其实如果之前都做的很到位的话,那么再加上APM工具(dynaTrace等),监控到非常细节,那么我们跑一个业务,我们就能完全清楚的知道每个请求的时间,也能知道请求所产生sql的时间,这样你自然而然都知道时间耗在哪里了,直接就能去调节时间消耗最多的请求了。
对于系统调优分为前后端调优,前端之前有一篇专门讲过,现在有些项目用的是胖前端(前端带有数据库,请求数据不请求后端,直接请求前端数据库,前端数据库会定时刷新同步数据库,其实这个主要目的就是减少对后端的请求),这里我们主要说一下后端,后端就包括web服务器、app(应用)服务器、DB。也因为基本上所有性能问题都是后端的原因。
影响最大的调优:后端影响最大的性能问题都是DB的问题。那么解决数据库的性能问题一般都是什么呢?
- 解决IO问题,数据文件读取速度的提升,比如硬盘变为ssd。
- 如果不是IO的问题呢?可以解决读写分离,对于读可以采用redis.
- 那么如果还不行呢?就要考虑优化sql了,通过sql的执行计划(看sql的执行过程及时间)->判断是否有索引->分析影响最大和最易调优和组合(可以冗余属性,对于多表查询的数据可以适当加多一个字段在表里存放,尽量避免多表查询)
最易调优:
- 代码调优(一般代码的开销是cpu),因为代码是自己写的,所以最容易调优。
- 配置和应用平台的调整。
组合调优(让系统整体都没有明显瓶颈):
- 有资源不用是浪费;
- 无节制的调优是毫无意义的,要考虑性价比。
性能调优模型必讲->理发师模型
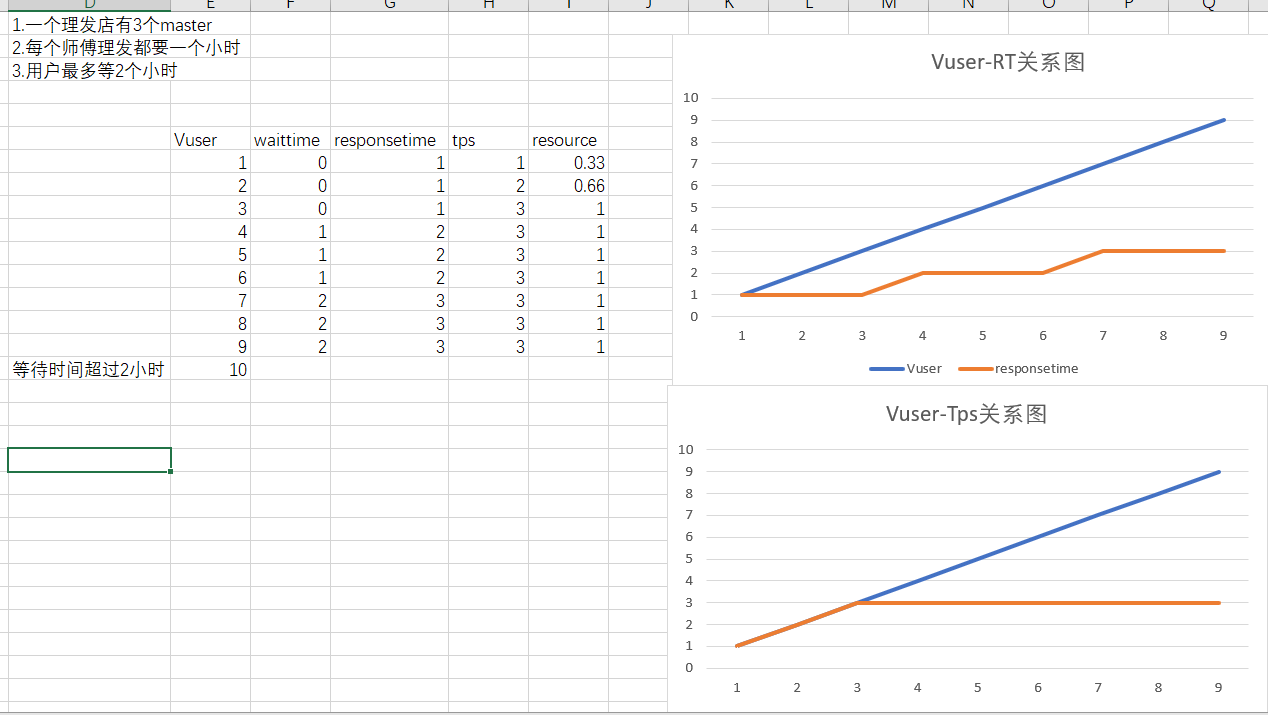
通过数据我们可以做出两张关系图,第一张是用户数和响应时间的图,这边我们想一想为什么响应时间会持续上升呢?是不是处理能力一定的情况下,出现了排队的情况,类似于cpu队列。第二个图是用户和TPS的关系图,可以知道,处理能力恒定,一旦处理能力饱满开始排队,响应时间处理按照处理时间开始堆叠。其实理发师模型就是理想系统的原型图,特别适合我们去分析研究性能问题。
那么好了,如果我们想要调优,本质上就是提升资源,也就是理发师的个数对不对?那么假设增加理发师人数10倍,那么处理能力就会提升10倍吗?这个不一定,因为出现了多个理发师的时候,就会出现理发师调度的问题?是不是就需要管理人员?那么就意味着部分人员不能做理发师需要单独拿出来做管理或者其他,那么从原则上来讲提升了10倍的人数后处理能力会低于之前的10倍处理能力吧。所以在理发师人数增多的过程中,刚开始由于要进行任务调度,有可能tps出现稍微下滑的现象。而且理发师增多,那么队列也就能排的越长,那么出现各种问题的概率也就越大。那么为了避免这个问题怎么办呢?可以通过异步队列(比如MQ)进行处理。
在做性能测试时候,
- 我们一般会先做单用户串行负载,如果长时间跑下来响应时间没有变化,那么说明不存在排队或者资源泄露的问题。(下图的A点)
- 然后再做一个理想的小用户性能测试,如果此时响应时间随着用户上升也上升了一段时间后又平稳说明了什么呢?此时我们需要查看TPS,如果响应时间上升的时候,TPS也上升又说明了什么呢?那么是不是有可能对于一个业务有多个因素影响,其中一个因素比较慢,但是其他的都比较快,所以总体来讲是慢的但是tps依旧没到瓶颈点。下图是常见的用户数和响应时间还有TPS的关系图,在我们性能测试过程中出现的三者关系图都可以参考这个图来看,B点就是最大处理能力的点,C点是客户无法接受的响应时间点。
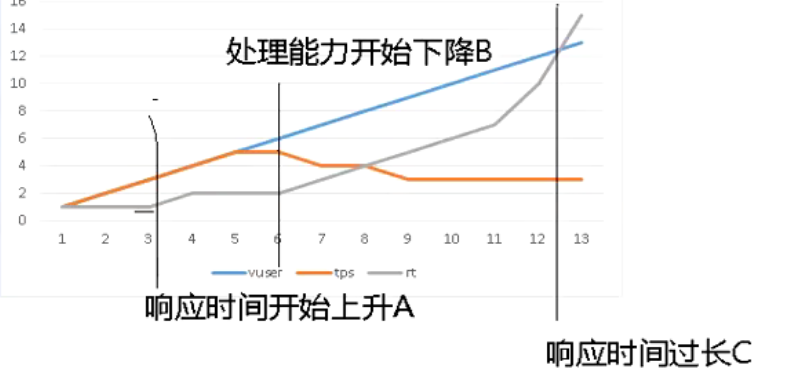
如何判断调优,实际上就是A、B、C三点的右移,在同场景下如果结果右移证明调优成功。不过大家也要知道不是负载最高就一定是有瓶颈,因为每一种架构都有该架构的性能上限的。
我们平时做性能的时候,一般都会做事务对吧,以登陆为例,假设我们登陆TPS为100时,响应时间为5s,那么我们知道是哪里用了5秒吗?实际上这只是一个时间的总和(前端、应用端、数据库端、网络等时间总和),那么此时我们就需要拆分这个时间,怎么做呢?还记得我之前说的APM监控吗?一般的APM都是很贵的,所以一般需要我们自己打点,我们可以让开发帮我们在做每一件事情都记录时间点,假设登陆,那么我们可以记录总的后端处理时间,然后让开发呈现在页面或者以其它形式给我们,然后再对数据库处理返回记录一个时间,那么后端的应用端和数据库端的时间我们就能差不多知道了。如果开发将时间抛出在了界面,那么我们就可以通过关联先拿到这个值,然后再通过lr_user_data_point将该时间值记录下来,在场景测试中,我们可以查看User Defined Data Points可以进行查看。(如果不清楚lr函数使用可以百度)
其实上面的打探针操作就相当于我们做了个小的APM,如果记录的时间差不丢界面的话也可以丢日志里面,然后我们把日志丢influxdb里面进行排序读取出来也是可以的。
性能测试执行:
- 入手
- 环境(软硬件、数据、参数)
- 记录环境、数据
- 跑一下(看看系统大概性能,了解整体系统情况)
- 简单分析(前端工具,刷新看看性能,评估瓶颈点和响应时间)
- 数据整理(分析大概的瓶颈点)
- 重现定位问题(层层探针,定位基于监控)
- 调优(记住调优不是测试的工作,如何协调开发是调优的关键以及自己的见识决定了调优)
- 报告(思路清晰,测试目的决定报告)
更多调优的具体思路可以查看下阿里云的测试分析及调优:https://help.aliyun.com/document_detail/29342.html?spm=a2c4g.11186623.6.612.5oUhZg