太久没动这里,目前人生处于一个新的开始。这次博客的内容很久前就想更新上来,但是一直没找到合适的时间点(哈哈,其实就是懒),主要内容集中在使用Mongodb时的一些隐蔽的MapReduce问题:
1、Reduce时的计数问题
2、Reduce时的提取数据问题
另外,补充一个小tips:mongoDB中建立的索引,优先使用固定的,而不要使用范围。
一、MapReduce时的计数问题
这个问题主要出现在使用“+1”的思路去计算累计次数时。如果在Map后的某一类中,记录量过大,就会导致计数失败。
具体演示如下:
原始数据(有400条一样的存在数据库results表中):{ "grade" : 1, "name" : "lekko", "score" : 95 }
进行MapReduce:
1 db.runCommand({ mapreduce: "results", 2 map : function Map() { 3 emit( 4 {grade:this.grade}, 5 {recnum:1,score:this.score} 6 ); 7 }, 8 reduce : function Reduce(key, values) { 9 var reduced = {recnum:0,score:0}; 10 values.forEach(function(val){ 11 reduced.score += val.score; 12 ++reduced.recnum; 13 }); 14 return reduced; 15 }, 16 finalize : function Finalize(key, reduced) { 17 return reduced; 18 }, 19 out : { inline : 1 } 20 });
满怀希望地以为value.recnum会输出400,结果却是101!而value.scorce却是输出的正确的:38000(95*400)。本人在这疑惑了好久,并且通过更改reduce函数: function Reduce(key, values) { return {test:values}; } ,发现数据是这样的:
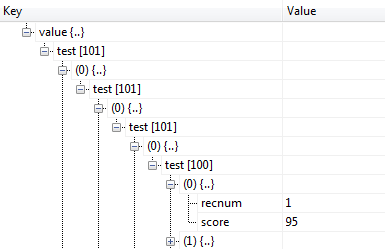
在原本Reduce函数中的forEach只遍历了第一层的数据,即101个,所以++操作也只做了101次!
经过思考,导致问题的原因关键就在于MapReduce中emit后的Bosn的数据格式,一个大于100的Array,会被拆分存储,变成了非线性的链表结构,如图:
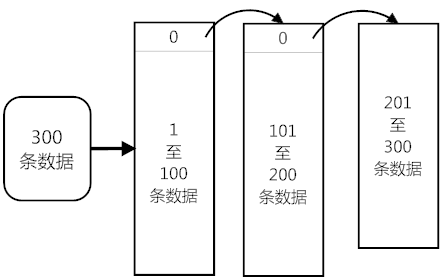
那么,分数相加却能正确,可以大胆地推测:“reduced.score += val.score;” 语句可以智能地找到所有子结点的score并相加!
最后,这里给出计数的替代方案,修改Reduce的++,改用+=操作:
1 function Reduce(key, values) { ; 2 var reduced = {recnum:0,score:0}; 3 values.forEach(function(val){ 4 reduced.score += val.score; 5 reduced.recnum += val.recnum; 6 }); 7 return reduced; 8 }
二、在Reduce中把数据提取出来组成Array
这个问题产生的原因与上面的相似,也是由于emit后的数据在reduce时是非线性的(有层次关系),所以提取数据字段时也会产生问题,为了测试,往上面所说的表中再插入3条数据:
{ "grade" : 1, "name" : "monkey", "score" : 95 }, { "grade" : 2, "name" : "sudan", "score" : 95 }, { "grade" : 2, "name" : "xiaoyan", "score" : 95 }
编写提取出各个grade的所有人名(不重复)列表:
1 db.runCommand({ mapreduce: "results", 2 map : function Map() { 3 emit( 4 {grade:this.grade}, 5 {name:this.name} 6 ); 7 }, 8 reduce : function Reduce(key, values) { 9 var reduced = {names:[]}; 10 values.forEach(function(val) { 11 var isExist = false; 12 for(var i = 0; i<reduced.names.length; i++) { 13 var cur = reduced.names[i]; 14 if(cur==val.name){ 15 isExist = true; 16 break; 17 } 18 } 19 if(!isExist) 20 reduced.names.push(val.name); 21 }); 22 return reduced; 23 }, 24 finalize : function Finalize(key, reduced) { 25 return reduced; 26 }, 27 out : { inline : 1 } 28 });
返回结果为:
1 { "_id" : {"grade" : 1}, 2 "value" :{ "names" : [null,"lekko"]} 3 }, 4 { "_id" : {"grade" : 2}, 5 "value" :{ "names" : ["xiaoyan","sudan"]} 6 }
新插入的grade=2的两条数据正常了,但grade=1的monkey却不见了!采用问题一的思维方式,肯定也是在Reduce时遍历到一个数组对象,其name值为空,也给添加进来了,monkey对象根本就没有访问到。
解决这一问题的方法是,抛弃MapReduce,改用Group:
1 db.results.group({ 2 key : {"grade":true}, 3 initial : {names:[]}, 4 reduce : function Reduce(val, out) { 5 var isExist = false; 6 for(var i = 0; i<out.names.length; i++) { 7 var cur = out.names[i]; 8 if(cur==val.name){ 9 isExist = true; 10 break; 11 } 12 } 13 if(!isExist) 14 out.names.push(val.name); 15 }, 16 finalize : function Finalize(out) { 17 return out; 18 }});
这样,便可正常取到grade=1时的name非重复集合!虽说MapReduce比Group要强大,速度也要快很多,但像这种要从大量项(超过100条)中提取数据,就有很大风险了。所以,使用MapReduce时,尽量只用到累加、累减、累乘等基本操作,不要去用++、push、delete等可能会产生风险的操作!
三、补充几个小Tips
1、使用Group或MapReduce时,如果一个分类只有一个元素,那么Reduce函数将不会执行,但Finalize函数还是会执行的。这时你要在Finalize函数中考虑一个元素与多个元素返回结果的一致性(比如,你把问题二中插入一个grade=3的数据看看,执行返回的grade=3时还有names集合吗?)。
2、查找范围时的索引效率,如果查询的是一个值的范围,它索引的优先级是很低的。比如一个表test,有海量元素,字段有'committime'、'author',建立了两个索引:author_1、committime:-1,author:1,下面的测试证明了效率:
db.test.find({'committime':{'$gt':910713600000,'$lte':1410192000000},'author':'lekko'}).hint({committime:-1,author:1}).explain() "millis" : 49163
db.test.find({'committime':{'$gt':910713600000,'$lte':1410192000000},'author':'lekko'}).explain() author_1 "millis" : 2641