前面的文章,我们分析了压测的时机,压测的指标,那么这次呢,我们来看下,我们这些压测的指标,常见的都需要性能压测中观测点,有了对指标的梳理 ,我们才有重点的关注点,下面,我列举一些常见的指标。
•服务器cpu
•服务器内存
•服务器load
•数据库连接池
•Redis 连接池
•Tomcat连接池
•TPS
•网络带宽
•响应时间
•GC
•错误率
这些都是一些常见的指标了,当然了,还有一些其他的指标,需要我们根据自己的实际的业务去选择,这些关注点,大家都可以去搭建一些监控平平台,展示分析使用,例如火焰图,zabbix,Grafana,InfluxDB,prometheus等工具。都可以成为我们监控分析的利器。
这些工具呢,都是一些在压测中常见呢, 我们来介绍下火焰图
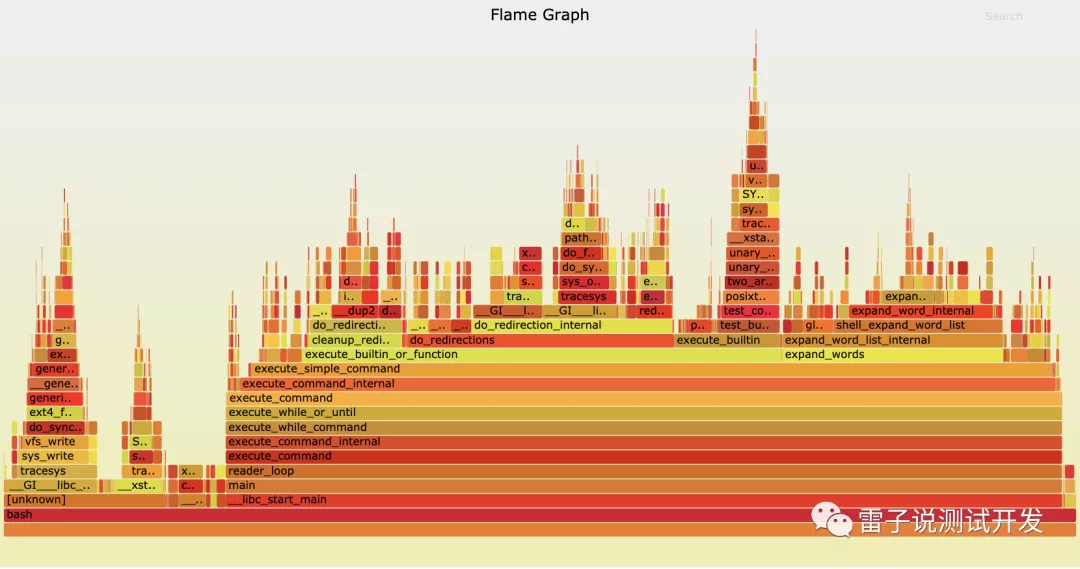
这是官方的github给我们的。
-
由底部到顶部可以追溯一个唯一的调用链,下面的方块是上面方块的父调用。
-
同一父调用的方块从左到右以字母序排列。
-
方块上的字符表示一个调用名称,括号内是火焰图指向的调用在火焰图中出现的次数和这个方块占最底层方块的宽度百分比。
-
方块的颜色没有实际意义,相邻方块的颜色差只为了便于查看。
火焰图则适合用在:
-
代码循环分析:如果代码中有很大的循环或死循环代码,那么从火焰图的顶部或接近项部的地方会有很明显的”平顶”,表示代码频繁地在某个线程栈上下切换。但需要注意的是,如果循环的总耗时不长,在火焰图上不会很明显。
-
IO 瓶颈/锁分析:在我们的应用代码中,我们的调用普遍都是同步的,也就是说在进行网络调用、文件 I/O 操作或未成功获得锁时,线程会停留在某个调用上等待 I/O 响应或锁,如果这个等待非常耗时,会导致线程在某个调用上一直 hang 住,这在火焰图上表现得会非常清晰。与此相对的是,我们应用线程构成的火焰图无法准确地表达 CPU 的消耗,因为应用线程内没有系统的调用栈,在应用线程栈 hang 住时,CPU 可能去做其他事了,导致我们看到耗时很长,而 CPU 却很闲。
-
火焰图倒置分析全局代码:火焰图倒置有时也会很实用,如果我们的代码 N 个不同的分支都调用某一方法,倒置后,所有栈顶相同的调用被合并在一块,我们就能看出这个方法的总耗时,也就很容易评估出优化这个方法的收益。
zabbix 监控利器,官网是:
https://www.zabbix.com/
我们来看下官方给我们的效果图
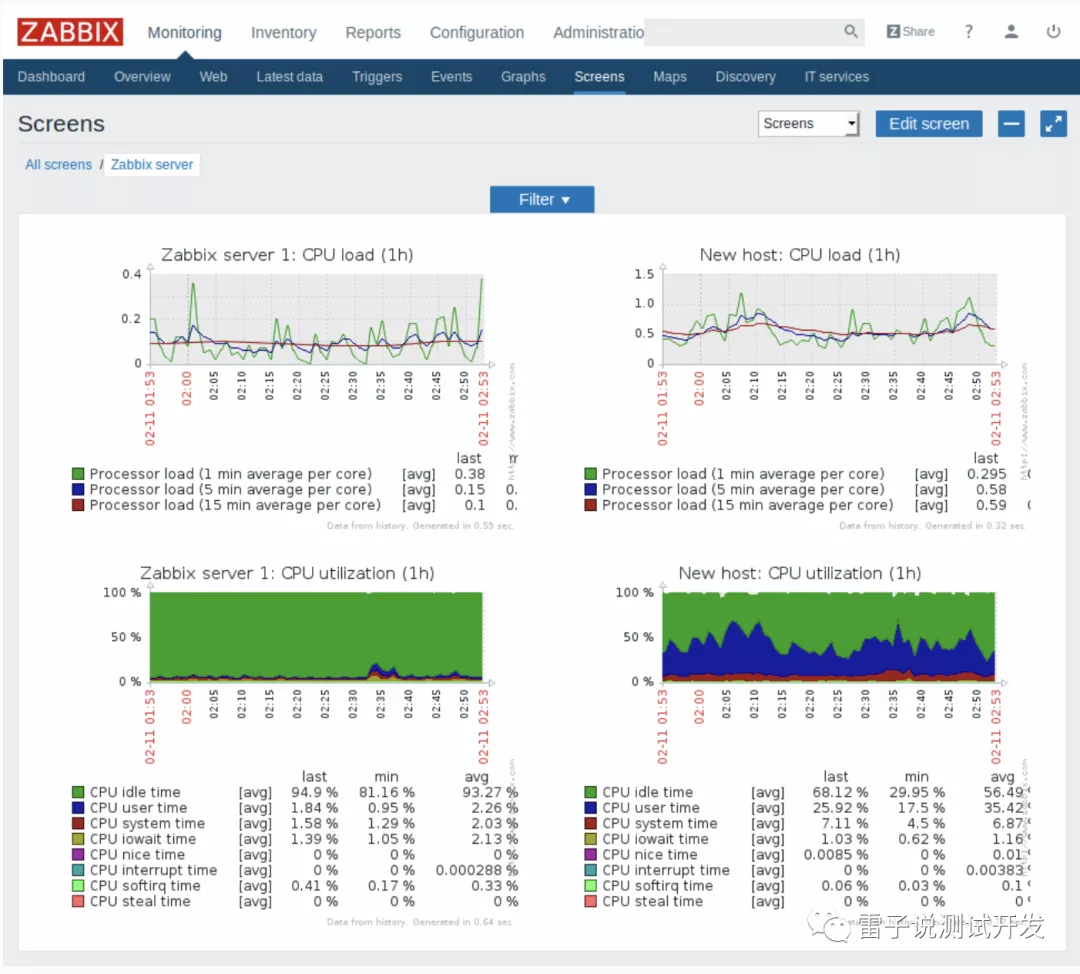
zabbix由2部分构成,zabbix server与可选组件zabbix agent。
Zabbix主要功能:
- CPU负荷
- 内存使用
-磁盘使用
- 网络状况
- 端口监视
- 日志监视。
我们可以用它来做我们服务端的数据收集。
Grafana
美观、强大的可视化监控指标展示工具。
https://grafana.com/docs/grafana/latest/installation/ 官网。
我们来看下最后的效果,这是官网给的效果图
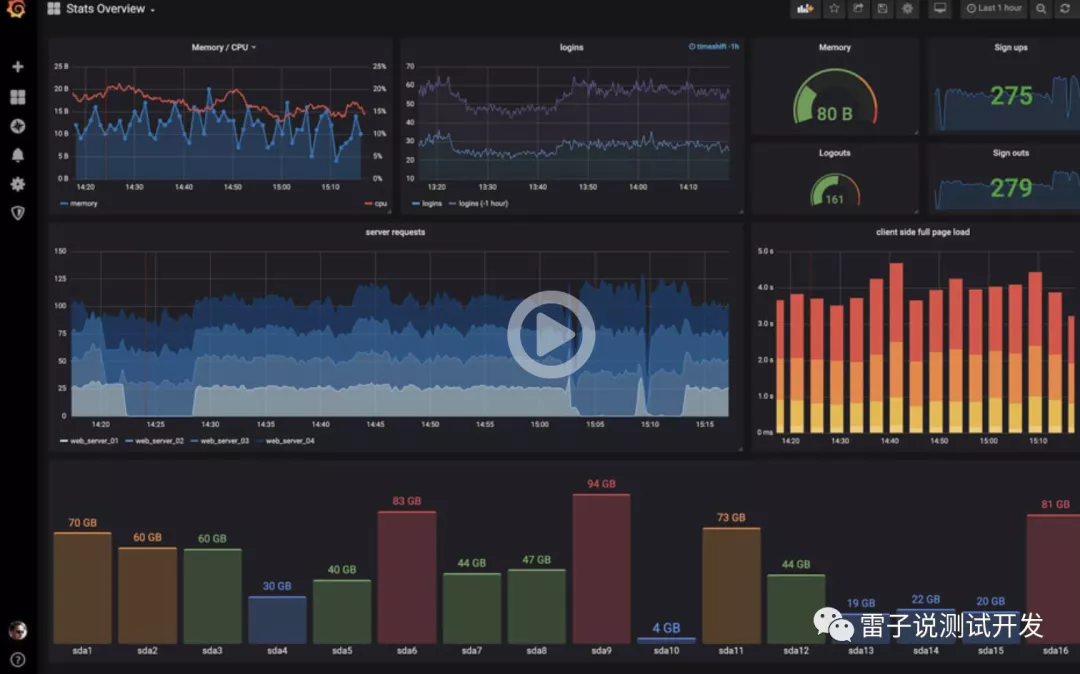
在实际中,我们可以根据我们的实际的需求,去完成我们需要的平台的搭建。