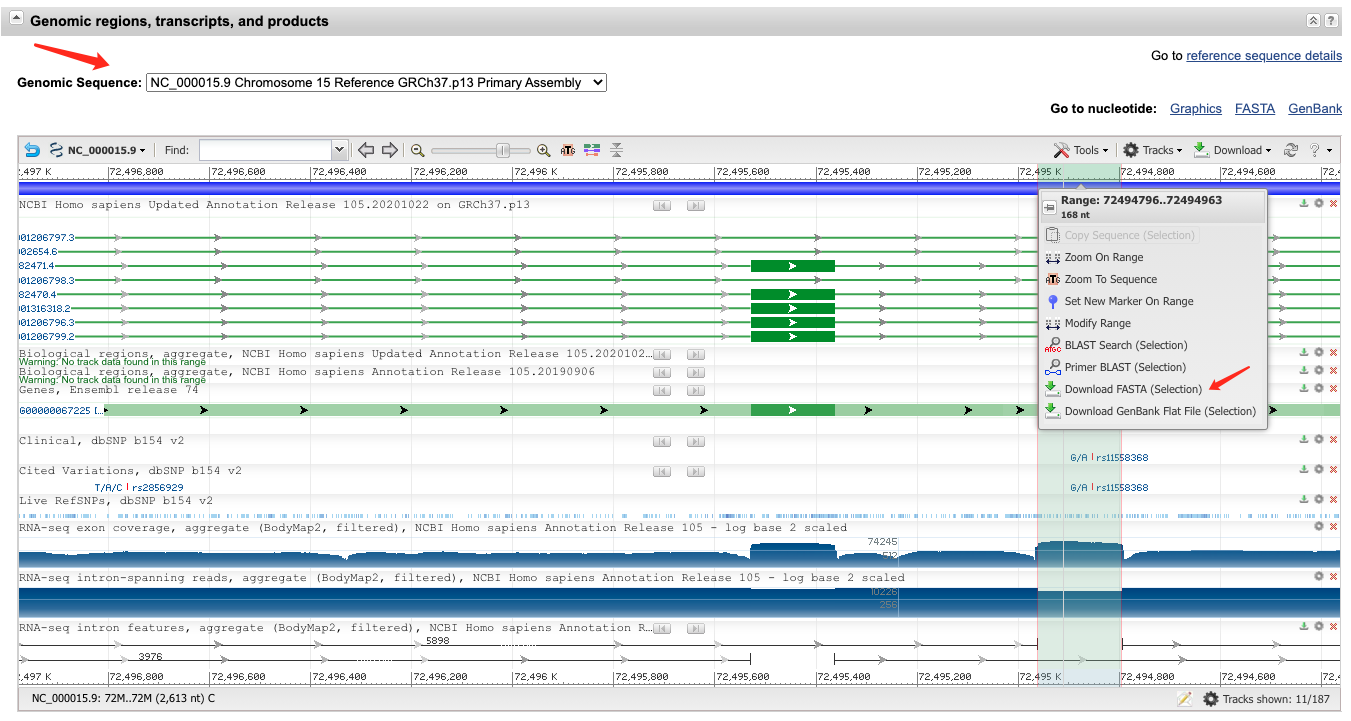
主要是可变剪切分析的实验验证需要用到具体的碱基序列,如果工具使用不熟还是挺烦的,容易搞错或者放大工作量。
最简单的方法:
以PKM为例,打开https://www.ncbi.nlm.nih.gov/gene/5315
click "Tools" - "Sequence Text View"
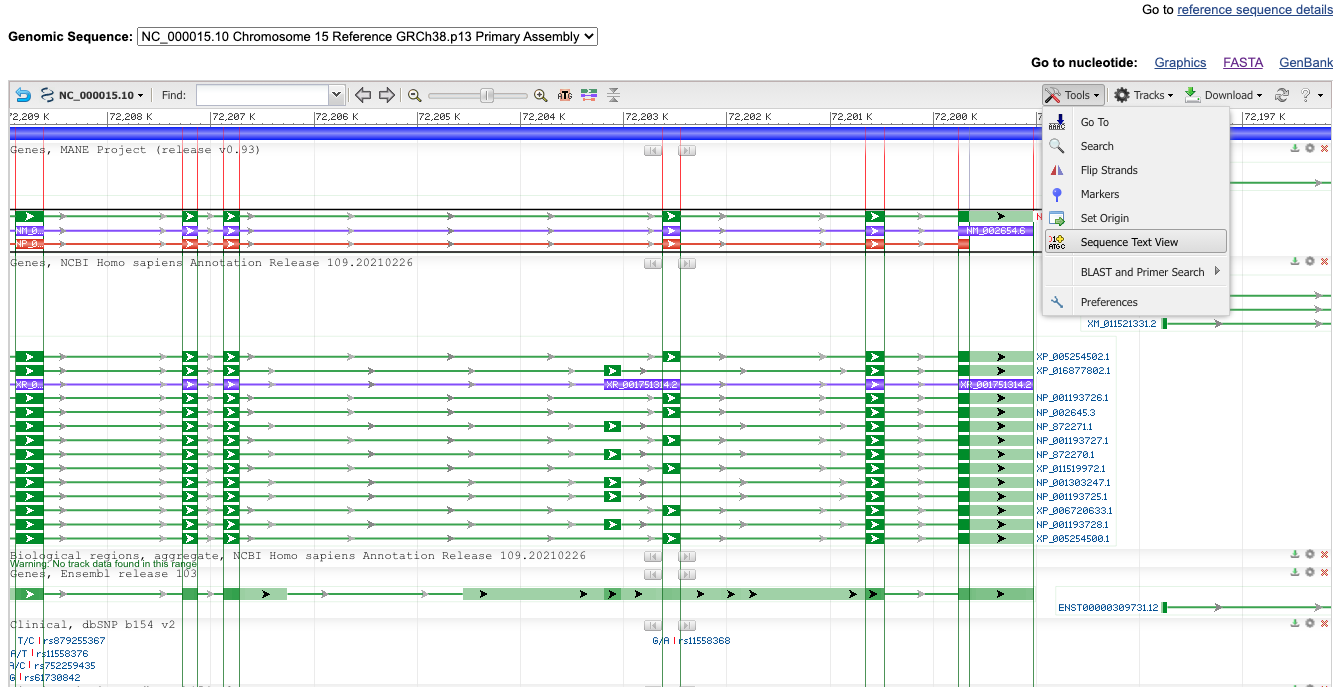
然后就可以看到非常清晰准确的exon及其氨基酸序列了。
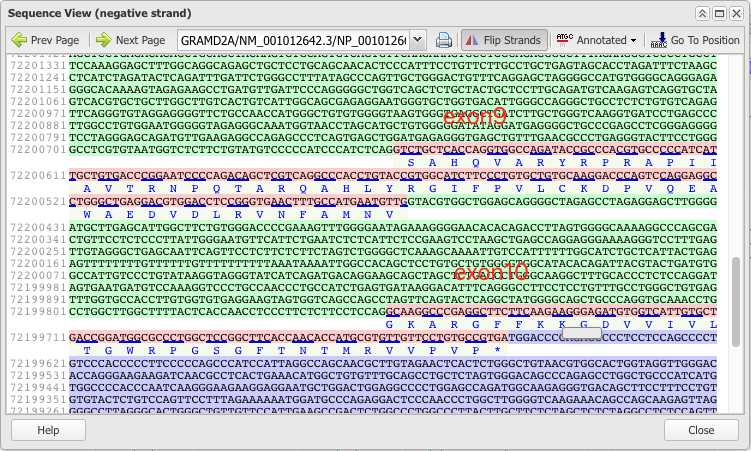
如果不会搞,傻乎乎的自己去count,不仅累,还容易搞错。
这个sequence view有点难搞,看不太懂,其实也可以直接下载指定区域的fasta序列。