前言:由于梯度消失的存在,在实际应用中,RNN很难处理长距离的依赖。RNN的一种改进版本:长短时记忆网络(Long Short Term Memory Network, LSTM)。 LSTM就是用来解决RNN中梯度消失问题的。
怎么解决的呢?
LSTM增加了一个可以相隔多个timesteps来传递信息的方法。想想有一个传送带在你处理sequences时一起运转。每个时间节点的信息都可以放到传送带上,或者从传送带上拿下来,当然你也可以更新传送带上的信息。这样就保存了很久之前的信息,防止了信息的丢失。
LSTM
一、概述
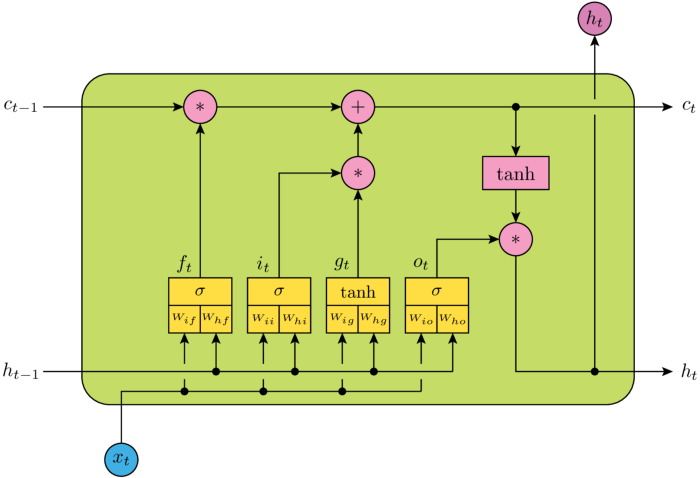
如果把LSTM当成黑盒子看待,可以分为以下关键变量(参考上图):
- 输入:(h_{t-1}) (t-1时刻的隐藏层向量)和 (x_t)(t时刻的特征向量)
- 输出:(h_t)(加softmax即可作为真正输出,否则作为隐藏层)
- 主线/记忆: (c_{t-1}) 和 (c_t)
LSTM分为三个部分:
- 遗忘门:决定了上一时刻的单元状态(c_{t-1})有多少保留到当前时刻(c_t)。如果之前单元状态中有主语,而输入中又有了主语,那么原来存在的主语就应该被遗忘。concatenate的输入和上一时刻的输出经过sigmoid函数后,越接近于0被遗忘的越多,越接近于1被遗忘的越少。
- 输入门:决定了当前时刻网络的输入(x_t)有多少保存到单元状态(c_t);即哪些新的状态应该被加入。新进来的主语自然就是应该被加入到细胞状态的内容,同理也是靠sigmoid函数来决定应该记住哪些内容。
- 输出门:控制单元状态(c_t)有多少输出到LSTM的当前输出值(h_t)。根据当前的状态和现在的输入,确定输出的比例。
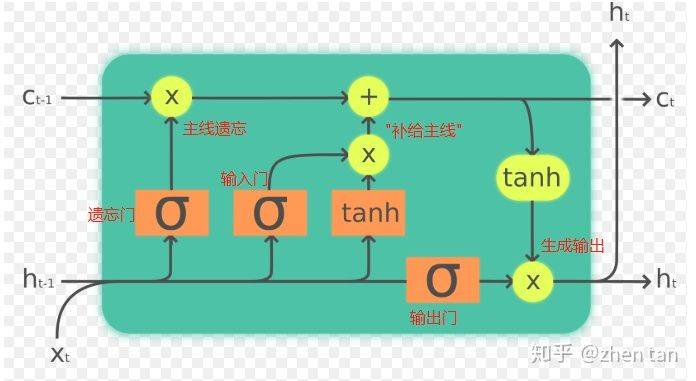
- (h_{t-1})和(x_t)联合起来作为最终的输入数据。
- (c_{t-1})和(c_t)始终与外界隔离开来,显然是作为LSTM记忆或者主线剧情的存在。
- (f_t)为遗忘门的输出。主线进来后,首先受到遗忘门的衰减作用。
- (i_t)为输入门的输出。输入门控制“补给大小”,给主线补充能量生成全新的主线。
- (o_t)为输出门的输出,其经过变换得到当前时刻的隐层向量(h_t),同时也为当前时刻的输出。
二、三个门的计算公式,在时间步t。
假设1个batch,输入为[1,length,d]。length是预定义的最大序列长度, (d)是序列中每个step的维度。隐层神经元个数为(h)。
- 遗忘门部分
(x_t = [1,d]),(h_{t-1} = [1,h]),则遗忘门权重矩阵的形状 (W_f = [d+h,h]),遗忘门的输出(f_t = [1,h])
- 输入门部分
输入门矩阵(W_i = [d+h,h]),输入门矩阵的输出(i_t =[1,h]);
补给矩阵(W_g=[d+h,h]),补给输出(g_t=[1,h]);
补给主线(c_t=[1,h])。
- 输出门部分
输出门矩阵(W_o = [d+h,h]),输出门输出(o_t=[1,h])
最终的输出(h_t=[1,h])
三、LSTM参数的数量
LSTM参数应该指包括embedding层的整个网络的参数的数量。
LSTM的参数计算公式:
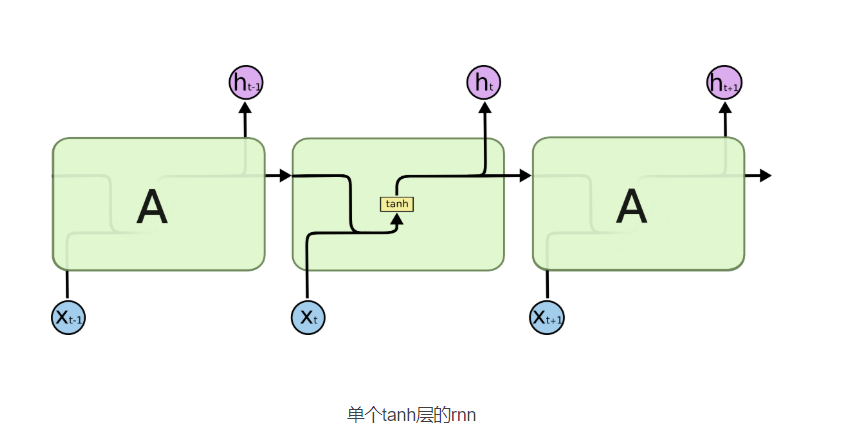
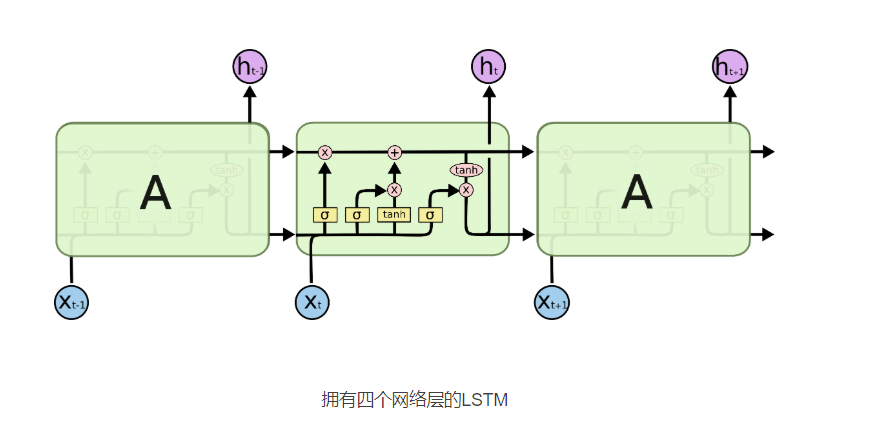
四、LSTM 和 RNN 结构对比
LSTM实现:时间序列预测
数据集:AirPassengers。1949 到 1960 一共 12 年,每年 12 个月的数据,一共 144 个数据,单位是 1000
数据集经过处理后得到训练样本
train_x : array([[x1,...x12],...]) 每个样本为长度为12的数组,代表连续12个月份的乘客人数。因为输入数据形状为: [batch,时间步长,每个时刻的维度]
train_y : array([[y1],...]) 因为是时间序列预测,标签为一个具体的数值。
一、构建LSTM模型
'''定义LSTM cell组件,该组件将在训练过程中被不断更新参数'''
def LstmCell():
lstm_cell = rnn.BasicLSTMCell(HIDDEN_SIZE, state_is_tuple=True)#
return lstm_cell
'''定义LSTM模型'''
def lstm_model(X, y):
# 输入x的shape 为: (?, 1, 12),表示 (batch_size,序列长度为1,序列每步的维度为12)
'''以前面定义的LSTM cell为基础定义多层堆叠的LSTM,我们这里只有1层'''
cell = rnn.MultiRNNCell([LstmCell() for _ in range(NUM_LAYERS)])
'''将已经堆叠起的LSTM单元转化成动态的可在训练过程中更新的LSTM单元'''
output, _ = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
# output 的shape为: (?, 1, 40),表示 (batch_size,序列长度为1,隐层大小为40)
'''根据预定义的每层神经元个数来生成隐层每个单元'''
output = tf.reshape(output, [-1, HIDDEN_SIZE])
'''通过无激活函数的全连接层计算线性回归,并将数据压缩成一维数组结构'''
predictions = tf.contrib.layers.fully_connected(output, 1, None)
'''统一预测值与真实值的形状'''
labels = tf.reshape(y, [-1])
predictions = tf.reshape(predictions, [-1])
'''定义损失函数,这里为正常的均方误差'''
loss = tf.losses.mean_squared_error(predictions, labels)
'''定义优化器各参数'''
train_op = tf.contrib.layers.optimize_loss(loss,
tf.contrib.framework.get_global_step(),
optimizer='Adagrad',
learning_rate=0.6)
'''返回预测值、损失函数及优化器'''
return predictions, loss, train_op
二、训练所用的模块
learn = tf.contrib.learn
regressor = SKCompat(learn.Estimator(model_fn=lstm_model, model_dir='Models/model_2'))
tf.contrib.learn.Estimaor(模型,保存路径),以sklearn的方式定义了一个模型,可以调用fit和predict方法完成训练和预测。
Estimator里面还有一个叫SKCompat的类,如果使用x,y而不是input_fn来传参数的形式,需要用这个类包装一下。这里我们使用了x,y的输入形式。
三、训练和预测
'''以仿sklearn的形式训练模型,这里指定了训练批尺寸和训练轮数'''
regressor.fit(train_X, train_y, batch_size=BATCH_SIZE, steps=TRAINING_STEPS)
'''利用已训练好的LSTM模型,来生成对应测试集的所有预测值'''
predicted = np.array([pred for pred in regressor.predict(test_X)])
参考资料
- 快速理解LSTM,从懵逼到装逼
https://zhuanlan.zhihu.com/p/88892937 - 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
https://zybuluo.com/hanbingtao/note/581764 - (数据科学学习手札40)tensorflow实现LSTM时间序列预测
https://www.cnblogs.com/feffery/p/9130728.html