *ptr; int fd; __uint32_t u32; __uint64_t u64; } epoll_data_t;//保存触发事件的某个文件描述符相关的数据 struct epoll_event { __uint32_t events; /* epoll event */ epoll_data_t data; /* User data variable */ }; |
其中events表示感兴趣的事件和被触发的事件,可能的取值为:
EPOLLIN:表示对应的文件描述符可以读;
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数可读;
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: ET的epoll工作模式;
所涉及到的函数有:
1、epoll_create函数
函数声明:int epoll_create(int size)
功能:该函数生成一个epoll专用的文件描述符,其中的参数是指定生成描述符的最大范围;
2、epoll_ctl函数
函数声明:int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
功能:用于控制某个文件描述符上的事件,可以注册事件,修改事件,删除事件。
@epfd:由epoll_create生成的epoll专用的文件描述符;
@op:要进行的操作,EPOLL_CTL_ADD注册、EPOLL_CTL_MOD修改、EPOLL_CTL_DEL删除;
@fd:关联的文件描述符;
@event:指向epoll_event的指针;
成功:0;失败:-1
3、epoll_wait函数
函数声明:int epoll_wait(int epfd,struct epoll_event * events,int maxevents,int timeout)
功能:该函数用于轮询I/O事件的发生;
@epfd:由epoll_create生成的epoll专用的文件描述符;
@epoll_event:用于回传代处理事件的数组;
@maxevents:每次能处理的事件数;
@timeout:等待I/O事件发生的超时值;
成功:返回发生的事件数;失败:-1
poll的实现和select的实现差不多。
epoll的是为了克服select和poll的缺点设计的,实现也比较复杂。
epoll首先内核会维护描述符集合,epoll_ctl对事件的添加删除只需要一次操作,所以节省了内核和用户区之间文件描述符复制的开销。
而且内核不会多次遍历描述符集合,有一个就绪列表,如果有描述符就绪会添加到就绪列表,spoll_wait只是遍历已经就绪的描述符。
有描述符就绪,或者超时会返回。
最后,支持的描述符集合的大小更大。
但是,如果大部分描述符是活跃状态,则epoll的效率可能不如select,poll。而且,epoll只是linux实现了,不具有移植性。
六、EPOLL的LT和ET模式及相应的读写方式
1、LT和ET模式
二者的差异在于level-trigger模式下只要某个socket处于readable/writable状态,无论什么时候进行epoll_wait都会返回该socket;(默认LT)
而edge-trigger模式下只有某个socket从unreadable变为readable或从unwritable变为writable时,epoll_wait才会返回该socket。
2、读写方式
read/write阻塞和非阻塞表现方式是不同的。阻塞r/w可能引起进程的睡眠,如果返回-1表示出现网络错误;非阻塞r/w不会引起进程阻塞,如果返回-1表示可能是网络错误,也可能是可以忽略的错误EAGAIN或者EWOULDBLOCK,表示可以过会再试。
下面说的是非阻塞r/w。
ET的读写模式是:
读:只要可读,就一直读,直到返回0,或者 -1,errno = EAGAIN
写:只要可写,就一直写,直到数据发送完,或者-1, errno = EAGAIN
LT的读写模式是:
读:可读就读,没读完也没关系,因为下次epoll_wait还是通知继续读取。
写:为了防止epoll不停的触发socket可写的事件,开始不把socket加入epoll,需要向socket写数据的时候,直接调用write或者send发送数据。如果返回EAGAIN,把socket加入epoll,在epoll的驱动下写数据,全部数据发送完毕后,再移出epoll。