1. 利用 Partition 实现并行处理
我们都知道 Kafka 是一个 Pub-Sub 的消息系统,无论是发布还是订阅,都要指定 Topic。
Topic 只是一个逻辑的概念。每个 Topic 都包含一个或多个 Partition,不同 Partition 可位于不同节点。
一方面,由于不同 Partition 可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。另一方面,由于 Partition 在物理上对应一个文件夹,即使多个 Partition 位于同一个节点,也可通过配置让同一节点上的不同 Partition 置于不同的磁盘上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
能并行处理,速度肯定会有提升,多个工人肯定比一个工人干的快。
2. 顺序写磁盘
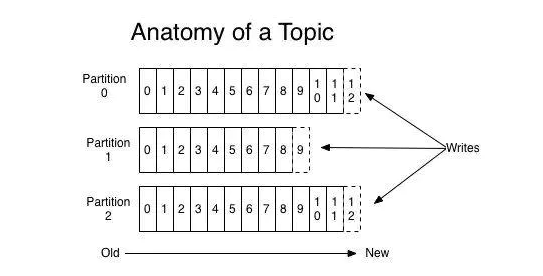
Kafka 中每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 partition 的末尾,这个就是顺序写。
很久很久以前就有人做过基准测试:《每秒写入2百万(在三台廉价机器上)》
由于磁盘有限,不可能保存所有数据,实际上作为消息系统 Kafka 也没必要保存所有数据,需要删除旧的数据。又由于顺序写入的原因,所以 Kafka 采用各种删除策略删除数据的时候,并非通过使用“读 - 写”模式去修改文件,而是将 Partition 分为多个 Segment,每个 Segment 对应一个物理文件,通过删除整个文件的方式去删除 Partition 内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
3、零拷贝技术
Kafka 中存在大量的网络数据持久化到磁盘(Producer 到 Broker)和磁盘文件通过网络发送(Broker 到 Consumer)的过程。这一过程的性能直接影响 Kafka 的整体吞吐量。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。
为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。
传统的 Linux 系统中,标准的 I/O 接口(例如read,write)都是基于数据拷贝操作的,即 I/O 操作会导致数据在内核地址空间的缓冲区和用户地址空间的缓冲区之间进行拷贝,所以标准 I/O 也被称作缓存 I/O。这样做的好处是,如果所请求的数据已经存放在内核的高速缓冲存储器中,那么就可以减少实际的 I/O 操作,但坏处就是数据拷贝的过程,会导致 CPU 开销。
我们把 Kafka 的生产和消费简化成如下两个过程来看[2]:
网络数据持久化到磁盘 (Producer 到 Broker)
磁盘文件通过网络发送(Broker 到 Consumer)
总结
如果,面试官再问我:Kafka为什么这么快?我会这么说:
partition 并行处理
顺序写磁盘,充分利用磁盘特性
利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率
采用了零拷贝技术
Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗