数据处理利器Pandas使用手册
工欲善其事必先利其器,在使用Python做数据挖掘和数据分析时,一大必不可少的利器就是Pandas库了。pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的,其纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
下面就从创建数据、查看数据、筛选数据、统计数据、缺失值处理、数据可视化等13个方面介绍Pandas数据处理的基本操作,希望对广大数据爱好者有所帮助。

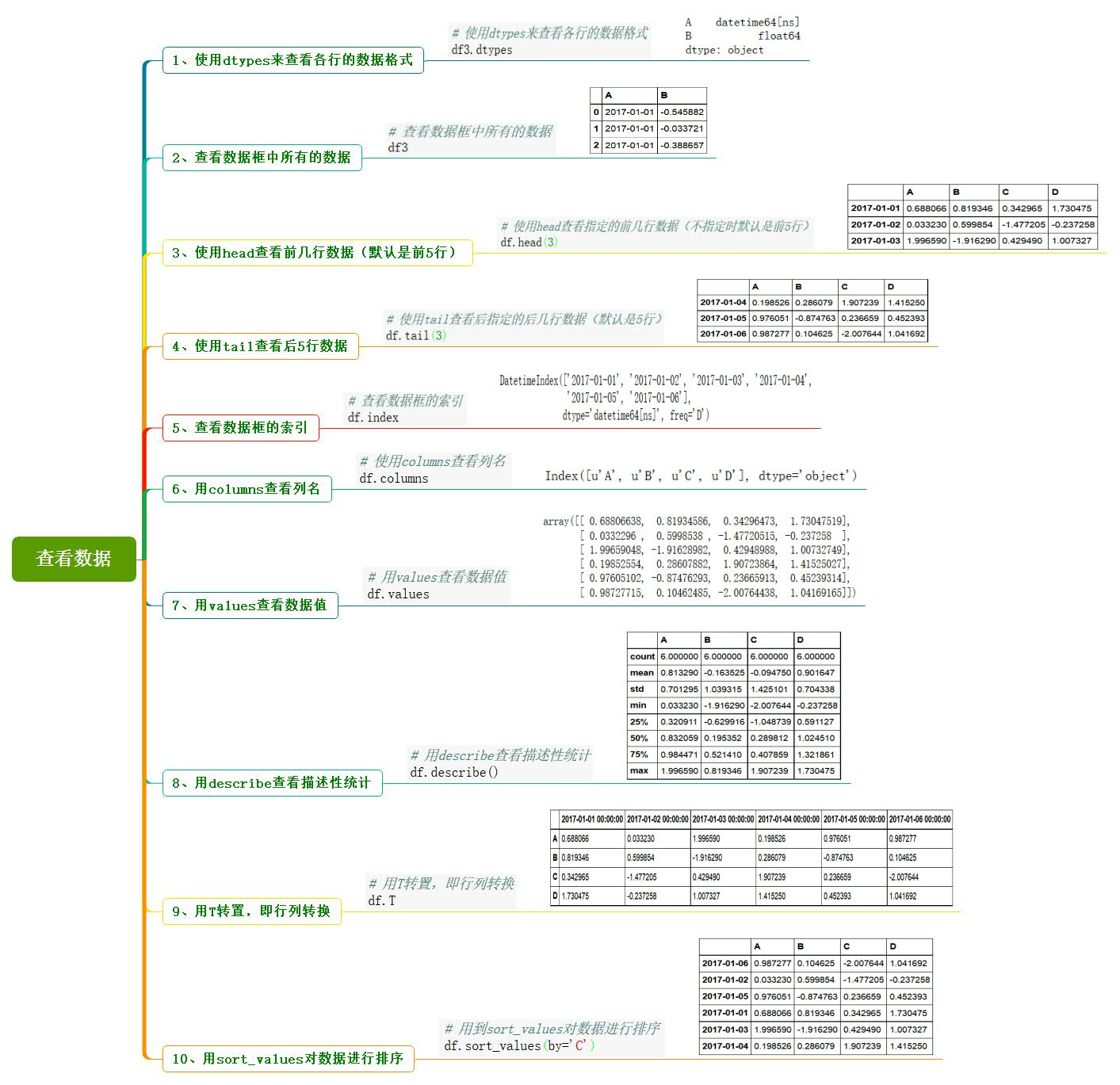
2、查看数据
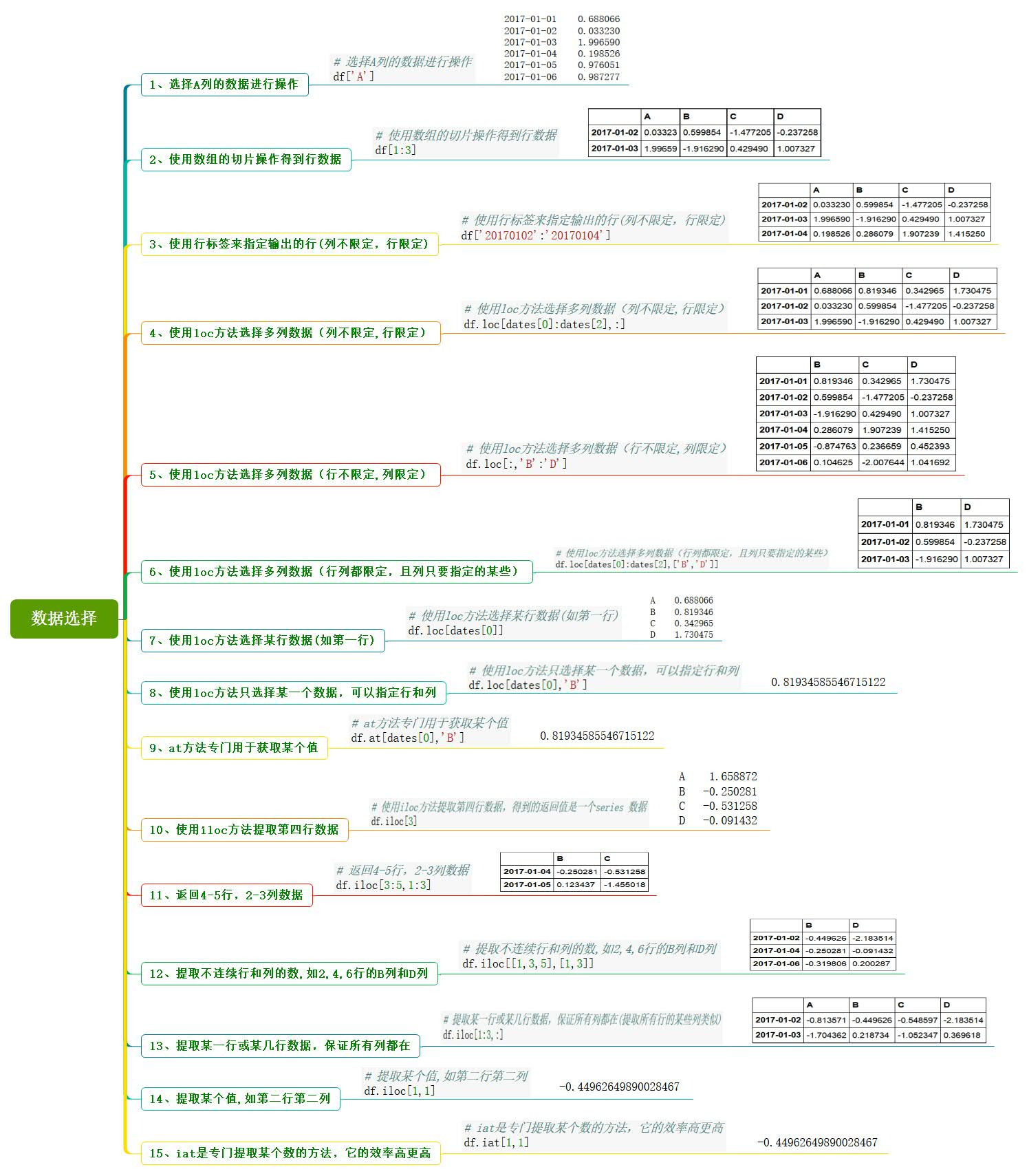
3、选择数据
4、读取CSV文件数据

5、筛选数据

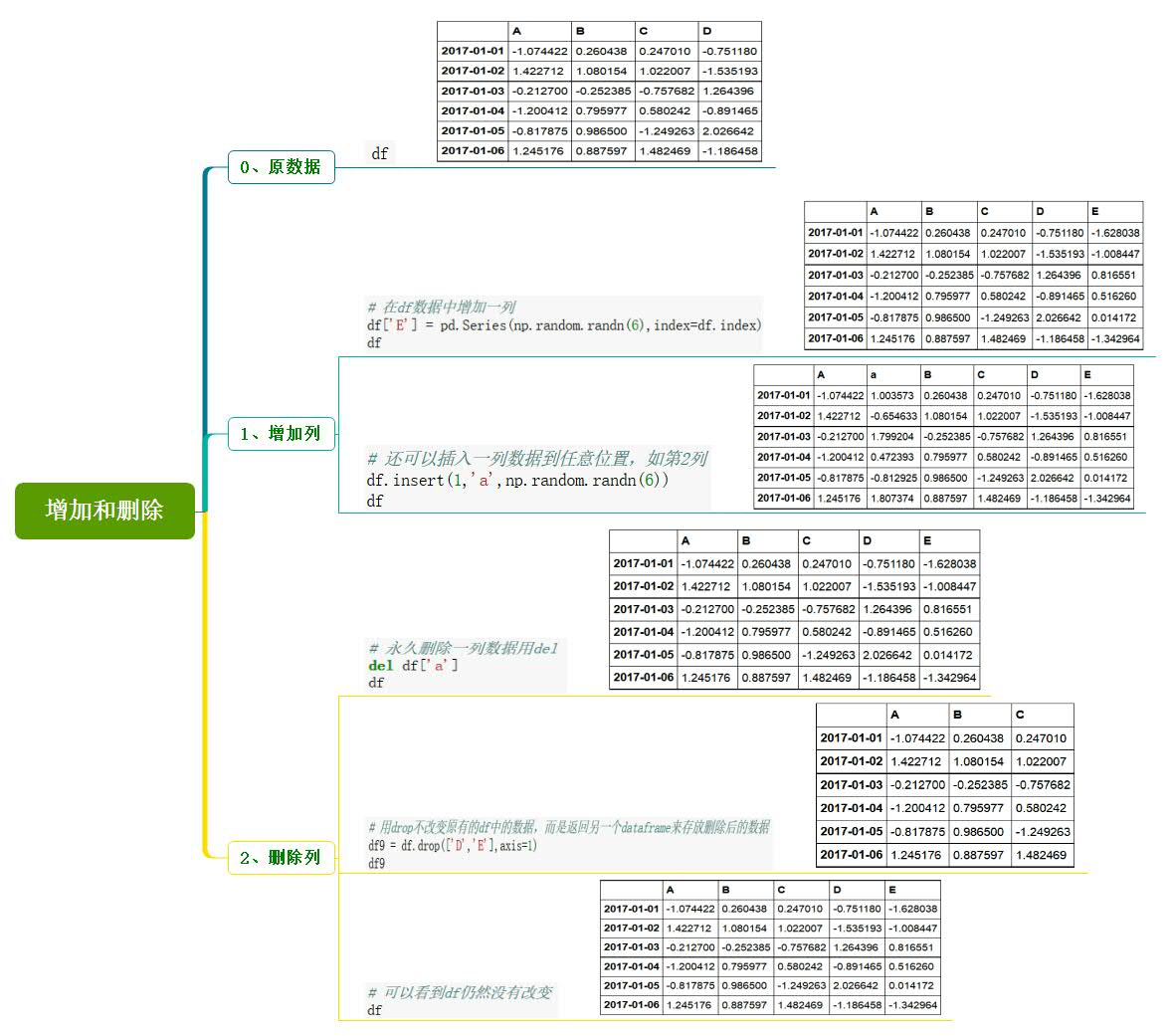
6、增加和删除数据
7、计数统计

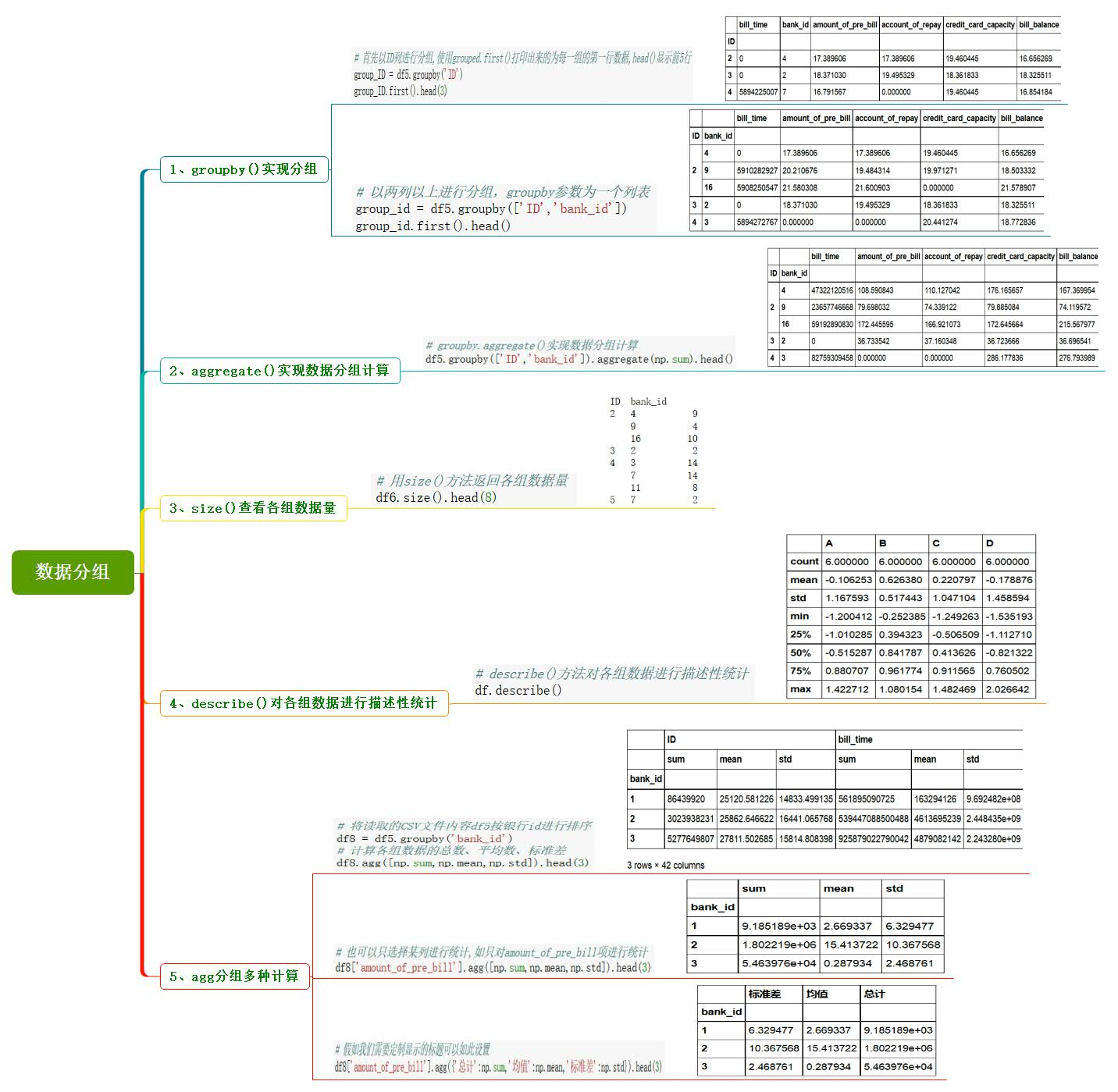
8、数据分组
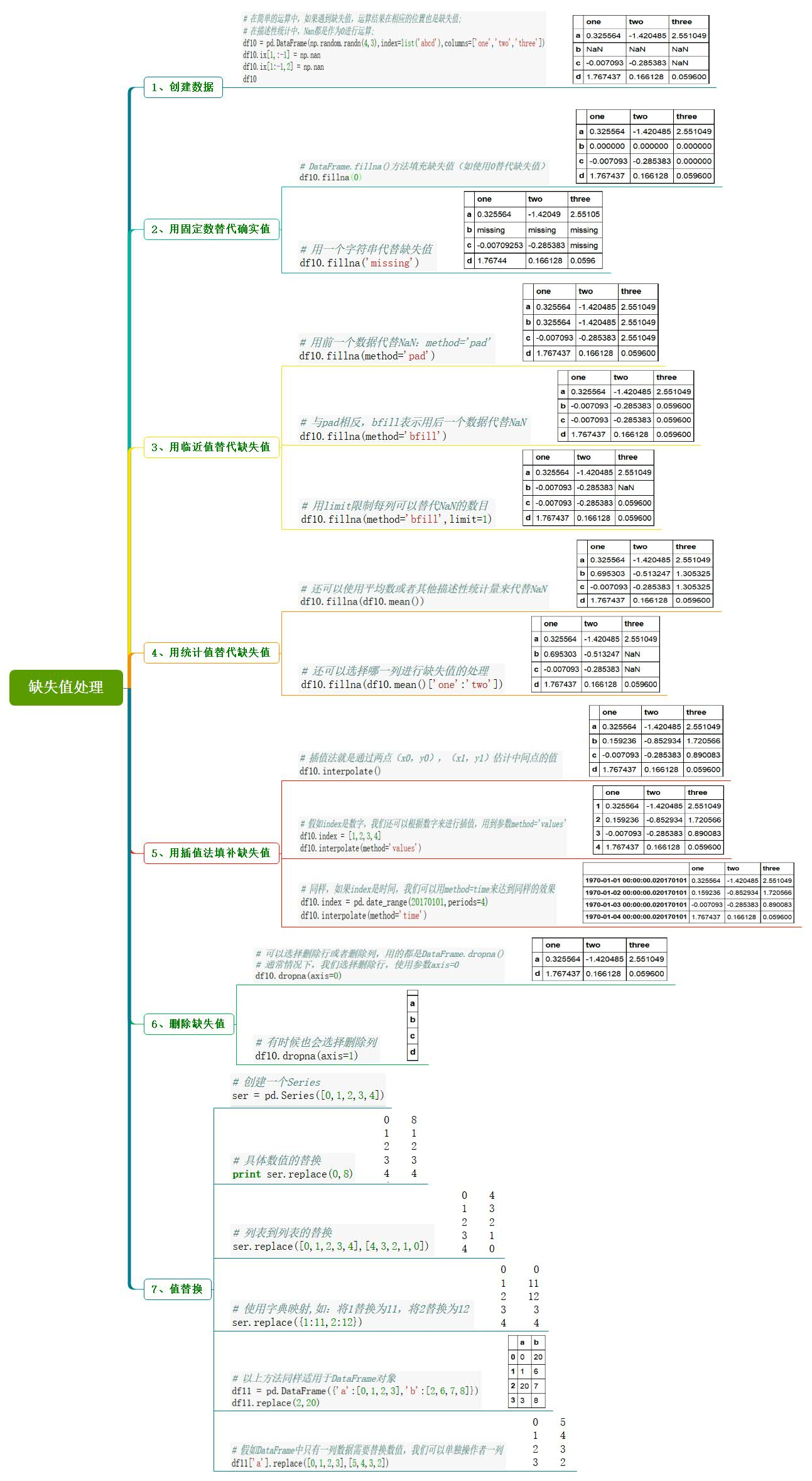
9、缺失值处理
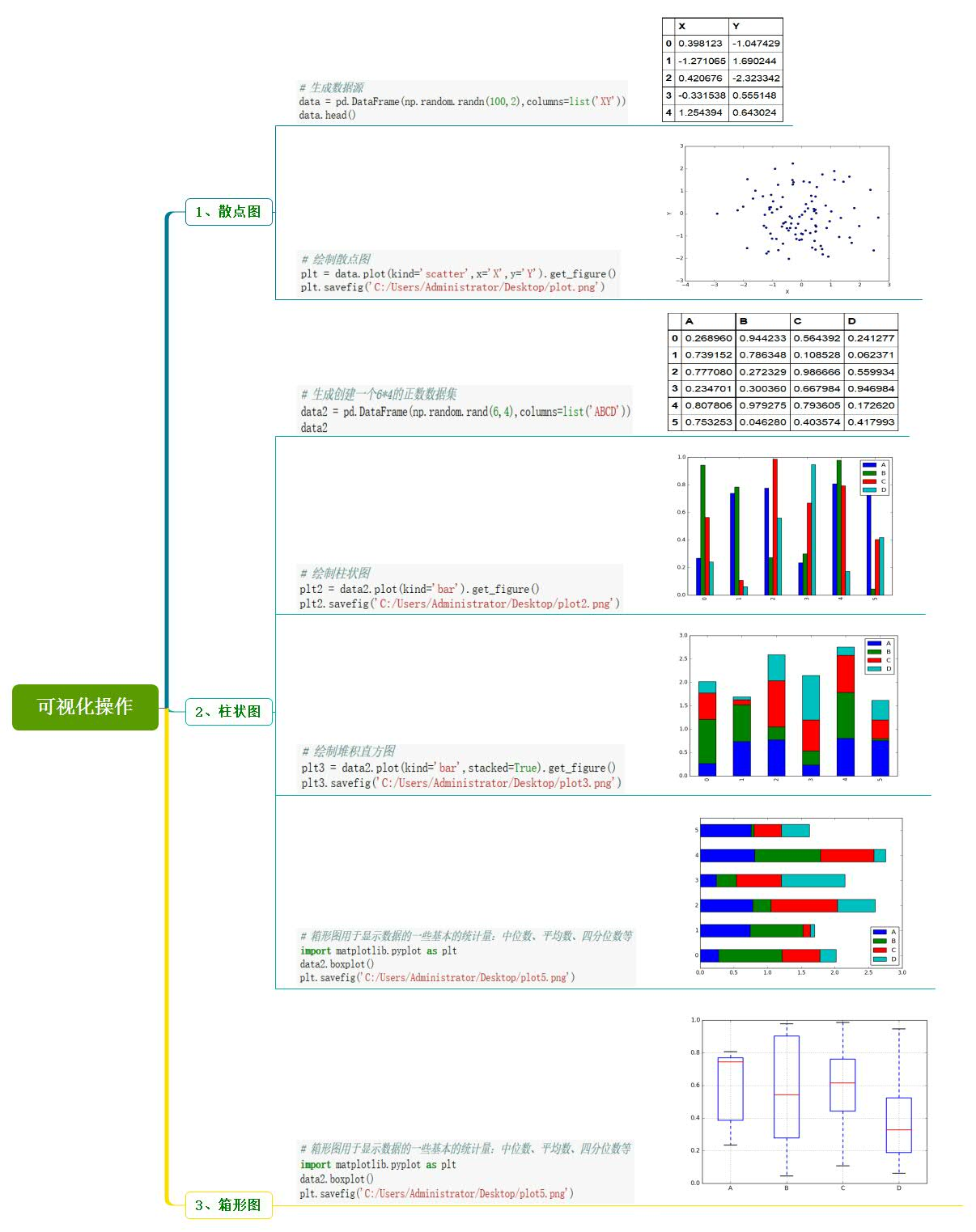
10、可视化
11、字符串操作

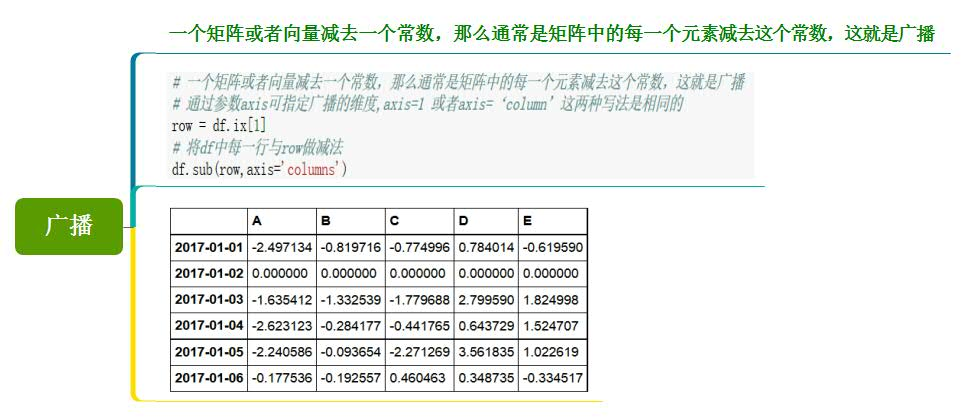
12、广播
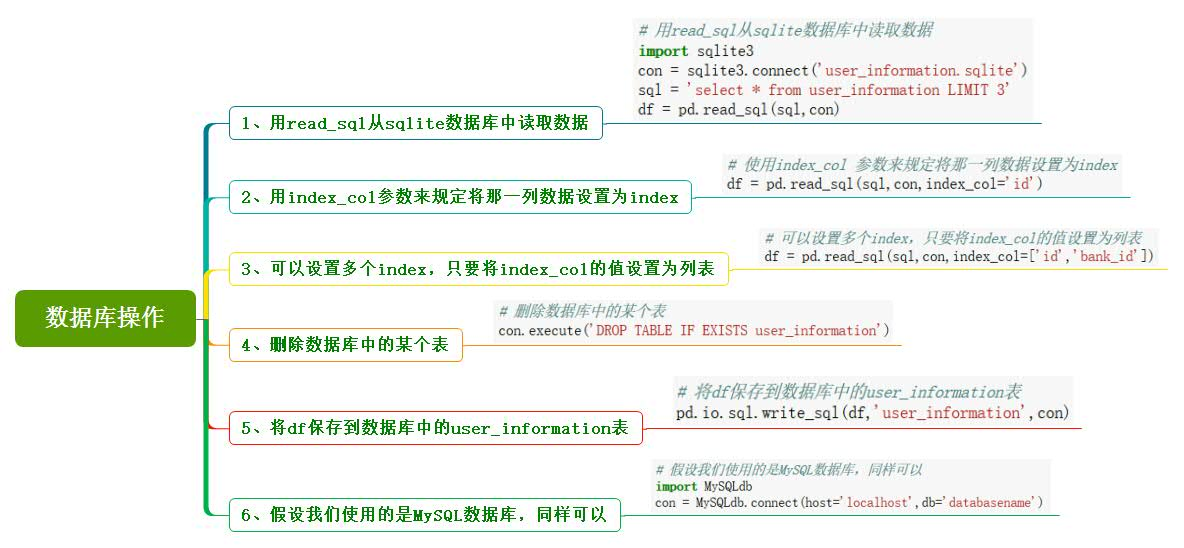
13、数据库操作
Python数据分析中 DataFrame axis=0与axis=1的理解
python中的axis究竟是如何定义的呢?他们究竟代表是DataFrame的行还是列? 直接上代码
people=DataFrame(np.random.randn(5,5),
columns=['a','b','c','d','e'],
index=['Joe','Steve','Wes','Jim','Travis'])
a b c d e
Joe 0.814300 -0.495764 0.397662 -1.874044 0.197068
Steve 2.858620 0.158600 -0.745151 -1.560638 -1.008016
Wes -1.313619 -0.346286 -0.499388 1.398095 0.811356
Jim 0.077873 0.188775 -0.394743 -0.747492 0.952180
Travis 0.561055 0.217268 0.154535 0.499617 1.359953
如果我们调用df.mean(axis=1),我们将得到按行计算的均值
print (people.mean(axis=1))
Joe 0.505552
Steve 0.020678
Wes -0.150306
Jim -0.999511
Travis 0.845914
然而,如果我们调用 df.drop((name, axis=1),我们实际上删掉了一列,而不是一行:
b c d e
Joe -0.862853 0.833427 0.889615 0.776224
Steve -0.529979 -0.718482 -0.587110 1.782204
Wes -0.159212 0.891302 -0.764884 0.050697
Jim 1.212420 1.441785 -1.574010 -0.328341
Travis 0.158050 0.094732 0.397940 0.368299
- 使用0值表示沿着每一列或行标签索引值向下执行方法
- 使用1值表示沿着每一行或者列标签模向执行对应的方法
下图代表在DataFrame当中axis为0和1时分别代表的含义:

另外,记住,Pandas保持了Numpy对关键字axis的用法,用法在Numpy库的词汇表当中有过解释:
轴用来为超过一维的数组定义的属性,二维数据拥有两个轴:第0轴沿着行的垂直往下,第1轴沿着列的方向水平延伸。
所以问题当中第一个列子 df.mean(axis=1)代表沿着列水平方向计算均值,而第二个列子df.drop(name, axis=1) 代表将name对应的列标签沿着水平的方向依次删掉。
Python中pandas dataframe删除一行或一列:drop函数
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
参数说明:
labels 就是要删除的行列的名字,用列表给定
axis 默认为0,指删除行,因此删除columns时要指定axis=1;
index 直接指定要删除的行
columns 直接指定要删除的列
inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;
inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
因此,删除行列有两种方式:
1)labels=None,axis=0 的组合
2)index或columns直接指定要删除的行或列
例子:
>>>df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A', 'B', 'C', 'D']) >>>df A B C D 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 #Drop columns,两种方法等价 >>>df.drop(['B', 'C'], axis=1) A D 0 0 3 1 4 7 2 8 11 >>>df.drop(columns=['B', 'C']) A D 0 0 3 1 4 7 2 8 11 # 第一种方法下删除column一定要指定axis=1,否则会报错 >>> df.drop(['B', 'C']) ValueError: labels ['B' 'C'] not contained in axis #Drop rows >>>df.drop([0, 1]) A B C D 2 8 9 10 11 >>> df.drop(index=[0, 1]) A B C D 2 8 9 10 11