全文基于Python 2.7 macOS 10.12.2
werkzeug是Python实现的WSGI规范的使用函数库。什么是WSGI?如何理解CGI,WSGI 网上的说明很多,在文章的开始,我想要强调两点
- WSGI是一种服务器和客户端交互的接口规范
- 理解web组件:client, server, and middleware.
正如werkzeug官网Werkzeug上所说,werkzeug使用起来非常简单,但是却非常强大。关于使用简单的这个特性,官网给了一段示例代码。
from werkzeug.wrappers import Request, Response @Request.application def application(request): return Response('Hello World!') if __name__ == '__main__': from werkzeug.serving import run_simple run_simple('localhost', 4000, application)
运行起来以后,打开我们的浏览器输入127.0.0.1:4000就可以看到

一个web应用的本质,实际就是:
浏览器(client)发送一个请求(request) ——> 服务器(server)接收到请求 ——> 服务器处理请求 ——> 返回处理的结果(response) ——> 浏览器处理返回的结果,显示出来。
再看这段代码,开始的func application(),非常的容易理解。函数在server端,接收了来自client的一个request,经过内部的处理以后返回了一个response。但是如果看过其他WSGI教程(比如wsgi接口)的朋友应该会感觉到奇怪,这个函数和别的地方举例的不太一样,因为WSGI要求web开发者必须实现的函数是这个样子的
def application(environ, start_response): response_body = "<h1>Hello World</h1>" header = [('Content-Type', 'text/html')] status = "200 OK" start_response(status, header) print "environ http request method:"+environ['REQUEST_METHOD'] return [response_body]
我们的函数必须接受两个参数environ,start_response。environ是一个保存了请求的各项信息的字典,而start_response是一个func,我们可以用它来给client端返回状态码和response headers。最后return我们真正想要返回的数据。但是werkzeug的这段示例代码却简化了很多,原因就在这个函数的装饰器上 **@Request.application **


@classmethod def application(cls, f): """Decorate a function as responder that accepts the request as first argument. This works like the :func:`responder` decorator but the function is passed the request object as first argument and the request object will be closed automatically:: @Request.application def my_wsgi_app(request): return Response('Hello World!') As of Werkzeug 0.14 HTTP exceptions are automatically caught and converted to responses instead of failing. :param f: the WSGI callable to decorate :return: a new WSGI callable """ #: return a callable that wraps the -2nd argument with the request #: and calls the function with all the arguments up to that one and #: the request. The return value is then called with the latest #: two arguments. This makes it possible to use this decorator for #: both methods and standalone WSGI functions. from werkzeug.exceptions import HTTPException def application(*args): request = cls(args[-2]) with request: try: resp = f(*args[:-2] + (request,)) except HTTPException as e: resp = e.get_response(args[-2]) return resp(*args[-2:]) return update_wrapper(application, f)
源码可以看出,**@Request.application **拦截了func的倒数第二个参数(也就是environ),构建了request对象;然后把原参数移除了倒数两个参数(environ和start_response)以后和request对象一起传入了我们自己实现的func application();调用func application()返回的对象,传入原参数的倒数两个。把最后的执行结果返回。
看到这里,这个func先放一边。我们来看看func run_simple()。这是这个简单web应用的入口函数。在werkzeug/serving.py文件的开始,有这样一段注释
...
There are many ways to serve a WSGI application. While you're developing
it you usually don't want a full blown webserver like Apache but a simple
standalone one.
...
For bigger applications you should consider using werkzeug.script
instead of a simple start file.
大多数情况下,我们并不需要一个大而全的webserver。比如,Apache。一个简单而独立的webserver就够了。很显然,我们今天所讨论的run_simple()就是为此场景而服务的.
def run_simple(hostname, port, application, use_reloader=False, use_debugger=False, use_evalex=True, extra_files=None, reloader_interval=1, reloader_type='auto', threaded=False, processes=1, request_handler=None, static_files=None, passthrough_errors=False, ssl_context=None): def log_startup(sock): display_hostname = hostname not in ('', '*') and hostname or 'localhost' if ':' in display_hostname: display_hostname = '[%s]' % display_hostname quit_msg = '(Press CTRL+C to quit)' port = sock.getsockname()[1] _log('info', ' * Running on %s://%s:%d/ %s', ssl_context is None and 'http' or 'https', display_hostname, port, quit_msg) def inner(): try: fd = int(os.environ['WERKZEUG_SERVER_FD']) except (LookupError, ValueError): fd = None srv = make_server(hostname, port, application, threaded, processes, request_handler, passthrough_errors, ssl_context, fd=fd) if fd is None: log_startup(srv.socket) srv.serve_forever() inner()
现在看来就简单很多了。执行了一个inner()函数:首先从环境变量中获取'WERKZEUG_SERVER_FD'的值,如果为空就执行log_startup()函数。执行make_server()函数并让返回的对象执行server_forever()函数。那我们再去make_server()里看看到底做了什么。
def make_server(host=None, port=None, app=None, threaded=False, processes=1, request_handler=None, passthrough_errors=False, ssl_context=None, fd=None): """Create a new server instance that is either threaded, or forks or just processes one request after another. """ if threaded and processes > 1: raise ValueError("cannot have a multithreaded and " "multi process server.") elif threaded: return ThreadedWSGIServer(host, port, app, request_handler, passthrough_errors, ssl_context, fd=fd) elif processes > 1: return ForkingWSGIServer(host, port, app, processes, request_handler, passthrough_errors, ssl_context, fd=fd) else: return BaseWSGIServer(host, port, app, request_handler, passthrough_errors, ssl_context, fd=fd)
make_server()函数创建了一个新的server对象。参看一下源码,** ThreadedWSGIServer** 和 ** ForkingWSGIServer 都是 ** BaseWSGIServer的子类。这篇文章我们就不仔细分析区别,就以BaseWSGIServer入手。BaseWSGIServer继承自HTTPServer。在werkzeug/serving.py的开始
try: import SocketServer as socketserver from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler except ImportError: import socketserver from http.server import HTTPServer, BaseHTTPRequestHandler
werkzeug的HTTP服务是基于Pyhton的BaseHTTPServer来实现的。关于BaseHTTPServer的文档在这里BaseHTTPServer。一般我们使用class HTTPServer来建立Server端,监听指定端口,然后创建一个class BaseHTTPRequestHandler来处理我们捕获到的request。在werkzeug中** WSGIRequestHandler** 继承自** BaseHTTPRequestHandler**。
关于BaseHTTPServer并没有什么太多值得讨论的东西,基本暴露出的接口都是调用父类的同名方法。我们要做的也就是传入hostname,port等参数,然后执行serve_forever()来建立服务。(serve_forever()看着眼熟吗?就是run_simple()中make_server()返回的srv对象执行的方法) 但是** WSGIRequestHandler **,作者还是想和各位唠叨几句。
根据Pyhton 2.7的官方文档所说,** BaseHTTPRequestHandler**这个类在Server端接收到请求以后会根据请求的方法来执行do_xx()函数。比如说我们发起的是一个GET请求,那么就会执行do_GET()这个函数。但对应各种请求方法的do_xx()函数父类并没有实现,需要使用者自行去定义。
文档中有一段示例代码,我们复制下来(如下)
import BaseHTTPServer def run(server_class=BaseHTTPServer.HTTPServer, handler_class=BaseHTTPServer.BaseHTTPRequestHandler): server_address = ('', 5000) httpd = server_class(server_address, handler_class) httpd.serve_forever() if __name__ == '__main__': run()
执行会在本地的5000端口建立一个服务。但是当你使用浏览器前往127.0.0.1:5000时会收到一个501的错误。

原因就在于我们并没有实现do_GET()方法。现在我们稍稍修改代码,继承BaseHTTPRequestHandler实现一个do_GET()方法,调用父类中send_response()返回client端一个200的状态码和一个'success message!'。
import BaseHTTPServer class HTTPServerHandler(BaseHTTPServer.BaseHTTPRequestHandler): def do_GET(self): self.send_response(200,'success message!') def run(server_class=BaseHTTPServer.HTTPServer, handler_class=HTTPServerHandler): server_address = ('', 5000) httpd = server_class(server_address, handler_class) httpd.serve_forever() if __name__ == '__main__': run()
再次请求。打开浏览器的开发者工具,在network中可以看到返回的结果。
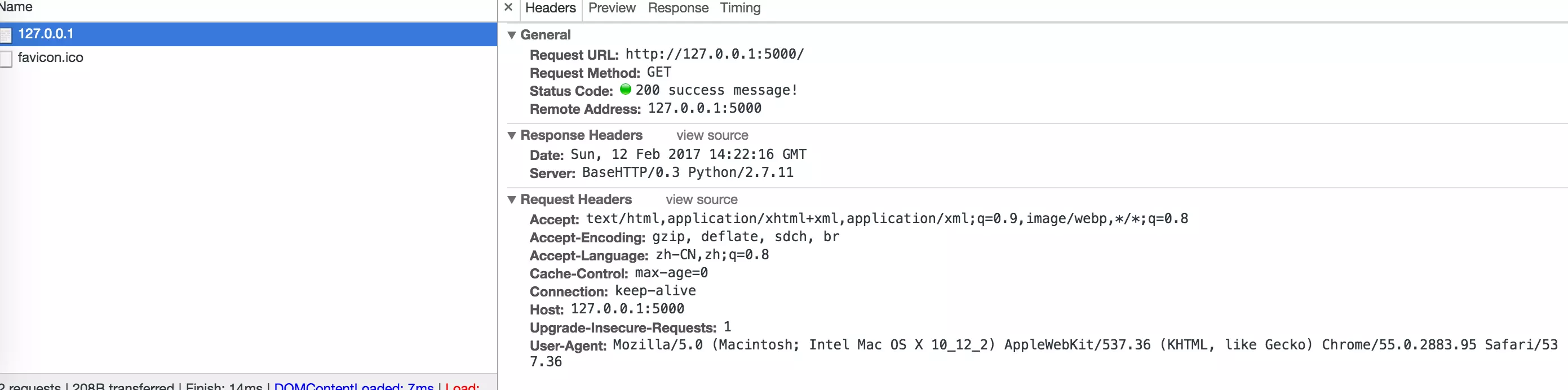
这样。一个最简单的Server端就实现了。当然,这个返回非常的简陋,并没有什么实际的信息返回。我们从这样一个简单的例子,应该要发现一点问题。
- 每一种HTTP请求的方法都需要对应去实现一个do_xx()方法,非常的麻烦。
- 所有的请求信息都暴露给开发者,很多时候开发者作为上层的调用者,并不想关心很多底层的操作。
- 当我们的application复杂起来,需要返回更多的内容。每次都要去操作这些基础的HTTP请求相关的东西。非常的不友好。
接下来,我们看看werkzeug中是如何处理的。在官方文档中
handle() Calls handle_one_request() once (or, if persistent connections are enabled, multiple times) to handle incoming HTTP requests.
You should never need to override it; instead, implement appropriate do_*() methods.
handle_one_request() This method will parse and dispatch the request to the appropriate do_*() method. You should never need to override it.
提到了,当我们捕获到request的时候调用的是这两个func()。并且,它给我们的提示是**You should never need to override it. **(滑稽)。但实际在werkzeug中这两个方法是被override了的。要想不顾官方的阻拦一意孤行,首先我们还是应该了解这两个方法究竟是怎么实现的。
def handle_one_request(self): """Handle a single HTTP request. You normally don't need to override this method; see the class __doc__ string for information on how to handle specific HTTP commands such as GET and POST. """ try: self.raw_requestline = self.rfile.readline(65537) if len(self.raw_requestline) > 65536: self.requestline = '' self.request_version = '' self.command = '' self.send_error(414) return if not self.raw_requestline: self.close_connection = 1 return if not self.parse_request(): # An error code has been sent, just exit return mname = 'do_' + self.command if not hasattr(self, mname): self.send_error(501, "Unsupported method (%r)" % self.command) return method = getattr(self, mname) method() self.wfile.flush() #actually send the response if not already done. except socket.timeout, e: #a read or a write timed out. Discard this connection self.log_error("Request timed out: %r", e) self.close_connection = 1 return def handle(self): """Handle multiple requests if necessary.""" self.close_connection = 1 self.handle_one_request() while not self.close_connection: self.handle_one_request()
捕获了request之后执行的是func handle()。其中self.close_connection 是一个关闭连接的标志位。只有在request header中包含keep-alive且协议版本号大于HTTP/1.1的时候设0,其余情况下置1。捕获request的具体实现还是在handle_one_request()中。
1.首先判断接收的字节数。是否大于65536。大于返回414错误。(IP首部中标识长度的有16bit,所以长度限制不可以大于2^16)
2.判断读取的字节。为空关闭连接
3.调用parse_request()解析request。解析错误返回状态吗,成功继续。
4.根据请求的方法寻找对应的函数。如果子类没有实现对应方法,返回501错误。找到对应方法,执行并将返回内容写入数据。
5.如果timeout,打个log记录一下。
这就是BaseHTTPServer中的处理。在了解了它的原理之后,让我们回到werkzeug,看看它是如何处理的。
def handle(self): """Handles a request ignoring dropped connections.""" rv = None try: rv = BaseHTTPRequestHandler.handle(self) except (socket.error, socket.timeout) as e: self.connection_dropped(e) except Exception: if self.server.ssl_context is None or not is_ssl_error(): raise if self.server.shutdown_signal: self.initiate_shutdown() return rv def handle_one_request(self): """Handle a single HTTP request.""" self.raw_requestline = self.rfile.readline() if not self.raw_requestline: self.close_connection = 1 elif self.parse_request(): return self.run_wsgi()
BaseHTTPServer并不支持SSL。在werkzeug中添加了对SSL的支持。所以在werkzeug的handle()中,它在执行了父类的func handle()后,除了对socket.timeout的处理,还考虑了SSL的可能。在func handle_one_request()中,减少了对字节流长度的判断。和BaseHTTPServer不同的是,werkzeug中把所有请求方法的处理,都放到了func run_wsgi()中,而不是根据请求方法区分成不同的方法并且要求子类来实现。
def run_wsgi(self): if self.headers.get('Expect', '').lower().strip() == '100-continue': self.wfile.write(b'HTTP/1.1 100 Continue ') self.environ = environ = self.make_environ() headers_set = [] headers_sent = [] def write(data): assert headers_set, 'write() before start_response' if not headers_sent: status, response_headers = headers_sent[:] = headers_set try: code, msg = status.split(None, 1) except ValueError: code, msg = status, "" self.send_response(int(code), msg) header_keys = set() for key, value in response_headers: self.send_header(key, value) key = key.lower() header_keys.add(key) if 'content-length' not in header_keys: self.close_connection = True self.send_header('Connection', 'close') if 'server' not in header_keys: self.send_header('Server', self.version_string()) if 'date' not in header_keys: self.send_header('Date', self.date_time_string()) self.end_headers() assert isinstance(data, bytes), 'applications must write bytes' self.wfile.write(data) self.wfile.flush() def start_response(status, response_headers, exc_info=None): if exc_info: try: if headers_sent: reraise(*exc_info) finally: exc_info = None elif headers_set: raise AssertionError('Headers already set') headers_set[:] = [status, response_headers] return write def execute(app): application_iter = app(environ, start_response) try: for data in application_iter: write(data) if not headers_sent: write(b'') finally: if hasattr(application_iter, 'close'): application_iter.close() application_iter = None try: execute(self.server.app) except (socket.error, socket.timeout) as e: self.connection_dropped(e, environ) except Exception: if self.server.passthrough_errors: raise from werkzeug.debug.tbtools import get_current_traceback traceback = get_current_traceback(ignore_system_exceptions=True) try: # if we haven't yet sent the headers but they are set # we roll back to be able to set them again. if not headers_sent: del headers_set[:] execute(InternalServerError()) except Exception: pass self.server.log('error', 'Error on request: %s', traceback.plaintext)
func run_wsgi()首先对request的headers进行了一个判断。有关HTTP协议的东西不在我们这篇文章的讨论范围内,RFC的文档在8.2.3 Use of the 100 (Continue) Status这里。有兴趣的朋友参考文档一下,这里我们可以先忽略了这个判断。
之后是获取环境变量environ。func make_environ()实质作用就是打包各类信息成一个字典。当你去查看这个函数源码时,你会发现这个字典的很多key值你非常的眼熟。没错,就是文章开始在解释func application()时,打印传入参数时打印的那个environ参数。func make_environ()获取了各项信息以后会在之后传给我们自己实现的application。这里我们先简单略过,后面遇到再讨论。
之后声明了两个数组和三个func,我们直接略过一路看到底。看到结尾处的try-catch,这才是run_wsgi()的入口位置。首先函数调用了func execute(),传入绑定在HTTPServer上的application。这个application就是func run_simple()我们传入的自定义的那个func application(),make_server()创建HTTPServer时将application绑定在上面。
application_iter = app(environ, start_response)
这样简单的一句乍看会让人比较的懵。因为我们知道,func application()返回的是一个Response对象,而这里application_iter很明显是一个可以迭代的对象。其中的秘密就在文章开始我们所说的那个deractor@Request.application。
我们已经解释过了,这个deractor拦截倒数第二个参数,对比这里就是environ,创建一个request对象,然后和倒数第二之前的参数(也就是只传入了request对象)一起传入我们的func application(),return了一个Response对象。return f(*args[:-2] + (request,))(*args[-2:]),这个deractor在return的时候又把这个response当做函数来处理了一把。在这个例子中最后的结果类似这样response(environ,start_response)。这样列出来就很明确了,我们去~/werkzeug/wrapper.py中看看class BaseResponse的call方法。
def __call__(self, environ, start_response): """Process this response as WSGI application. :param environ: the WSGI environment. :param start_response: the response callable provided by the WSGI server. :return: an application iterator """ app_iter, status, headers = self.get_wsgi_response(environ) start_response(status, headers) return app_iter
关于class Request和class Response其实有很多值得讨论的地方。这里我不展开讨论func get_wsgi_response()方法的实现。我们只要明确,返回了三个对象,app_iter(包含了需要返回的各项数据))status(状态码)headers(response headers)。其中app_iter就是我们上面刚刚讨论的application_iter。函数里调用传入的func start_response来写入status和headers。
def start_response(status, response_headers, exc_info=None): if exc_info: try: if headers_sent: reraise(*exc_info) finally: exc_info = None elif headers_set: raise AssertionError('Headers already set') headers_set[:] = [status, response_headers] return write
func start_response()将status和response_headers合并在func run_wsgi()开始创建的数组里,然后返回一个func write()。这些信息只是被保存下来,此时还没有被写入wfile。此时我们获取了application_iter,开始迭代调用func write()将每一项信息写入wfile
def write(data): assert headers_set, 'write() before start_response' if not headers_sent: status, response_headers = headers_sent[:] = headers_set try: code, msg = status.split(None, 1) except ValueError: code, msg = status, "" self.send_response(int(code), msg) header_keys = set() for key, value in response_headers: self.send_header(key, value) key = key.lower() header_keys.add(key) if 'content-length' not in header_keys: self.close_connection = True self.send_header('Connection', 'close') if 'server' not in header_keys: self.send_header('Server', self.version_string()) if 'date' not in header_keys: self.send_header('Date', self.date_time_string()) self.end_headers() assert isinstance(data, bytes), 'applications must write bytes' self.wfile.write(data) self.wfile.flush()
func write()首先判断了header_set是否为空,保证func start_response在func write之前执行。这是因为我们在写入数据之前首先要写入response_headers,再调用func self.end_headers()来将response_headers和应用数据区分开来。如果顺序错开就会发生错误。
再拿之前的例子用一下,这次我们加一点内容
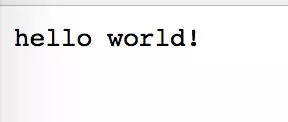
import BaseHTTPServer class HTTPServerHandler(BaseHTTPServer.BaseHTTPRequestHandler): def do_GET(self): self.send_response(200,'success message!') self.end_headers() self.wfile.write('hello world!') def run(server_class=BaseHTTPServer.HTTPServer, handler_class=HTTPServerHandler): server_address = ('', 5000) httpd = server_class(server_address, handler_class) httpd.serve_forever() if __name__ == '__main__': run()
运行这样一段代码之后打开浏览器输入127.0.0.1:5000,你可以看到浏览器显示
但是如果你替换了一下写入的顺序
def do_GET(self): self.wfile.write('hello world!') self.send_response(200,'success message!') self.end_headers()
再次访问127.0.0.1:5000,这个时候就会报错了。

官网的文档解释了end_headers()的作用。虽然简单,但也还是要我们注意
end_headers() Sends a blank line, indicating the end of the HTTP headers in the response.
回到werkzeug的源码,之后我们判断headers_sent是否为空。其实看这个命令我们也能猜出大概,这是保存已经写入过的response_headers的数组。如果为空证明我们还没有写入,进入if判断里,从我们之前func start_response中保存的headers_set中取出状态码和response_headers写入返回信息中。并且核查了几个必要的response_headers是否存在,如果不存在就进行设置写入。并且每一个写入的response_headers都被保存进headers_sent。这样第二次调用func write就不再重复设置。
func write的最后是真正的数据写入操作。
回到func run_wsgi的主干上来。我们在拿到application_iter后开始逐个迭代调用func write写入response。另外,假设func start_response没有设置任何response_headers,application_iter也为空。为了保证func write一定被执行一次,response_headers默认值被写入。我们会写入一个' '的数据。
之后是一些对于异常的处理。包括超时或者不可预知的错误。会抛出异常或者打log记录。
至此。一个完整的web流程就走完了。
这篇文章作者尝试把werkzeug这颗大树的枝丫全部砍去,留下一根主干来说明这个框架核心所在。当然,现实的web应用不可能如此简单。比如
- 所有的url的处理都导向一个func去处理。
- 返回复杂的数据如何处理
- 各种异常的处理
- 对各种操作的容错处理
...
后面作者会从主干拓展开始,慢慢补回枝丫来解释其他部分。著名的Flask框架就是基于werkzeug和Jinja 2实现的。在之后的文章,我不希望拆开werkzeug和Flask来分析。当做一个整体来看会更加和谐,也便于理解。
如有错误,欢迎指正
https://www.jianshu.com/p/4337f57e83f0
https://www.jianshu.com/p/d4097f7550e1
https://blog.csdn.net/perfectsorrow/article/details/80237066