1、查找
静态查找:数据集合稳定,不需要添加,删除元素的查找操作。可以用线性表结构组织数据,可以采用顺序查找算法。如果还需要对关键词进行排序,则可以使用折半查找算法或斐波那契查找算法来提高效率。
动态查找:数据集合在查找的过程中需要同时添加或删除元素的查找操作。可以采用二叉排序树查找技术,另外可以使用散列表结构。
存储结构:顺序存储;链式存储;索引存储;哈希(或散列)存储;顺序存储的线性表不但逻辑上连续,物理上也连续,可以使用顺序查找法。链式存储的线性表虽然物理上不一定连续,但逻辑上连续(通过额外的指针表示逻辑相邻关系),也可以使用顺序查找法。
2、顺序查找O(n)
从第一个(或最后一个)开始,逐个进行记录的关键字和给定值进行比较匹配。
void Sq_Search(int* a, int n, int key) { int i; for (i = 0; i <= n; i++) { if (a[i] == key) { return i; } } return 0; }
上面程序需要2*n次比较,顺序查找的优化,设置哨兵,n次比较
int Sq_Search(int* a, int n, int key) { int i = n; a[0] = key; while (a[i] != key) { i--; } return i; }
3、插值查找(按比例查找,折半查找是0.5比例)O(log2n)
比例查找唯一的不同就在于mid的计算方式:
int main() { int a[11] = { 1, 3, 3, 10, 13, 16, 19, 21, 23, 27, 31 }; int left, mid, right, num; left = 0; right = 10; num = 27; while (left <= right) { //mid = (left + right) / 2; //折半查找,对于数据分布不均匀,跳动很大效率高。 mid = low + (num - a[low]) / (a[high] - a[low]) * (high - low); //按比例查找,对于分布均匀的线性增长的数据,效率很高。 if (a[mid] > num) right = mid - 1; else if (a[mid] < num) left = mid + 1; else break; } printf("index:%d", mid); system("pause"); return 0; }
4、斐波那契查找(黄金比例查找)0.618:1
对于斐波那契数列1,1,2,3,5,8,13,21,34,55,89,...前后两个数的比例越来越接近于黄金比例0.618
首先要明确:如果一个有序表的元素个数为n,并且n正好是(某个斐波那契数 - 1),即n=F[k]-1时,才能用斐波那契查找法。 如果有序表的元素个n不等于(某个斐波那契数 - 1),即n≠F[k]-1,这时必须要将有序表的元素扩展到大于n的那个斐波那契数 - 1才行。
1)a的长度其实很好估算,比如你定义了有10个元素的有序数组a[20],n=10,那么n就位于8和13,即F[6]和F[7]之间,所以 k=7,此时数组a的元素个数要被扩充,为:F[7] - 1 = 12个; 再如你定义了一个b[20],且b有12个元素,即n=12,那么很好办了,n = F[7]-1 = 12, 用不着扩充了; 又或者n=8或9或11,则它一定会被扩充到12; 再如你举的例子,n=13,最后得出n位于13和21,即F[7]和F[8]之间,此时k=8,那么F[8]-1 = 20,数组a就要有20个元素了。 所以,n = x(13<=x<=20)时,最后都要被扩充到20;类推,如果n=25呢,则数组a的元素个数肯定要被扩充到 34 - 1 = 33个(25位于21和34,即F[8]和F[9]之间,此时k=9,F[9]-1 = 33),所以,n = x(21<=x<=33)时,最后都要被扩充到33。也就是说,最后数组的元素个数一定是(某个斐波那契数 - 1),这就是一开始说的n与F[k]-1的关系。
2)对于二分查找,分割是从mid= (low+high)/2开始;而对于斐波那契查找,分割是从mid = low + F[k-1] - 1开始的; 通过上面知道了,数组a现在的元素个数为F[k]-1个,即数组长为F[k]-1,mid把数组分成了左右两部分, 左边的长度为:F[k-1] - 1, 那么右边的长度就为(数组长-左边的长度-1), 即:(F[k]-1) - (F[k-1] - 1) = F[k] - F[k-1] - 1 = F[k-2] - 1。 为了格式上的统一,以方便递归或者循环程序的编写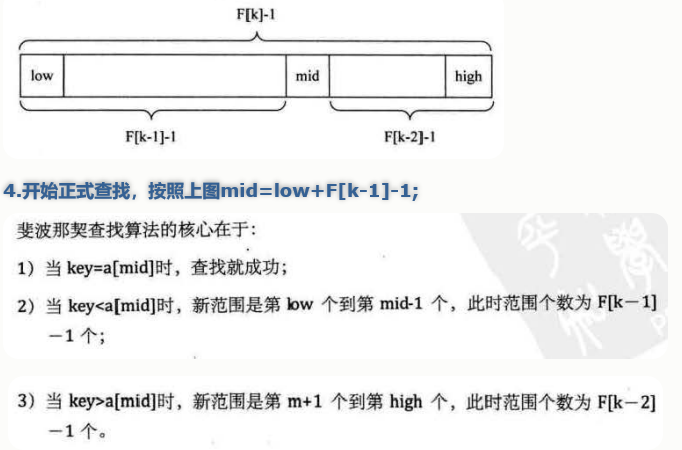
// 斐波那契查找.cpp #include "stdafx.h" #include <memory> #include <iostream> using namespace std; const int max_size=20;//斐波那契数组的长度 /*构造一个斐波那契数组*/ void Fibonacci(int * F) { F[0]=0; F[1]=1; for(int i=2;i<max_size;++i) F[i]=F[i-1]+F[i-2]; } /*定义斐波那契查找法*/ int Fibonacci_Search(int *a, int n, int key) //a为要查找的数组,n为要查找的数组长度,key为要查找的关键字 { int low=0; int high=n-1; int F[max_size]; Fibonacci(F);//构造一个斐波那契数组F int k=0; while(n>F[k]-1)//计算n位于斐波那契数列的位置 ++k; int * temp;//将数组a扩展到F[k]-1的长度 temp=new int [F[k]-1]; memcpy(temp,a,n*sizeof(int)); for(int i=n;i<F[k]-1;++i) temp[i]=a[n-1]; while(low<=high) { int mid=low+F[k-1]-1; if(key<temp[mid]) { high=mid-1; k-=1; } else if(key>temp[mid]) { low=mid+1; k-=2; } else { if(mid<n) return mid; //若相等则说明mid即为查找到的位置 else return n-1; //若mid>=n则说明是扩展的数值,返回n-1 } } delete [] temp; return -1; } int _tmain(int argc, _TCHAR* argv[]) { int a[] = {0,16,24,35,47,59,62,73,88,99}; int key=100; int index=Fibonacci_Search(a,sizeof(a)/sizeof(int),key); cout<<key<<" is located at:"<<index; system("PAUSE"); return 0; }
https://blog.csdn.net/Rex_WUST/article/details/88095418
https://www.cnblogs.com/ssyfj/p/9499162.html