Python中对象方法的定义很怪异,第一个参数一般都命名为self(相当于其它语言的this,比如:C#),用于传递对象本身,而在调用的时候则不
必显式传递,系统会自动传递。
今天我们介绍的主角是super(), 在类的继承里面super()非常常用, 它解决了子类调用父类方法的一些问题, 父类多次被调用时只执行一次, 优化了执行逻辑,下面我们就来详细看一下。
举一个例子:
class Foo: def bar(self, message): print(message) >>> Foo().bar("Hello, Python.") Hello, Python.
当存在继承关系的时候,有时候需要在子类中调用父类的方法,此时最简单的方法是把对象调用转换成类调用,需要注意的是这时self参数需要显式传递,例如:
class FooParent: def bar(self, message): print(message) class FooChild(FooParent): def bar(self, message): FooParent.bar(self, message) >>> FooChild().bar("Hello, Python.") Hello, Python.
这样做有一些缺点,比如说如果修改了父类名称,那么在子类中会涉及多处修改,另外,Python是允许多继承的语言,如上所示的方法在多继承时就需要重复写多次,显得累赘。
这样做的好处就是:如果你要改变子类继承的父类(由A改为B),你只需要修改一行代码(class C(A): -> class C(B))即可,而不需要在class C的大量代码中去查找、修改基类名,另外一方面代码的可移植性和重用性也更高。
为了解决这些问题,Python引入了super()机制,例子代码如下:
class FooParent: def bar(self, message): print(message) class FooChild(FooParent): def bar(self, message): super(FooChild, self).bar(message) >>> FooChild().bar("Hello, Python.") Hello, Python
表面上看 super(FooChild, self).bar(message)方法和FooParent.bar(self, message)方法的结果是一致的,实际上这两种方法的内部处理机制大大不同,当涉及多继承情况时,就会表现出明显的差异来,直接给例子: 代码一:
class A: def __init__(self): print("Enter A") print("Leave A") class B(A): def __init__(self): print("Enter B") A.__init__(self) print("Leave B") class C(A): def __init__(self): print("Enter C") A.__init__(self) print("Leave C") class D(A): def __init__(self): print("Enter D") A.__init__(self) print("Leave D") class E(B, C, D): def __init__(self): print("Enter E") B.__init__(self) C.__init__(self) D.__init__(self) print("Leave E") E()
结果: Enter E Enter B Enter A Leave A Leave B Enter C Enter A Leave A Leave C Enter D Enter A Leave A Leave D Leave E 执行顺序很好理解,唯一需要注意的是公共父类A被执行了多次。
代码二:
class A: def __init__(self): print("Enter A") print("Leave A") class B(A): def __init__(self): print("Enter B") super(B, self).__init__() print("Leave B") class C(A): def __init__(self): print("Enter C") super(C, self).__init__() print("Leave C") class D(A): def __init__(self): print("Enter D") super(D, self).__init__() print("Leave D") class E(B, C, D): def __init__(self): print("Enter E") super(E, self).__init__() print("Leave E") E()
结果:
Enter E
Enter B
Enter C
Enter D
Enter A
Leave A
Leave D
Leave C
Leave B
Leave E
在super机制里可以保证公共父类仅被执行一次,至于执行的顺序,是按照MRO(Method Resolution Order):方法解析顺序 进行的。后续会详细介绍一下这个MRO机制
另外:避免使用 super(self.__class__, self),一般情况下是没问题的,就是怕极端的情况:
class Foo(object): def x(self): print 'Foo' class Foo2(Foo): def x(self): print 'Foo2' super(self.__class__, self).x() # wrong class Foo3(Foo2): def x(self): print 'Foo3' super(Foo3, self).x() f = Foo3() f.x()
在 Foo2 中的 super(self.__class__, self) 导致了死循环,super 永远去找 Foo3 的 MRO 中的下一个类,super 的第一个参数应该总是当前的类,Python 没有规定代码必须怎样去写,但是养成一些好的习惯是很重要,会避免很多你不了解的问题发生。
使用super时新类和经典类的问题
class Father: def __init__(self): print 'this is father' class Child(Father): def __init__(self): super(Child,self).__init__() print 'this is child' c = Child()
今天在学习python super的用法(super用法及特点请移步http://www.cnblogs.com/lovemo1314/archive/2011/05/03/2035005.html)时,执行以上代码报出以下错误:
Traceback (most recent call last): File "E:/pythontest/classtest.py", line 13, in <module> c = Child() File "E:/pythontest/classtest.py", line 10, in __init__ super(Child,self).cook() TypeError: must be type, not classobj
google了一下:
class Base(object): def meth(self): print "i'm base"
经典类:
class Base: def meth(self): print "i'm base"
所以应该改成:
class Father(object): def __init__(self): print 'this is father' class Child(Father): def __init__(self): super(Child,self).__init__() print 'this is child' c = Child()
Python中经典类和新式类的区别

经典类与新式类在python3中是没有任何区别的,主要区别是在python2中多继承的时候。
区别:
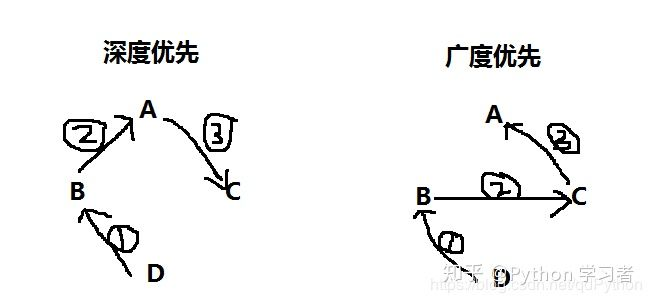
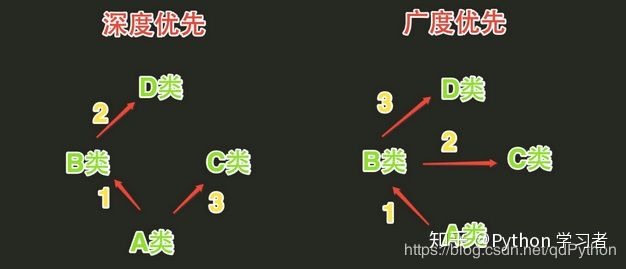
- 经典类是:深度优先
- 新式类是:广度优先
在python3里面都是广度优先
下面我们举例子来说明:
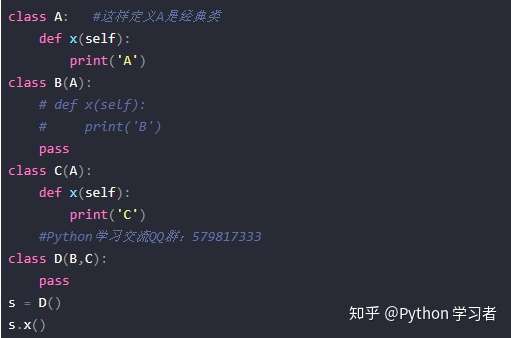

以下分析情况都是基于python2
1.这样定义A类,A是经典类,那么在继承后D调用x()方法的时候顺序是怎样的呢?
首先是从B类里面去找x()方法,如果B类中没有,就会从A类里面去找,如果A类中也没有x()方法,最后才会从C类里面去找;
2.那么如果A类定义的时候是新式类,那么在继承后D调用x()方法的时候顺序是怎样的呢?
首先是从B类里面去找x()方法,如果B类中没有,就会从C类里面去找,如果C类中也没有x()方法,最后才会从A类里面去找;
画个比较丑的图更直观的说明一下:
参考自:
https://blog.csdn.net/qq_14935437/article/details/81458506
https://blog.csdn.net/liweiblog/article/details/54425572
https://blog.csdn.net/hongrj/article/details/17415885