# 加载路透社数据集
from keras.datasets import reuters
(train_data,train_labels),(test_data,test_labels) = reuters.load_data(num_words=10000)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/reuters.npz
2113536/2110848 [==============================] - 1s 1us/step
E:my_softwareanaconda3libsite-packages ensorflowpythonkerasdatasets
euters.py:148: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
x_train, y_train = np.array(xs[:idx]), np.array(labels[:idx])
E:my_softwareanaconda3libsite-packages ensorflowpythonkerasdatasets
euters.py:149: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
x_test, y_test = np.array(xs[idx:]), np.array(labels[idx:])
len(train_data)
8982
test_labels
array([ 3, 10, 1, ..., 3, 3, 24], dtype=int64)
len(test_data)
2246
train_data[10]
[1,
245,
273,
207,
156,
53,
74,
160,
26,
14,
46,
296,
26,
39,
74,
2979,
3554,
14,
46,
4689,
4329,
86,
61,
3499,
4795,
14,
61,
451,
4329,
17,
12]
# 将索引解码为新闻文本
word_index = reuters.get_word_index()
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
decoded_newswire = ' '.join([reverse_word_index.get(i-3,'?') for i in train_data[0]])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/reuters_word_index.json
557056/550378 [==============================] - 0s 1us/step
train_labels[10]
3
# 准备数据
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i,sequence] = 1
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
def to_one_hot(labels,dimension=46): # 输出类别是46个
results = np.zeros((len(labels),dimension))
for i,label in enumerate(labels):
results[i,label] = 1
return results
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
# 模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(46,activation='softmax')) # 每个输入样本,网络都会输出46维向量,每个维度表示不同的输出类别
# 编译模型
model.compile(optimizer='rmsprop',
loss = 'categorical_crossentropy', # 损失函数使用分类交叉熵,衡量网络输入的概率分布和标签的真实分布
metrics = ['acc'])
# 留出验证集 1000个样本
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
# 训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val,y_val))
Epoch 1/20
16/16 [==============================] - 2s 54ms/step - loss: 3.1920 - acc: 0.4216 - val_loss: 1.7198 - val_acc: 0.6360
Epoch 2/20
16/16 [==============================] - 1s 36ms/step - loss: 1.4709 - acc: 0.7034 - val_loss: 1.2679 - val_acc: 0.7270
Epoch 3/20
16/16 [==============================] - 1s 36ms/step - loss: 1.0407 - acc: 0.7804 - val_loss: 1.1028 - val_acc: 0.7600
Epoch 4/20
16/16 [==============================] - 1s 36ms/step - loss: 0.8029 - acc: 0.8301 - val_loss: 1.0156 - val_acc: 0.7750
Epoch 5/20
16/16 [==============================] - 1s 36ms/step - loss: 0.6605 - acc: 0.8615 - val_loss: 0.9430 - val_acc: 0.8010
Epoch 6/20
16/16 [==============================] - 1s 36ms/step - loss: 0.5219 - acc: 0.8927 - val_loss: 0.9151 - val_acc: 0.8060
Epoch 7/20
16/16 [==============================] - 1s 36ms/step - loss: 0.4242 - acc: 0.9141 - val_loss: 0.8901 - val_acc: 0.8090
Epoch 8/20
16/16 [==============================] - 1s 37ms/step - loss: 0.3290 - acc: 0.9317 - val_loss: 0.8953 - val_acc: 0.8040
Epoch 9/20
16/16 [==============================] - 1s 35ms/step - loss: 0.2787 - acc: 0.9383 - val_loss: 0.9103 - val_acc: 0.7980
Epoch 10/20
16/16 [==============================] - 1s 35ms/step - loss: 0.2348 - acc: 0.9482 - val_loss: 0.8917 - val_acc: 0.8180
Epoch 11/20
16/16 [==============================] - 1s 35ms/step - loss: 0.2013 - acc: 0.9500 - val_loss: 0.9381 - val_acc: 0.8100
Epoch 12/20
16/16 [==============================] - 1s 36ms/step - loss: 0.1748 - acc: 0.9571 - val_loss: 0.9009 - val_acc: 0.8230
Epoch 13/20
16/16 [==============================] - 1s 36ms/step - loss: 0.1582 - acc: 0.9572 - val_loss: 0.9446 - val_acc: 0.8090
Epoch 14/20
16/16 [==============================] - 1s 36ms/step - loss: 0.1409 - acc: 0.9560 - val_loss: 0.9726 - val_acc: 0.8070
Epoch 15/20
16/16 [==============================] - 1s 36ms/step - loss: 0.1272 - acc: 0.9612 - val_loss: 0.9624 - val_acc: 0.8160
Epoch 16/20
16/16 [==============================] - 1s 36ms/step - loss: 0.1260 - acc: 0.9582 - val_loss: 0.9704 - val_acc: 0.8090
Epoch 17/20
16/16 [==============================] - 1s 35ms/step - loss: 0.1110 - acc: 0.9627 - val_loss: 1.0493 - val_acc: 0.7980
Epoch 18/20
16/16 [==============================] - 1s 36ms/step - loss: 0.1069 - acc: 0.9628 - val_loss: 1.0567 - val_acc: 0.7950
Epoch 19/20
16/16 [==============================] - 1s 35ms/step - loss: 0.1038 - acc: 0.9638 - val_loss: 1.0635 - val_acc: 0.7970
Epoch 20/20
16/16 [==============================] - 1s 32ms/step - loss: 0.0991 - acc: 0.9620 - val_loss: 1.2842 - val_acc: 0.7650
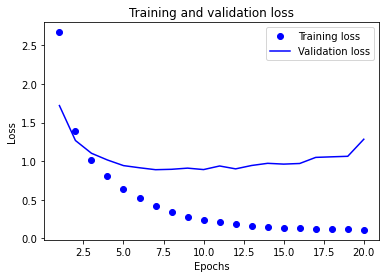
# 绘制训练损失和验证损失
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
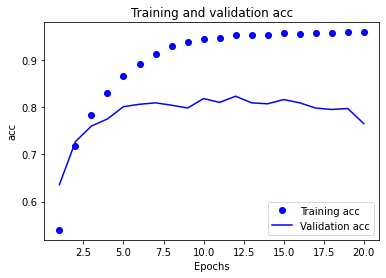
# 绘制训练精度和验证精度
plt.clf()
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.plot(epochs,acc,'bo',label='Training acc')
plt.plot(epochs,val_acc,'b',label='Validation acc')
plt.title('Training and validation acc')
plt.xlabel('Epochs')
plt.ylabel('acc')
plt.legend()
plt.show() # 第九次出现了过拟合
# 重新训练一个迭代9次的网络
model = models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(46,activation='softmax')) # 每个输入样本,网络都会输出46维向量,每个维度表示不同的输出类别
model.compile(optimizer='rmsprop',
loss = 'categorical_crossentropy', # 损失函数使用分类交叉熵,衡量网络输入的概率分布和标签的真实分布
metrics = ['acc'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val,y_val))
results = model.evaluate(x_test,one_hot_test_labels)
Epoch 1/9
16/16 [==============================] - 2s 48ms/step - loss: 3.1355 - acc: 0.4151 - val_loss: 1.7546 - val_acc: 0.6460
Epoch 2/9
16/16 [==============================] - 1s 36ms/step - loss: 1.5295 - acc: 0.6920 - val_loss: 1.3043 - val_acc: 0.7100
Epoch 3/9
16/16 [==============================] - 1s 36ms/step - loss: 1.0924 - acc: 0.7680 - val_loss: 1.1147 - val_acc: 0.7590
Epoch 4/9
16/16 [==============================] - 1s 35ms/step - loss: 0.8348 - acc: 0.8246 - val_loss: 1.0238 - val_acc: 0.7870
Epoch 5/9
16/16 [==============================] - 1s 35ms/step - loss: 0.6446 - acc: 0.8607 - val_loss: 0.9424 - val_acc: 0.8050
Epoch 6/9
16/16 [==============================] - 1s 35ms/step - loss: 0.5079 - acc: 0.8983 - val_loss: 0.9296 - val_acc: 0.8050
Epoch 7/9
16/16 [==============================] - 1s 36ms/step - loss: 0.3936 - acc: 0.9246 - val_loss: 0.8924 - val_acc: 0.8090
Epoch 8/9
16/16 [==============================] - 1s 35ms/step - loss: 0.3364 - acc: 0.9317 - val_loss: 0.8653 - val_acc: 0.8190
Epoch 9/9
16/16 [==============================] - 1s 33ms/step - loss: 0.2872 - acc: 0.9419 - val_loss: 0.8967 - val_acc: 0.8060
71/71 [==============================] - 0s 2ms/step - loss: 0.9991 - acc: 0.7867
results # 损失,精度
[0.9991146326065063, 0.7867319583892822]
# 和一个随机的分类器进行比较
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
hits_array = np.array(test_labels) == np.array(test_labels_copy)
float(np.sum(hits_array)) / len(test_labels)
0.19323241317898487
# 相比于随机分类器,我们的模型可以达到78的准确率,完全OK
# 在新数据上预测
predictions = model.predict(x_test)
predictions[0].shape
(46,)
np.sum(predictions[0])
1.0
np.argmax(predictions[0]) # 概率最大的类别
3