基础数据准备
这里在person索引下创建了四个文档,来进行查询。
PUT person/_doc/one
{
"name":"张三",
"age":"23",
"address":"山西"
}
PUT person/_doc/two
{
"name":"李四",
"age":"24",
"address":"湖南"
}
PUT person/_doc/three
{
"name":"王五",
"age":"25",
"address":"河南"
}
PUT person/_doc/four
{
"name":"王五二号",
"age":"23",
"address":"河南"
}
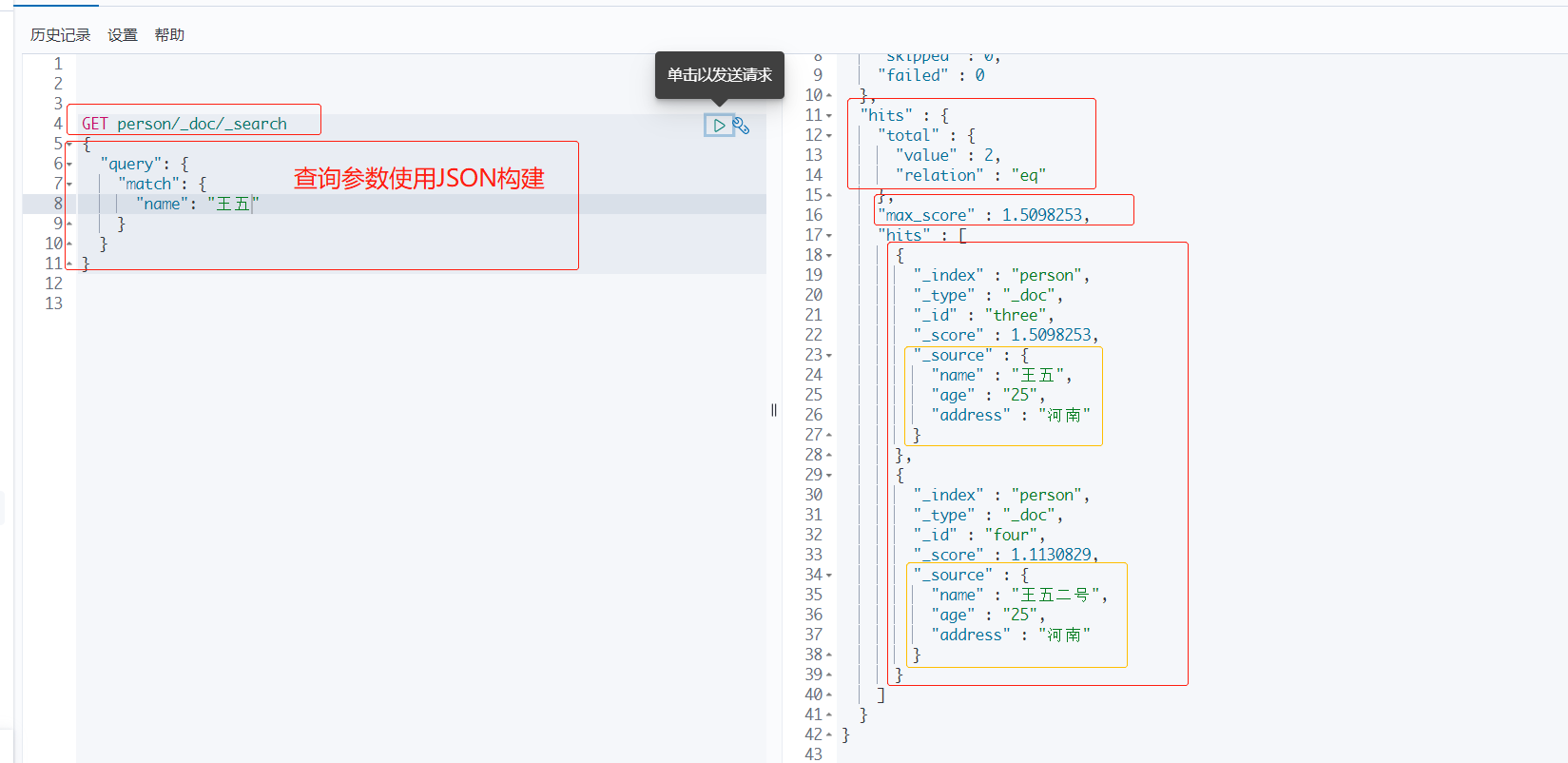
1、使用JSON构建查询参数体
描述
query : 表示查询。
match : 要匹配的条件信息。
match会使用分词器解析!先分析文档,然后再通过分析的文档进行查询。
name :要查询的信息
hits --> total
value: 查询出两条数据ralation: 关系是eq,相等
max_source : 最大分值
hits : 索引和文档的信息,查询出来的结果总数,就是查询出来的具体文档。
我们可以根据每个文档的 _source 来判断那条数据更加符合预期结果。
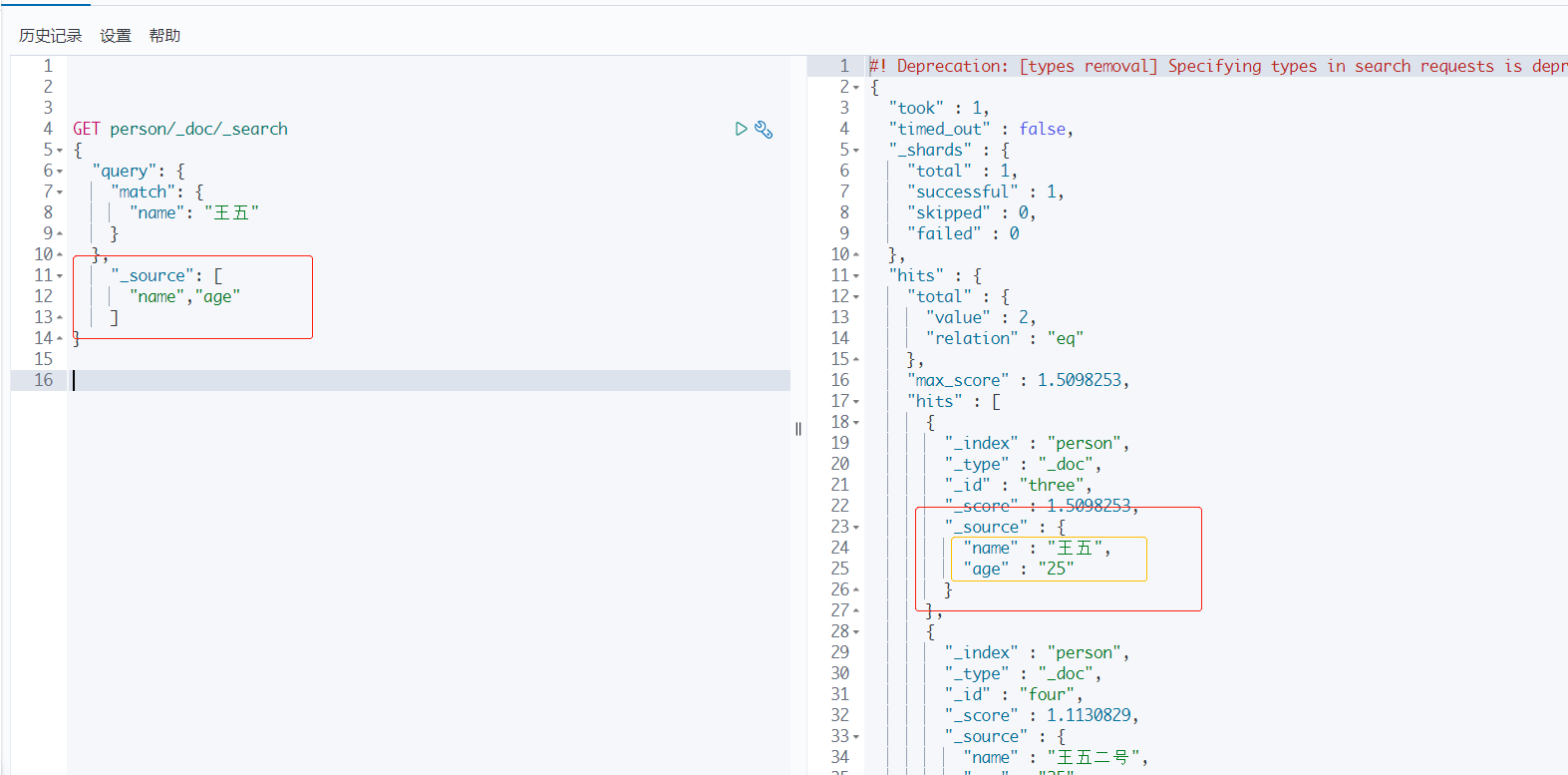
2、结果过滤,指定查询字段
3、指定字段排序
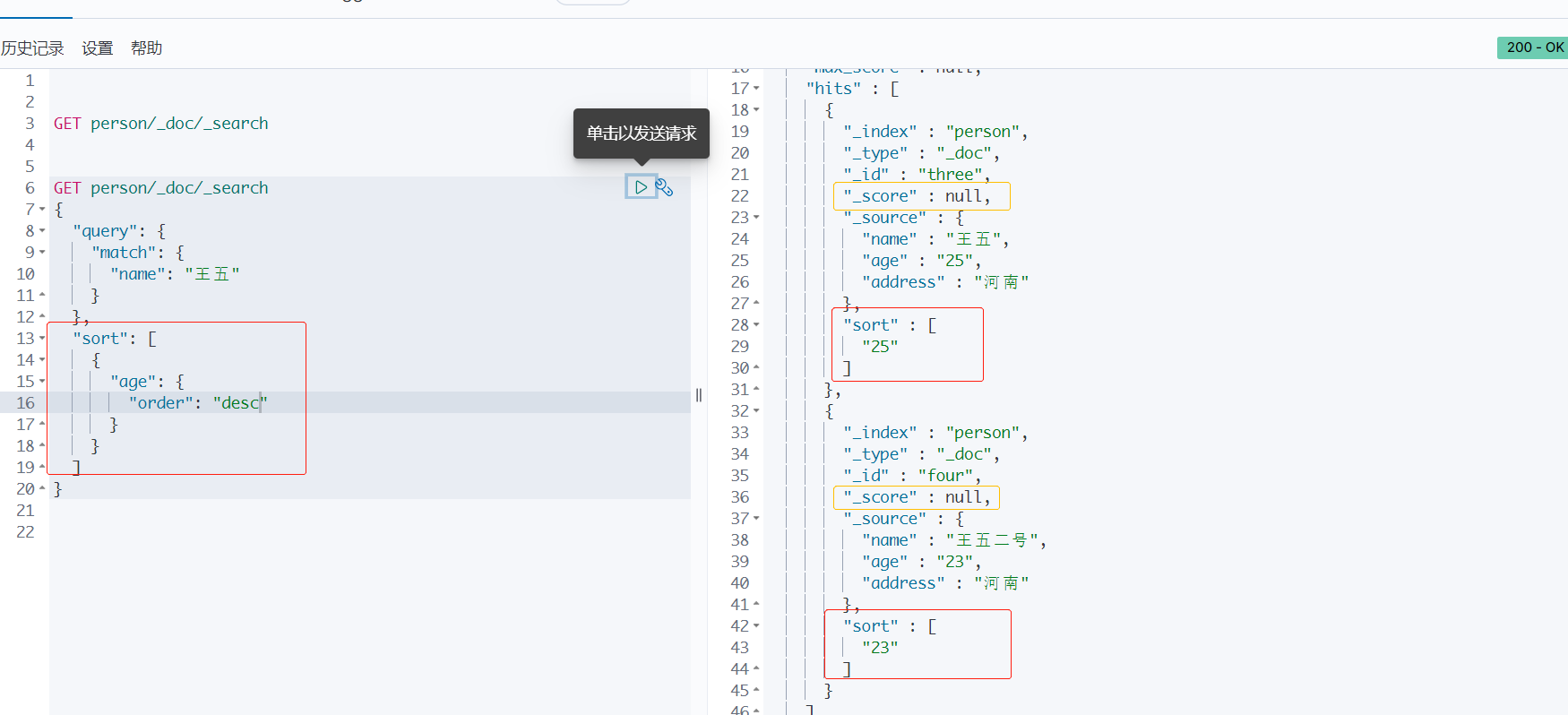
sort : 指定字段排序,升序 :asc , 倒序 :desc。
age : 根据年龄倒序排列。
_source : 由于指定了排序规则,所以 _source 为null。
4、分页
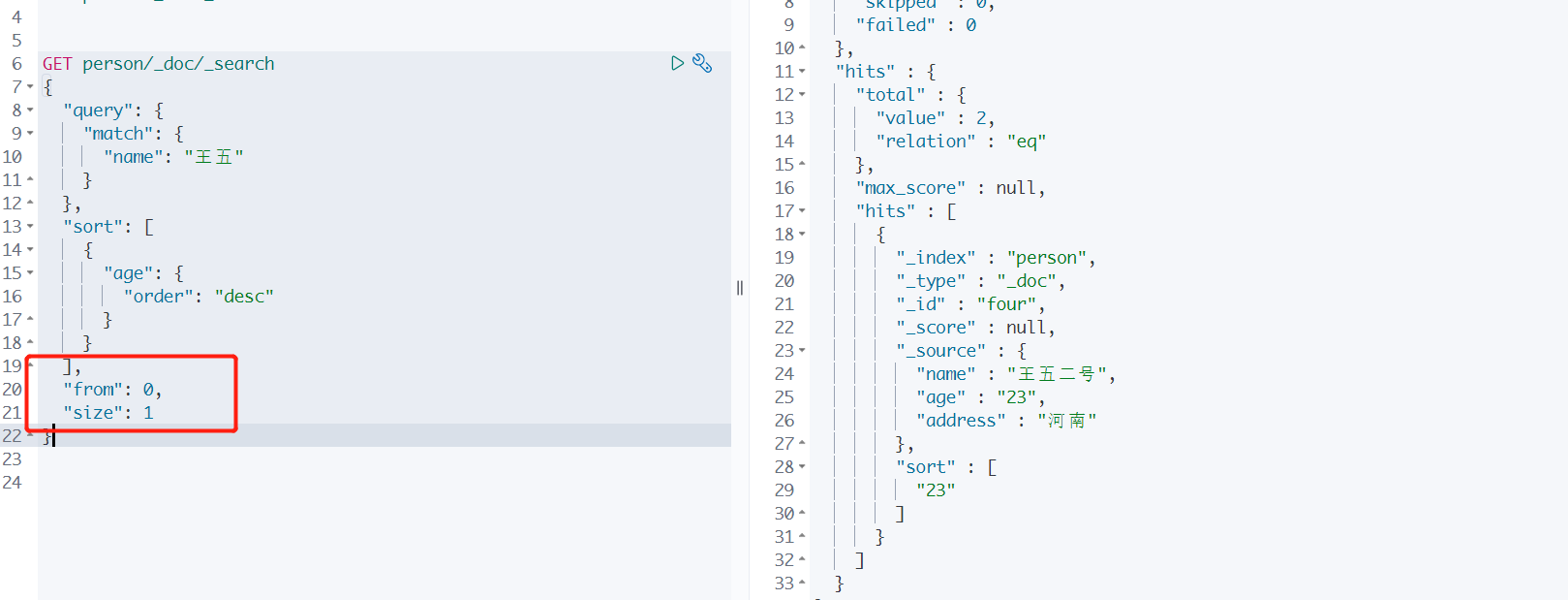
from : 起始页,下标从0开始。
size : 每页显示多少条
5、多条件查询
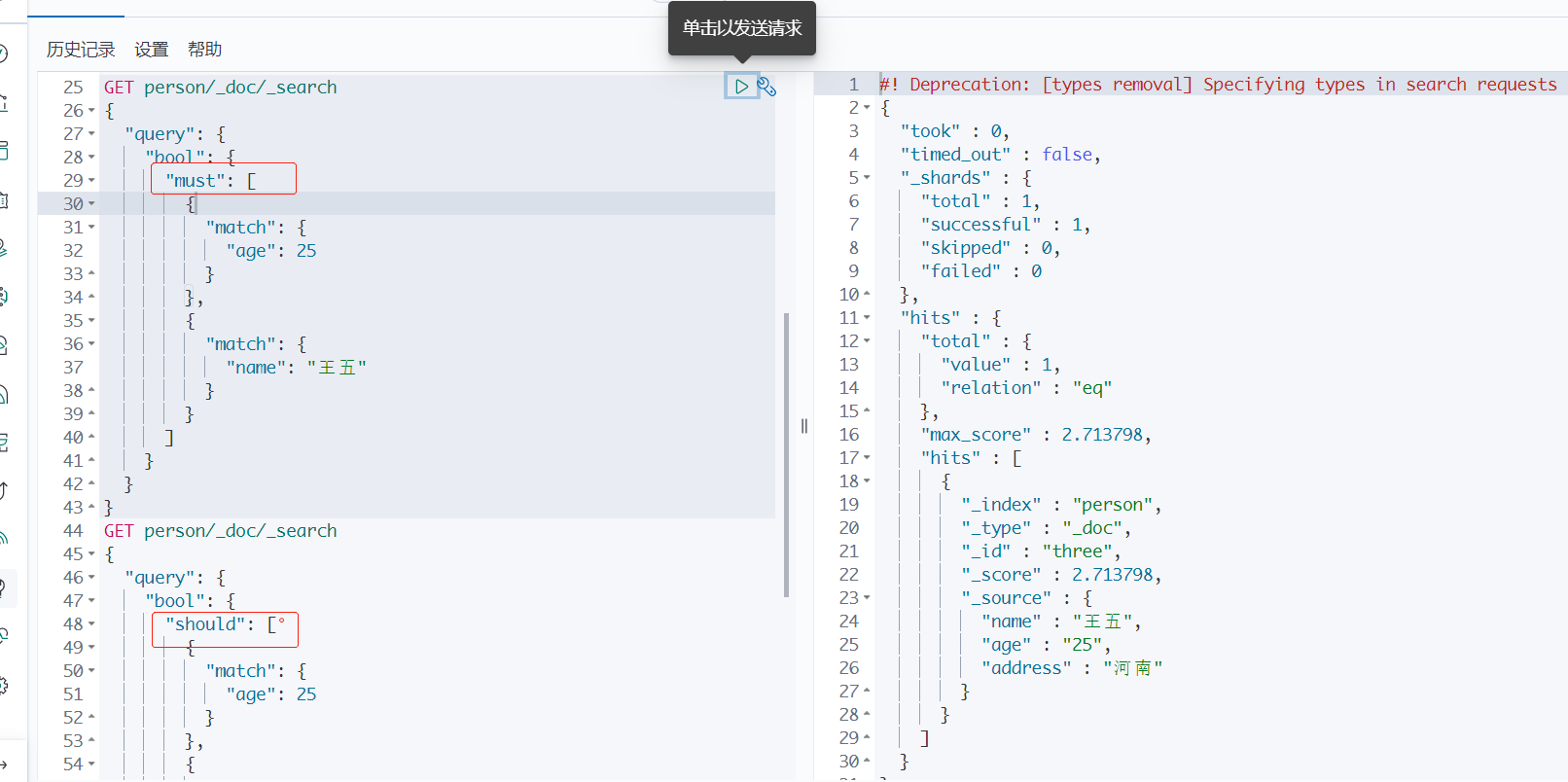
使用 bool 和 must、should 多条件查询。
must相当于sql中的and,should相当于sql中的or。
6、不包含某个条件
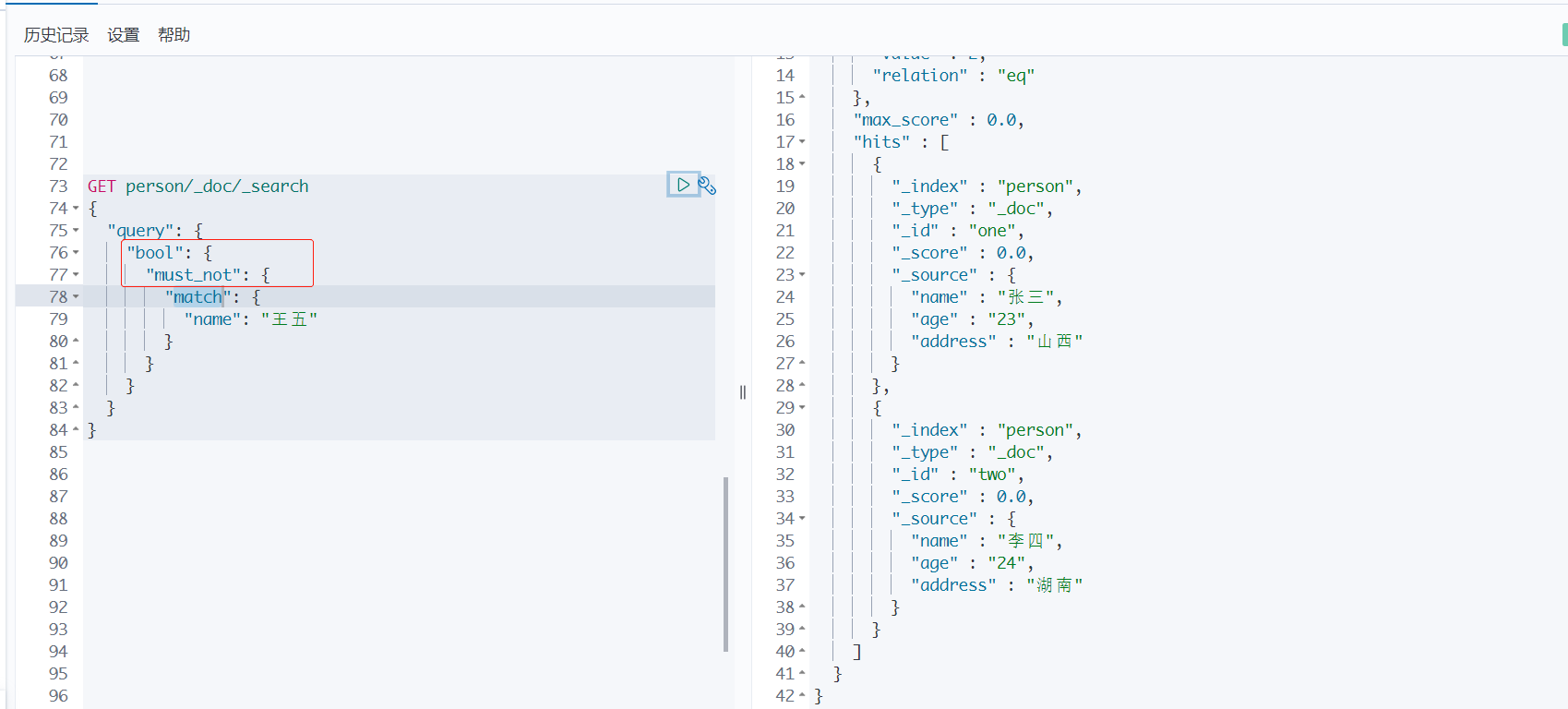
must_not :查询name不包含王五的人。
7、使用 filter 进行数据过滤
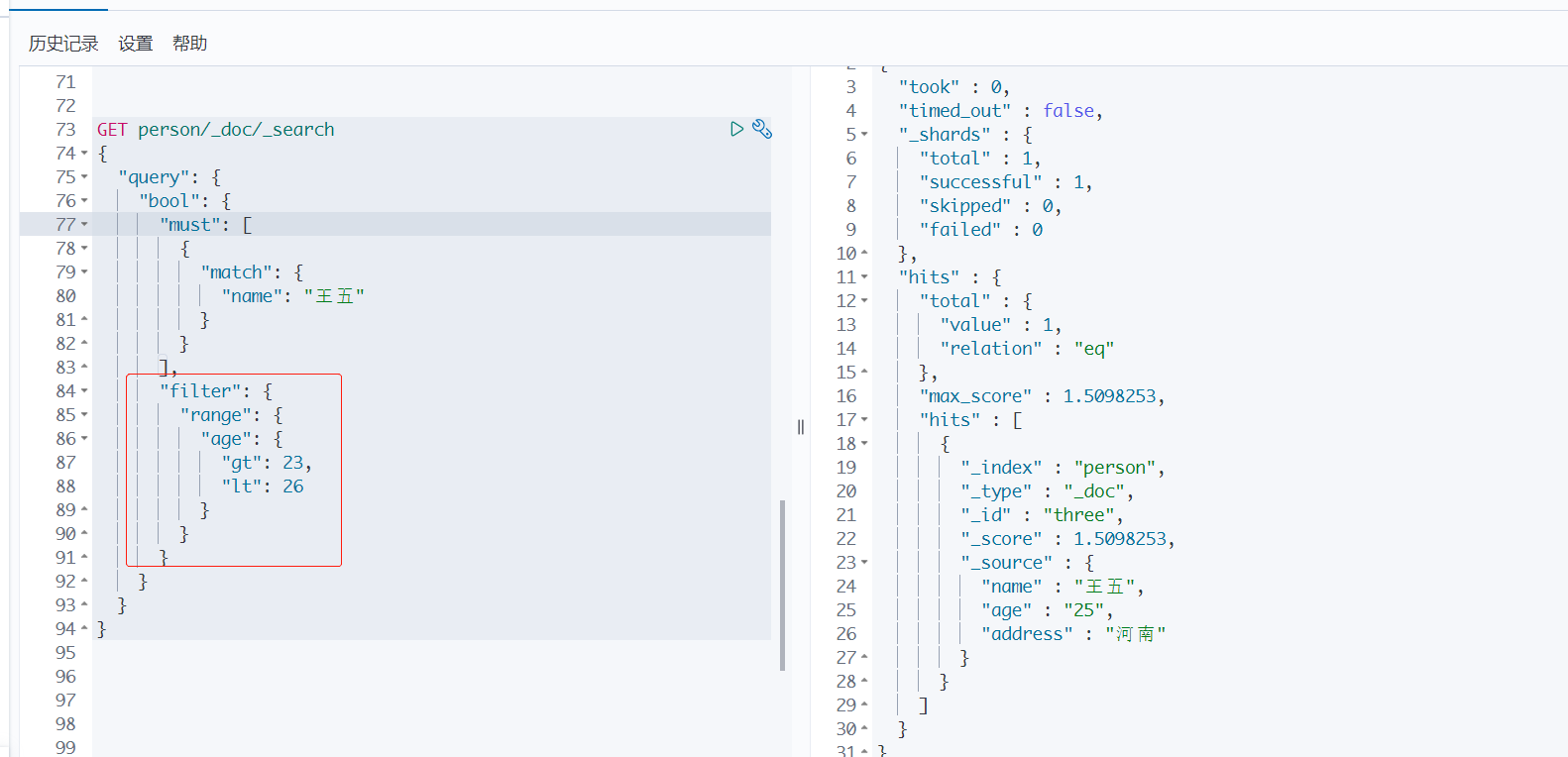
过滤出大于23岁小于26的人数据。
gt: 大于gte: 大于等于lt:小于lte:小于等于
8、精确查询
准备数据
--创建item索引库,指定字段类型
PUT item
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "keyword"
}
}
}
}
PUT item/_doc/ITEM001
{
"name":"java从入门到吃土",
"description":"java从入门到吃土介绍"
}
PUT item/_doc/ITEM002
{
"name":"java从入门到放弃",
"description":"java从入门到放弃介绍"
}
GET item/_doc/_search
使用 term 进行精确查询:
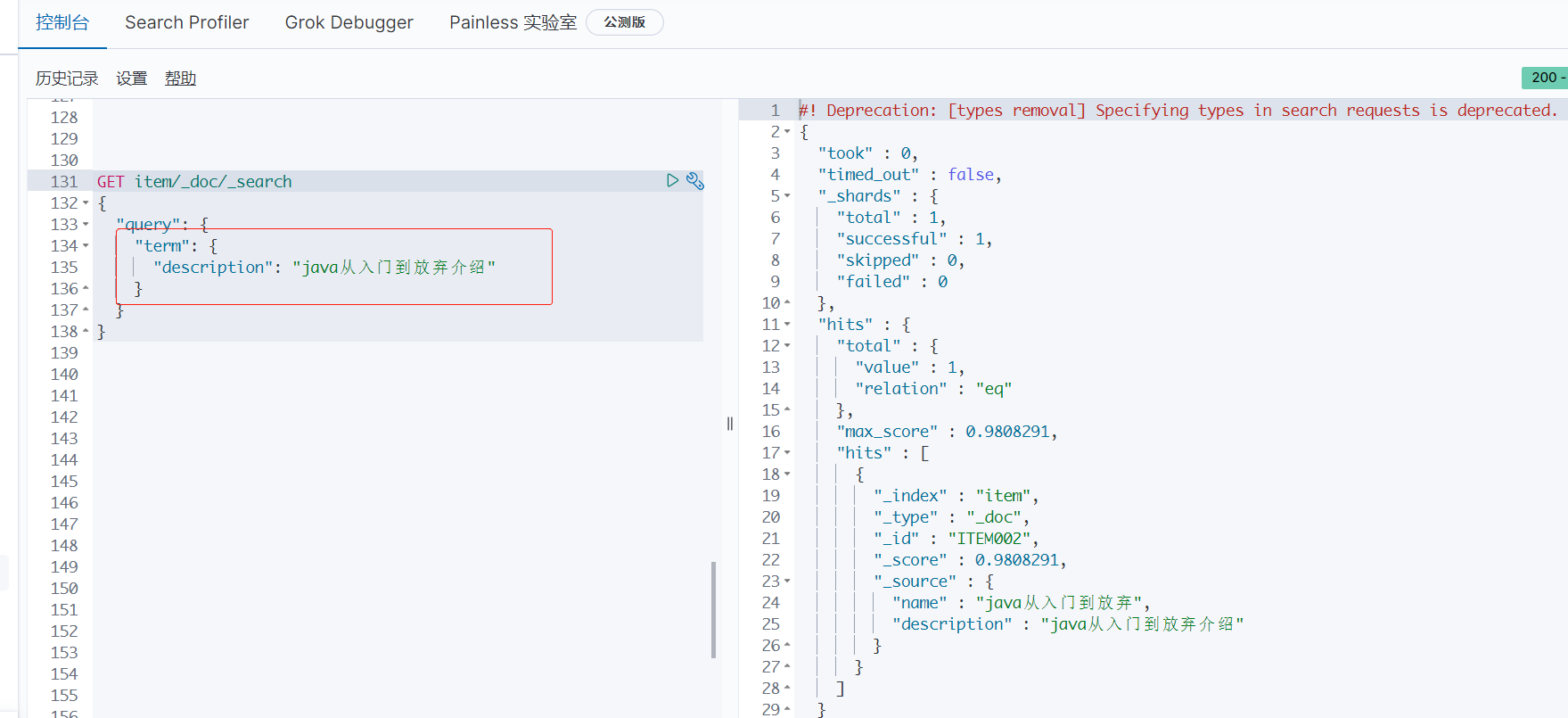
term 标签是直接通过倒排索引指定的词条进行精确查询的!
关于分词:
term: 直接查询精确的值match: 会使用分词器解析!先分析文档,然后再通过分析的文档进行查询
9、高亮查询
使用 highlight 高亮查询并且自定义高亮字段。
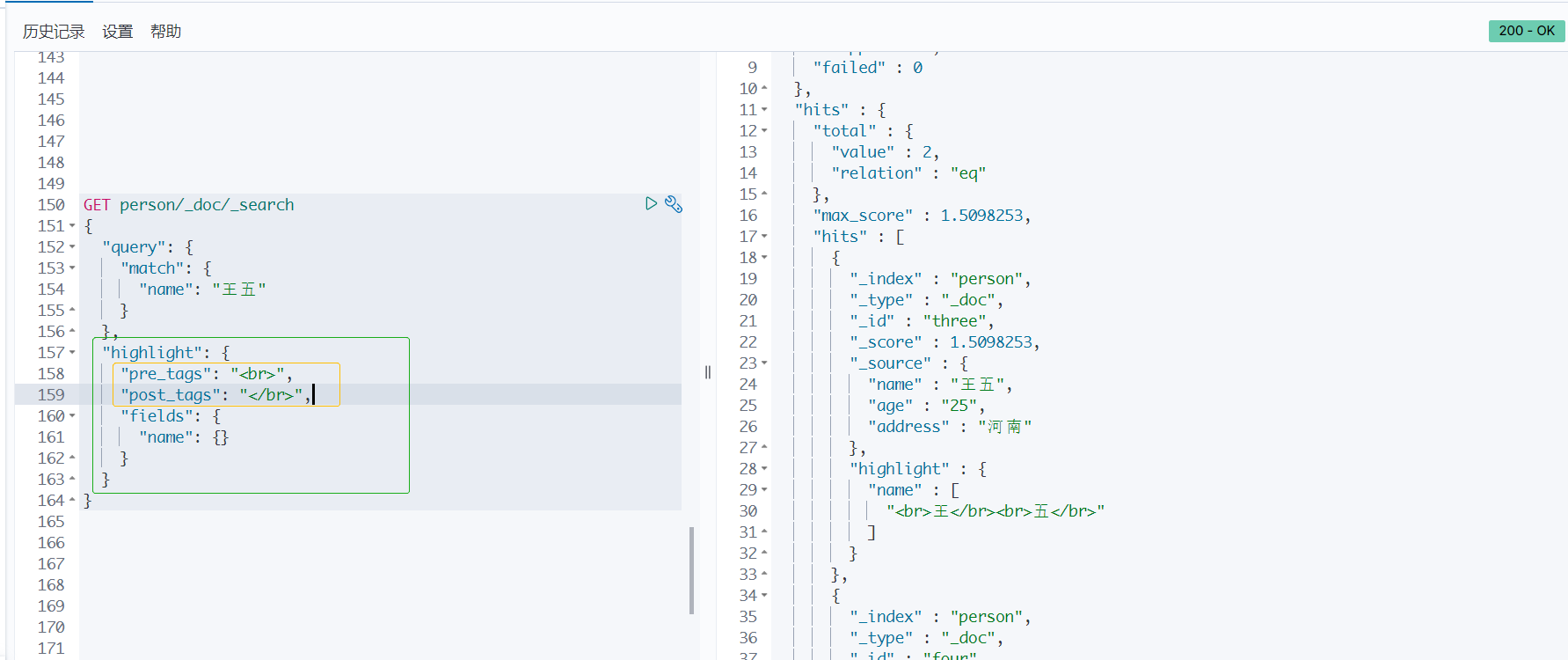
将查询条件王五高亮显示,并且自定义高亮标签。