1. 引入
线上用户反馈使用Presto查询Hudi表出现错误,而将Hudi表的文件单独创建parquet类型表时查询无任何问题,关键报错信息如下
40931f6e-3422-4ffd-a692-6c70f75c9380-0_0-384-2545_20200513165135.parquet, start=0, length=67108864, fileSize=67108864, hosts=[], forceLocalScheduling=false, partitionName=dt=2020-05-08, s3SelectPushdownEnabled=false} (start = 2.3651547291593433E10, wall = 163 ms, cpu = 0 ms, wait = 0 ms, calls = 1): HIVE_BAD_DATA: Not valid Parquet file:
报Hudi表中文件格式不是合法的parquet格式错误。
2. 问题复现
开始根据用户提供的信息,模拟线上Hudi数据集大小、Presto和Hudi版本(0.5.2-incubating)来复现该问题。
进行试验发现当Hudi表单文件大小较小时,使用Presto查询一切正常。
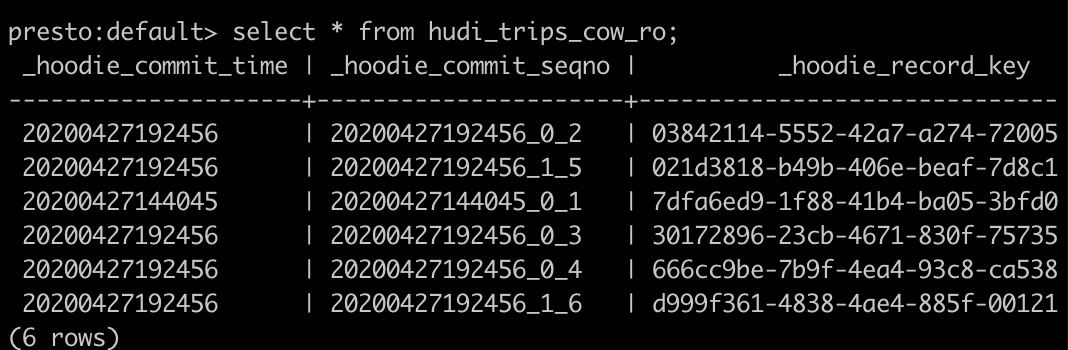
构建Hudi表中单文件大小为100MB以上数据集,使用Presto查询。
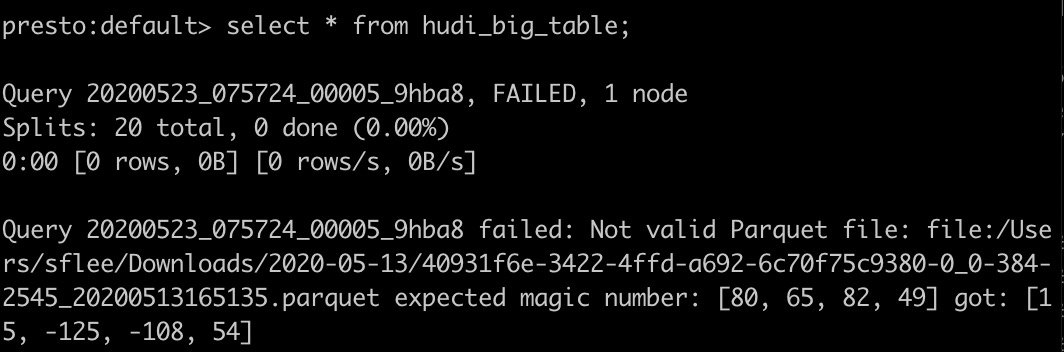
可以看到,当Hudi数据集中文件大小为100MB时复现了Not Valid Parquet file异常,通过Presto的web ui可以看到具体的错误堆栈如下
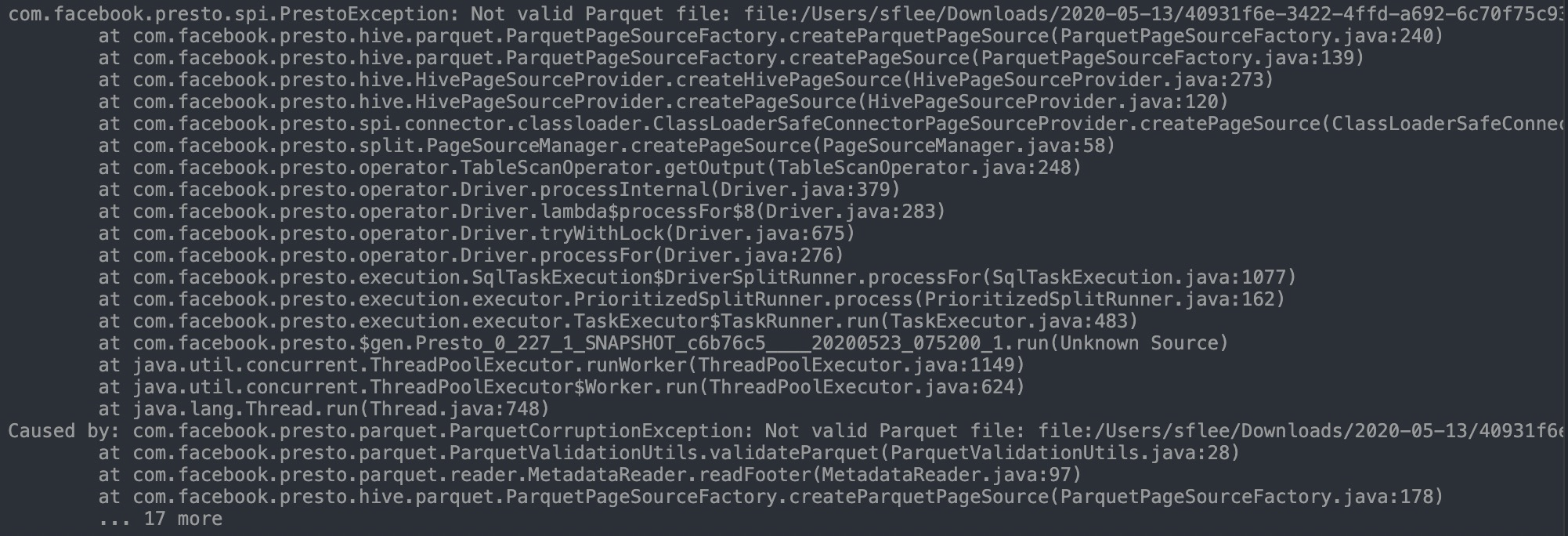
通过错误堆栈可以进一步确认在读取parquet文件时校验失败,开始怀疑parquet文件确实被损坏,但使用parquet-tools工具检查本地parquet文件,发现无问题。
3. 问题排查
经过上述步骤复现了问题,问题能够复现就好排查。但Presto对于合法parquet文件检查为何会报错?带着这个疑问开始在本地debug Presto,首先在Presto服务端和IDEA中进行相应的配置。
3.1 Presto服务端配置
要想能够连接到Presto服务端,需要在PRESTO_HOME根目录下创建etc目录,然后创建jvm.properties文件,内容如下
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
-XX:+TraceClassLoading
-XX:+TraceClassUnloading
-verbose:class
上述配置除了可以连接服务端进行debug外,添加的-XX:+TraceClassLoading、-XX:+TraceClassUnloading两个配置项,还会打印每个类加载和卸载的日志(这个在排查presto类加载器问题时非常有用,建议开启)。
3.2 IDEA配置
配置完Presto服务端后,在IDEA进行如下配置即可。
3.3 单步调试
IDEA中开启了debug后,通过Presto客户端查询时(select * from hudi_big_table),就可以进行单步调试,首先我们在BackgroundHiveSplitLoader类中打了些断点(该类是加载Split的关键类)。
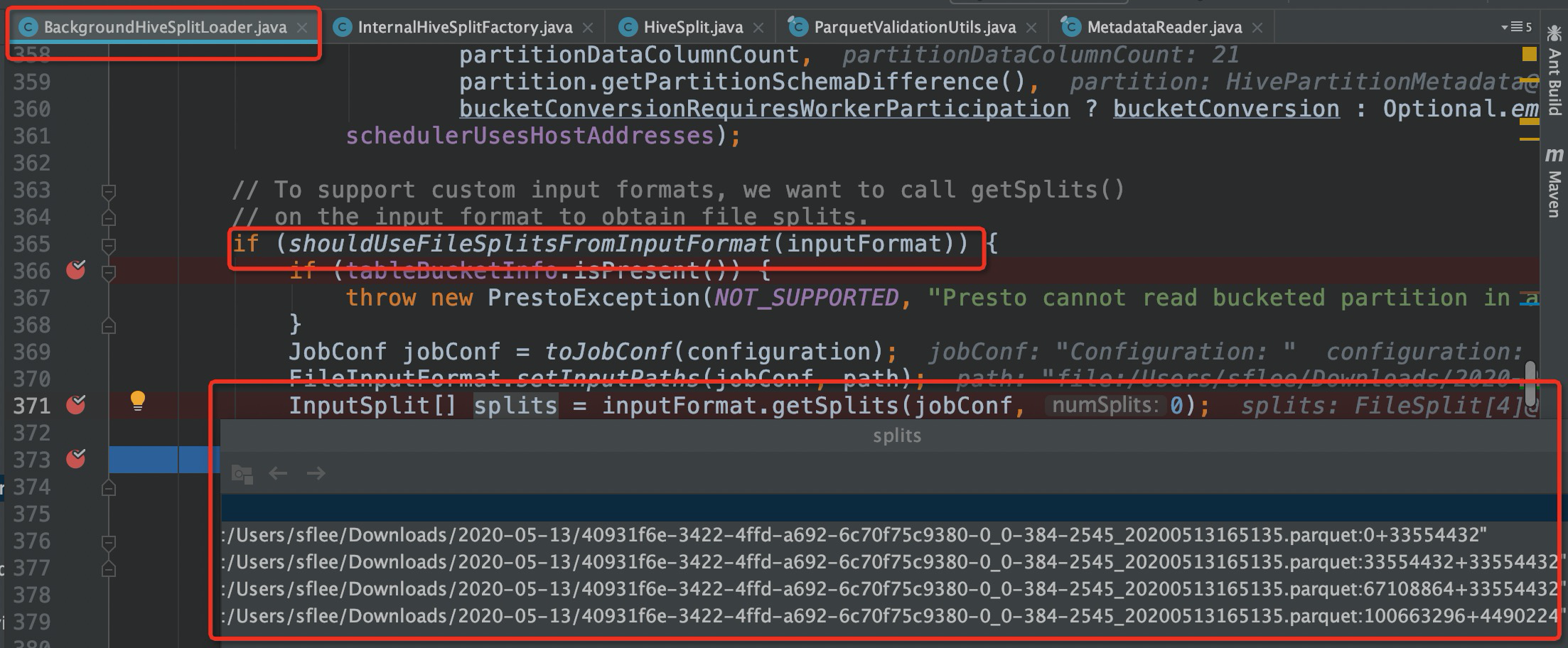
通过shouldUseFileSplitsFromInputFormat方法判断是否直接通过注解(@UseFileSplitsFromInputFormat)获取FileSplit。Hudi与外部系统交互的HoodieParquetInputFormat和HoodieParquetRealtimeInputFormat两个类都使用了该注解。
从上图可以看到100MB的文件被分成了四个InputSplit(按照32MB大小进行切分),后续Presto会根据InputSplit来构造对应的InternalHiveSplit。
进一步在异常堆栈地方打断点如下
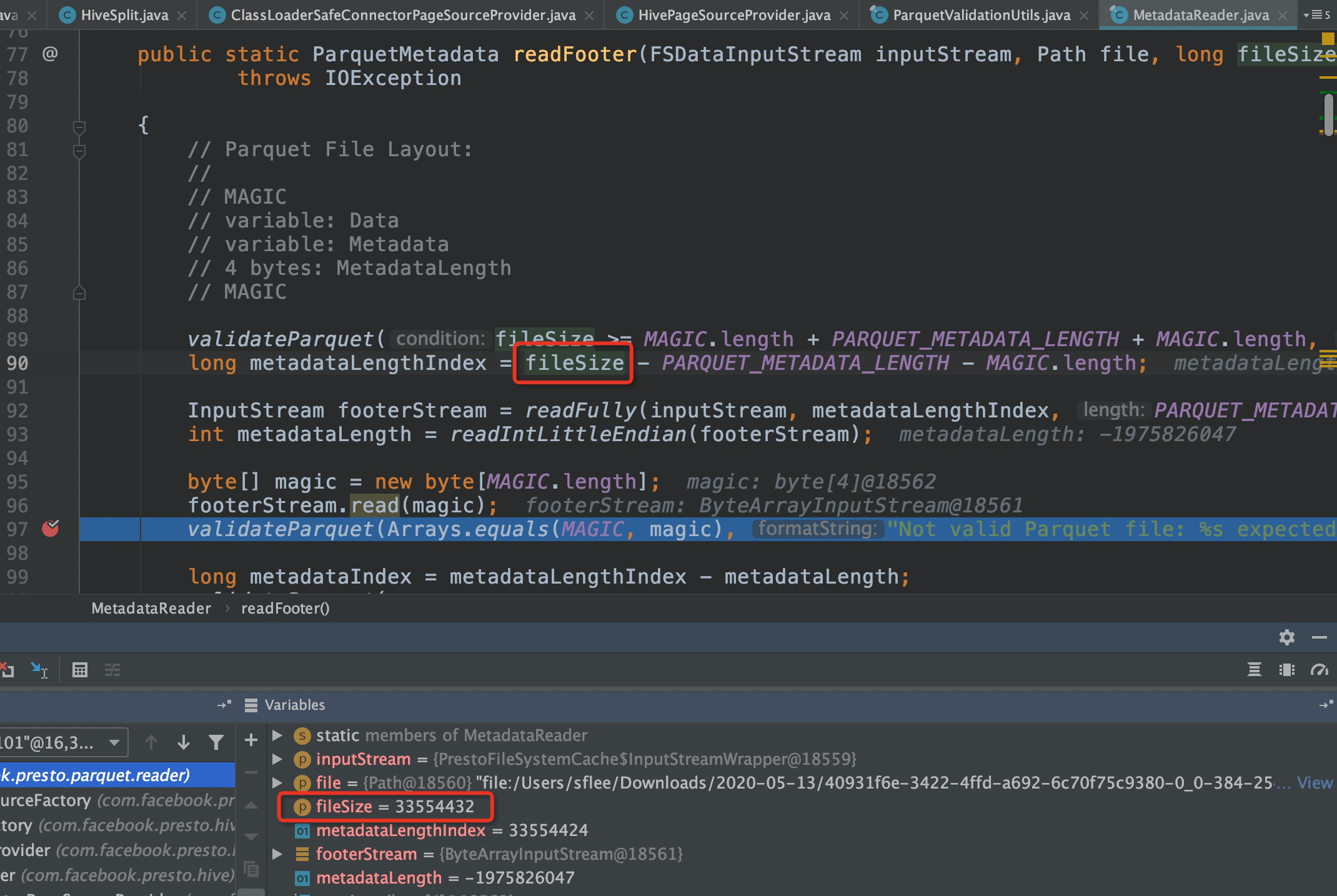
根据上述代码逻辑可知,从文件中读取magic与parquet文件的MAGIC不相等导致抛出了异常。
值得注意的是fileSize的大小为33554432,表示一个InputSplit的大小,而并非文件大小,因此获取metadataLength时并不准确,导致并非读取了parquet文件的magic,而是读取了InputSplit的数据,因此校验时抛出异常。理论上对于不同的InputSplit,该方法传入的fileSize大小应该等于文件的大小,而非InputSplit的大小,那么这个fileSize的大小是在哪个步骤传递错误的呢?带着这个疑问,继续进行debug。
根据前面debug信息得知Presto会通过InputSplit创建InternalHiveSplit,继续debug生成InternalHiveSplit的逻辑
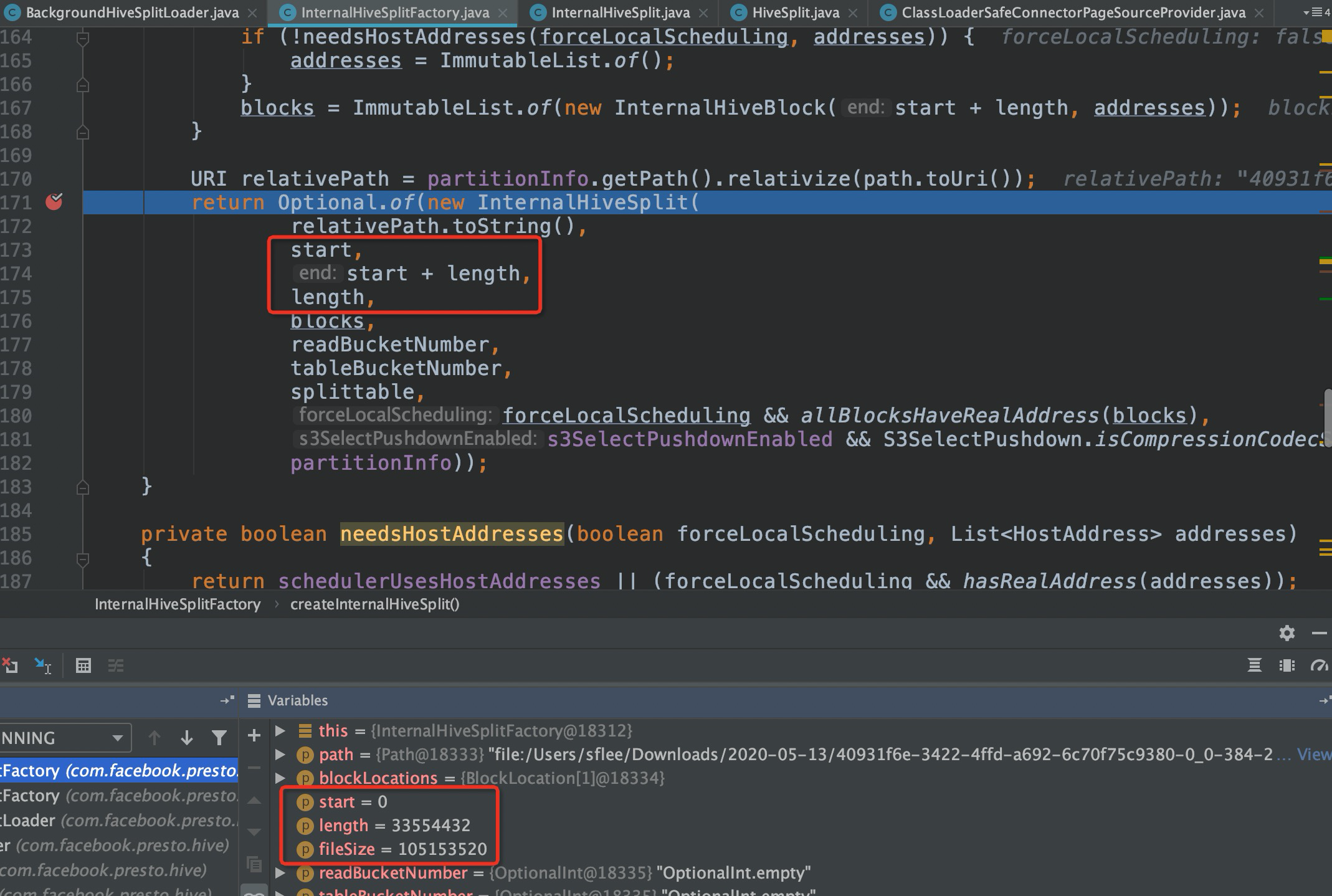
可以看到在上面构造InternalHiveSplit时,传递的参数值为start=0、start + length=33554432,length=33554432,而InternalHiveSplit本身的参数对应为start、end、fileSize,可以看到错误地将length当成fileSize传递了。
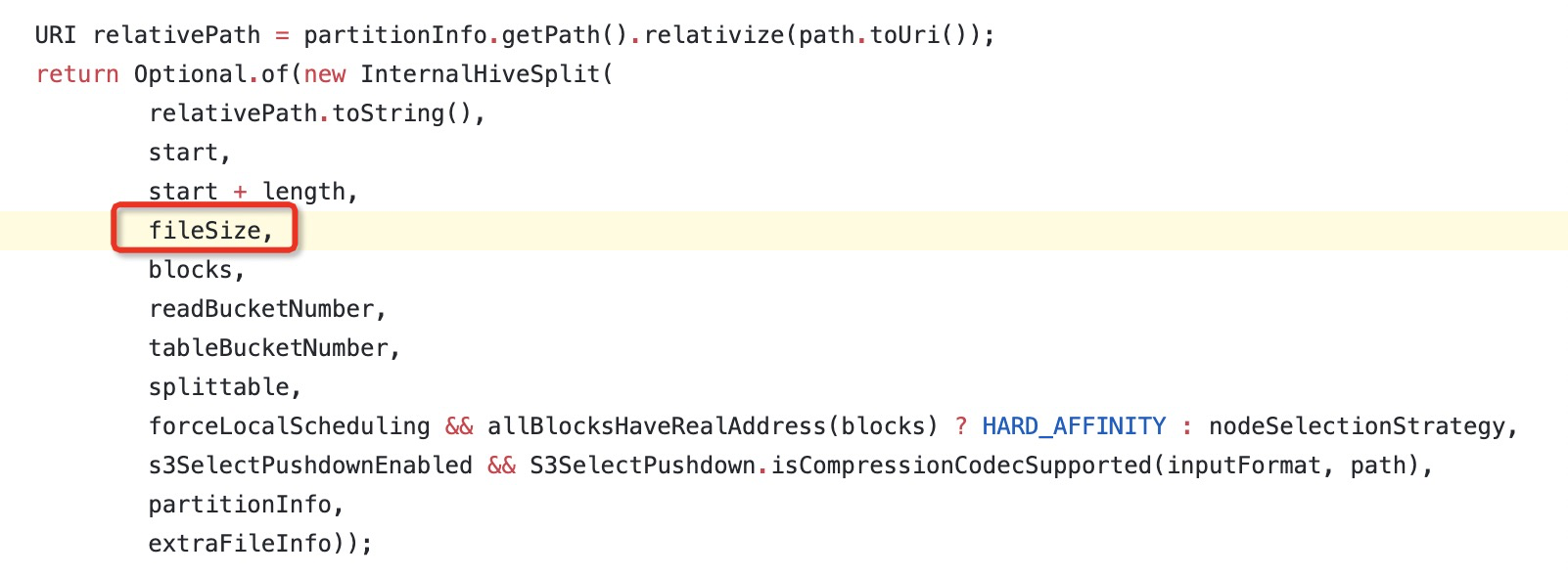
既然怀疑这个参数传递错误导致了异常,那么修改参数为fileSize后是否可以修复该问题?于是打包验证观察异常是否还会出现,即对presto-hive模块重新打包,放入$PRESTO_HOME/plugin/presto-hive目录中,重启Presto服务,再次进行验证。

可以看到修改参数后,查询一切正常!!!
另外对Hudi的小文件也进行了回归测试,查询也正常!自此可以发现是由于参数不对的bug导致了异常,鉴于这个bug对Presto社区其他用户也可能产生影响,于是查看Presto的master分支是否修复了该问题,若未修复,可将该patch回推到社区,于是查看了Presto的master分支对应代码,发现已经有开发者修复了!
3.4 影响的版本
由于该缺陷是在2019年5月引入Presto社区,在2020年4月得以修复,期间发布的版本(0.221 ~ 0.235)都会受到影响,如本地测试0.227、0.231版本都有问题。最近社区发布了0.236版本修复了该问题,如果生产环境使用的版本在0.221 ~ 0.235之间,建议升级或者cherry-pick对应的patch。
4. 总结
根据线上用户反馈查询Hudi表问题,由于线上环境不好debug,需根据上线环境在本地模拟复现问题,然后快速debug排查修复问题。当然本篇文章省略了debug的旁路路径,只给出了debug的关键路径。