1. 引入
大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的。遵循的基本原则之一是文件的“一次写入多次读取”访问模型。这对于处理海量数据非常有用,如数百GB到TB的数据。
但是在构建分析数据湖时,更新数据并不罕见。根据不同场景,这些更新频率可能是每小时一次,甚至可能是每天或每周一次。另外可能还需要在最新视图、包含所有更新的历史视图甚至仅是最新增量视图上运行分析。
通常这会导致使用用于流和批处理的多个系统,前者处理增量数据,而后者处理历史数据。
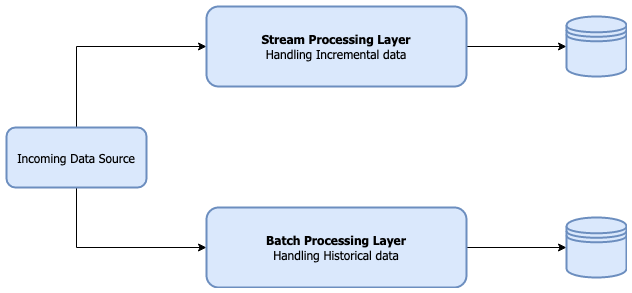
处理存储在HDFS上的数据时,维护增量更新的常见工作流程是这里所述的Ingest-Reconcile-Compact-Purge策略。

Apache Hudi之类的框架在这里便可发挥作用。它在后台为我们管理此工作流程,从而使我们的核心应用程序代码更加简洁,Hudi支持对最新数据视图的查询以及查询在某个时间点的增量更改。
这篇文章将介绍Hudi的核心概念以及如何在Copy-On-Write模式下进行操作。
本篇文章项目源代码放在github。
2. 大纲
- 先决条件和框架版本
- Hudi核心概念
- 初始设置和依赖项
- 使用CoW表
2.1 先决条件和框架版本
如果你事先了解如何使用scala编写spark作业以及读取和写入parquet文件,那么本篇文章理解起来将非常容易。
框架版本如下
- JDK: openjdk 1.8.0_242
- Scala: 2.12.8
- Spark: 2.4.4
- Hudi Spark bundle: 0.5.2-incubating
注意:在撰写本文时,AWS EMR与Hudi v0.5.0-incubating集成在一起,该软件包具有一个bug会导致upsert操作卡死或花费很长时间才能完成,可查看相关issue了解更多,该问题已在当前版本的Hudi(0.5.2-incubating及之后版本)中修复。如果计划在AWS EMR上运行代码,则可能要考虑用最新版本覆盖默认的集成版本。
2.2 Hudi核心概念
先从一些需要理解的核心概念开始。
1. 表类型
Hudi支持两种表类型
-
写时复制(CoW):写入CoW表时,将运行Ingest-Reconcile-Compact-Purge周期。每次写操作后,CoW表中的数据始终是最新记录,对于需要尽快读取最新数据的场景,可首选此模式。数据仅以列文件格式(parquet)存储在CoW表中,由于每个写操作都涉及压缩和覆盖,因此此模式产生的文件最少。
-
读时合并(MoR):MoR表专注于快速写操作。写入这些表将创建增量文件,随后将其压缩以生成读取时的最新数据,压缩操作可以同步或异步完成,数据以列文件格式(parquet)和基于行的文件格式(avro)组合存储。
这是Hudi文档中提到的两种表格格式之间的权衡取舍。
| Trade-off | CoW | MoR |
|---|---|---|
| 数据延迟 | Higher | Lower |
| 更新开销 (I/O) | Higher (重写整个parquet文件) | Lower (追加到delta log文件) |
| Parquet文件大小 | Smaller (高update(I/0) 开销) | Larger (低更新开销) |
| Write Amplification | Higher | Lower (由compaction策略决定) |
2. 查询类型
Hudi支持两种主要类型的查询:“快照查询”和“增量查询”。除两种主要查询类型外,MoR表还支持“读优化查询”。
-
快照查询:对于CoW表,快照查询返回数据的最新视图,而对于MoR表,则返回接近实时的视图。 对于MoR表,快照查询将即时合并基本文件和增量文件,因此可能会有一些读取延迟。使用CoW,由于写入负责合并,因此读取很快,只需要读取基本文件。
-
增量查询:增量查询使您可以通过指定“开始”时间或在特定时间点通过指定“开始”和“结束”时间来查看特定提交时间之后的数据。
-
读优化查询:对于MoR表,读取优化查询返回一个视图,该视图仅包含基本文件中的数据,而不合并增量文件。
3. 以Hudi格式写入时的关键属性
-
hoodie.datasource.write.table.type,定义表的类型-默认值为COPY_ON_WRITE。对于MoR表,将此值设置为MERGE_ON_READ。 -
hoodie.table.name,这是必填字段,每个表都应具有唯一的名称。 -
hoodie.datasource.write.recordkey.field,将此视为表的主键。此属性的值是DataFrame中列的名称,该列是主键。 -
hoodie.datasource.write.precombine.field,更新数据时,如果存在两个具有相同主键的记录,则此列中的值将决定更新哪个记录。选择诸如时间戳记的列将确保选择具有最新时间戳记的记录。 -
hoodie.datasource.write.operation,定义写操作的类型。值可以为upsert,insert,bulk_insert和delete,默认值为upsert。
2.3 初始设置和依赖项
1. 依赖说明
为了在Spark作业中使用Hudi,需要使用spark-sql,hudi-spark-bundle和spark-avro依赖项,此外还需要将Spark配置为使用KryoSerializer。
pom.xml大致内容如下
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.12.8</scala.version>
<scala.compat.version>2.12</scala.compat.version>
<spec2.version>4.2.0</spec2.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark-bundle_${scala.compat.version}</artifactId>
<version>0.5.2-incubating</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.compat.version}</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
2. 设置Schema
我们使用下面的Album类来表示表的schema。
case class Album(albumId: Long, title: String, tracks: Array[String], updateDate: Long)
3. 生成测试数据
创建一些用于upsert操作的数据。
- INITIAL_ALBUM_DATA有两个记录,键为801。
- UPSERT_ALBUM_DATA包含一个更新的记录和两个新的记录。
def dateToLong(dateString: String): Long = LocalDate.parse(dateString, formatter).toEpochDay
private val INITIAL_ALBUM_DATA = Seq(
Album(800, "6 String Theory", Array("Lay it down", "Am I Wrong", "68"), dateToLong("2019-12-01")),
Album(801, "Hail to the Thief", Array("2+2=5", "Backdrifts"), dateToLong("2019-12-01")),
Album(801, "Hail to the Thief", Array("2+2=5", "Backdrifts", "Go to sleep"), dateToLong("2019-12-03"))
)
private val UPSERT_ALBUM_DATA = Seq(
Album(800, "6 String Theory - Special", Array("Jumpin' the blues", "Bluesnote", "Birth of blues"), dateToLong("2020-01-03")),
Album(802, "Best Of Jazz Blues", Array("Jumpin' the blues", "Bluesnote", "Birth of blues"), dateToLong("2020-01-04")),
Album(803, "Birth of Cool", Array("Move", "Jeru", "Moon Dreams"), dateToLong("2020-02-03"))
)
4. 初始化SparkContext
最后初始化Spark上下文。这里要注意的重要一点是KryoSerializer的使用。
val spark: SparkSession = SparkSession.builder()
.appName("hudi-datalake")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.hive.convertMetastoreParquet", "false") // Uses Hive SerDe, this is mandatory for MoR tables
.getOrCreate()
2.4 使用CoW表
本节将处理CoW表的记录,如读取和删除记录。
1. basePath(基本路径)和Upsert方法
定义一个basePath,upsert方法会将表数据写入该路径,该方法将以org.apache.hudi格式写入Dataframe,请确保上面讨论的所有Hudi属性均已设置。
val basePath = "/tmp/store"
private def upsert(albumDf: DataFrame, tableName: String, key: String, combineKey: String) = {
albumDf.write
.format("hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, key)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, combineKey)
.option(HoodieWriteConfig.TABLE_NAME, tableName)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
// Ignore this property for now, the default is too high when experimenting on your local machine
// Set this to a lower value to improve performance.
// I'll probably cover Hudi tuning in a separate post.
.option("hoodie.upsert.shuffle.parallelism", "2")
.mode(SaveMode.Append)
.save(s"$basePath/$tableName/")
}
2. 初始化upsert
插入INITIAL_ALBUM_DATA,我们应该创建2条记录,对于801,该记录的日期为2019-12-03。
val tableName = "Album"
upsert(INITIAL_ALBUM_DATA.toDF(), tableName, "albumId", "updateDate")
spark.read.format("hudi").load(s"$basePath/$tableName/*").show()
读取CoW表就像使用格式(“hudl”)的常规spark.read一样简单。
// Output
+-------------------+--------------------+------------------+----------------------+--------------------+-------+-----------------+--------------------+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|albumId| title| tracks|updateDate|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+-----------------+--------------------+----------+
| 20200412182343| 20200412182343_0_1| 801| default|65841d0a-0083-447...| 801|Hail to the Thief|[2+2=5, Backdrift...| 18233|
| 20200412182343| 20200412182343_0_2| 800| default|65841d0a-0083-447...| 800| 6 String Theory|[Lay it down, Am ...| 18231|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+-----------------+--------------------+----------+
另一种确定的方法是查看Workload profile的日志输出,内容大致如下
Workload profile :WorkloadProfile {globalStat=WorkloadStat {numInserts=2, numUpdates=0}, partitionStat={default=WorkloadStat {numInserts=2, numUpdates=0}}}
3. 更新记录
upsert(UPSERT_ALBUM_DATA.toDF(), tableName, "albumId", "updateDate")
查看Workload profile的日志输出,并验证它是否符合预期
Workload profile :WorkloadProfile {globalStat=WorkloadStat {numInserts=2, numUpdates=1}, partitionStat={default=WorkloadStat {numInserts=2, numUpdates=1}}}
查询输出如下
spark.read.format("hudi").load(s"$basePath/$tableName/*").show()
//Output
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|albumId| title| tracks|updateDate|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
| 20200412183510| 20200412183510_0_1| 801| default|65841d0a-0083-447...| 801| Hail to the Thief|[2+2=5, Backdrift...| 18233|
| 20200412184040| 20200412184040_0_1| 800| default|65841d0a-0083-447...| 800|6 String Theory -...|[Jumpin' the blue...| 18264|
| 20200412184040| 20200412184040_0_2| 802| default|65841d0a-0083-447...| 802| Best Of Jazz Blues|[Jumpin' the blue...| 18265|
| 20200412184040| 20200412184040_0_3| 803| default|65841d0a-0083-447...| 803| Birth of Cool|[Move, Jeru, Moon...| 18295|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
4. 查询记录
我们在上面查看数据的方式称为“快照查询”,这是默认设置,另外还支持“增量查询”。
4.1 增量查询
要执行增量查询,我们需要在读取时将hoodie.datasource.query.type属性设置为incremental,并指定hoodie.datasource.read.begin.instanttime属性。 这将在指定的即时时间之后读取所有记录,对于本示例,我们将instantTime指定为20200412183510。
spark.read
.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "20200412183510")
.load(s"$basePath/$tableName")
.show()
这将在提交时间20200412183510之后返回所有记录。
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|albumId| title| tracks|updateDate|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
| 20200412184040| 20200412184040_0_1| 800| default|65841d0a-0083-447...| 800|6 String Theory -...|[Jumpin' the blue...| 18264|
| 20200412184040| 20200412184040_0_2| 802| default|65841d0a-0083-447...| 802| Best Of Jazz Blues|[Jumpin' the blue...| 18265|
| 20200412184040| 20200412184040_0_3| 803| default|65841d0a-0083-447...| 803| Birth of Cool|[Move, Jeru, Moon...| 18295|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
5. 删除记录
我们要查看的最后一个操作是删除,删除类似于upsert,需要一个待删除记录的DataFrame,如下面的示例代码所示,不需要整行,只需要主键即可。
val deleteKeys = Seq(
Album(803, "", null, 0l),
Album(802, "", null, 0l)
)
import spark.implicits._
val df = deleteKeys.toDF()
df.write.format("hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "albumId")
.option(HoodieWriteConfig.TABLE_NAME, tableName)
// Set the option "hoodie.datasource.write.operation" to "delete"
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.DELETE_OPERATION_OPT_VAL)
.mode(SaveMode.Append) // Only Append Mode is supported for Delete.
.save(s"$basePath/$tableName/")
spark.read.format("hudi").load(s"$basePath/$tableName/*").show()
这是本部分介绍的全部内容。后面我们将探讨在MERGE-ON-READ表进行操作。