1. 概述
当向Flink集群提交用户作业时,从用户角度看,只需要作业处理逻辑正确,输出正确的结果即可;而不用关心作业何时被调度的,作业申请的资源又是如何被分配的以及作业何时会结束;但是了解作业在运行时的具体行为对于我们深入了解Flink原理有非常大的帮助,并且对我们如何编写更合理的作业逻辑有指导意义,因此本文详细分析作业的调度及资源分配以及作业的生命周期。
2. 流程分析
基于社区master主线(1.11-SNAPSHOT),commit: 12f7873db54cfbc5bf853d66ccd4093f9b749c9a ,HA基于ZK实现分析
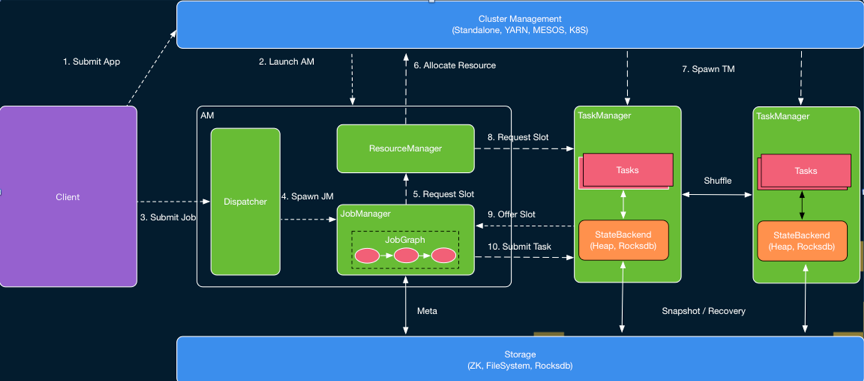
上图概括了Flink作业从Client端提交到到Flink集群的提交的基本流程[1]。
当运行./flink run脚本提交用户作业至Dispathcer后,Dispatcher会拉起JobManagerRunner,而后JobManagerRunner会向Zookeeper注册竞争Leader。对于之前流程有兴趣可以参考 深入理解Flink-On-Yarn模式
当JobManagerRunner竞争成为Leader时,会调用JobManagerRunnerImpl#grantLeadership,此时便开始处理作业,会通过如下的代码调用路径启动JobMaster。
- JobManagerRunnerImpl#grantLeadership
- JobManagerRunnerImpl#verifyJobSchedulingStatusAndStartJobManager
- JobManagerRunnerImpl#startJobMaster。
startJobMaster方法会首先将该作业的ID写入对应的ZK目录并置为RUNNING状态,写入该目录可用于在Dispathcer接收作业时,判断该作业是否重复提交或恢复作业时使用;在JobManagerRunner调度作业时也在从ZK上拉取作业信息来判断作业状态,若为DONE状态,则无需调度。启动JobMaster时会先启动其RPC Endpoint,以便与其他组件进行RPC调用,之后JobMaster便通过JobMaster#startJobExecution开始执行作业,执行作业前会有些前置校验,如必须确保运行在主线程中;启动JobMaster上的一些服务(组件),如TaskManager和ResourceManager的心跳管理;启动SlotPool、Scheduler;重连至ResourceManager,并且在ZK中注册监听ResourceManager Leader的变化的Retriever等。
当初始化完JobMaster上相应服务(组件)后,便开始调度,会有如下代码调用路径 - JobMaster#start
- JobMaster#startJobExecution
- JobMaster#resetAndStartScheduler
- JobMaster#startScheduling
- SchedulerBase#startScheduling。
我们知道用户编写的作业是以JobGraph提交到Dispatcher,但是在实际调度时会将JobGraph转化为ExecutionGraph,JobGraph生成ExecutionGraph是在SchedulerBase对象初始化的时候完成转化,如下图所示表示了典型的转化过程(JobVertex与ExecutionJobVertex一一对应),而具体的转化逻辑实现可参考如何生成ExecutionGraph及物理执行图

在SchedulerBase初始化时生成ExecutionGraph后,之后便基于ExecutionGraph调度,而调度基类SchedulerBase默认实现为DefaultScheduler,会继续通过DefaultScheduler#startSchedulingInternal调度作业,此时会将作业(ExecutionGraph)的状态从CREATED状态变更为RUNNING状态,此时在Flink web界面查看任务的状态便已经为RUNNING,但注意此时作业(各顶点)实际并未开始调度,顶点还是处于CREATED状态,任作业状态与顶点状态不完全相关联,有其各自的演化生命周期,具体可参考Flink作业调度[2];然后根据不同的策略EagerSchedulingStrategy(主要用于流式作业,所有顶点(ExecutionVertex)同时开始调度)和LazyFromSourcesSchedulingStrategy(主要用于批作业,从Source开始开始调度,其他顶点延迟调度)调度。
当提交流式作业时,会有如下代码调用路径:
- EagerSchedulingStrategy#startScheduling
- EagerSchedulingStrategy#allocateSlotsAndDeploy,在部署之前会根据待部署的ExecutionVertex生成对应的ExecutionVertexDeploymentOption,然后调用DefaultScheduler#allocateSlotsAndDeploy开始部署。同样,在部署之前也需要进行一些前置校验(ExecutionVertex对应的Execution的状态必须为CREATED),接着将待部署的ExecutionVertex对应的Execution状态变更为SCHEDULED,然后开始为ExecutionVertex分配Slot。会有如下的调用代码路径:
- DefaultScheduler#allocateSlots(该过程会ExecutionVertex转化为ExecutionVertexSchedulingRequirements,会封装包含一些location信息、sharing信息、资源信息等)
- DefaultExecutionSlotAllocator#allocateSlotsFor,该方法会开始逐一异步部署各ExecutionVertex,部署也是根据不同的Slot提供策略来分配,接着会经过如下代码调用路径层层转发,SlotProviderStrategy#allocateSlot -> SlotProvider#allocateSlot(SlotProvider默认实现为SchedulerImpl) -> SchedulerImpl#allocateSlotInternal -> SchedulerImpl#internalAllocateSlot(该方法会根据vertex是否共享slot来分配singleSlot/SharedSlot),以singleSlot为例说明。
在分配slot时,首先会在JobMaster中SlotPool中进行分配,具体是先SlotPool中获取所有slot,然后尝试选择一个最合适的slot进行分配,这里的选择有两种策略,即按照位置优先和按照之前已分配的slot优先;若从SlotPool无法分配,则通过RPC请求向ResourceManager请求slot,若此时并未连接上ResourceManager,则会将请求缓存起来,待连接上ResourceManager后再申请。
当ResourceManager收到申请slot请求时,若发现该JobManager未注册,则直接抛出异常;否则将请求转发给SlotManager处理,SlotManager中维护了集群所有空闲的slot(TaskManager会向ResourceManager上报自己的信息,在ResourceManager中由SlotManager保存Slot和TaskManager对应关系),并从其中找出符合条件的slot,然后向TaskManager发送RPC请求申请对应的slot。
等待所有的slot申请完成后,然后会将ExecutionVertex对应的Execution分配给对应的Slot,即从Slot中分配对应的资源给Execution,完成分配后可开始部署作业。
部署作业代码调用路径如下:
- DefaultScheduler#waitForAllSlotsAndDeploy
- DefaultScheduler#deployAll
- DefaultScheduler#deployOrHandleError
- DefaultScheduler#deployTaskSafe
- DefaultExecutionVertexOperations#deploy
- ExecutionVertex#deploy
- Execution#deploy(每次调度ExecutionVertex,都会有一个Execute,在此阶段会将Execution的状态变更为DEPLOYING状态,并且为该ExecutionVertex生成对应的部署描述信息,然后从对应的slot中获取对应的TaskManagerGateway,以便向对应的TaskManager提交Task)
- RpcTaskManagerGateway#submitTask(此时便将Task通过RPC提交给了TaskManager)。
TaskManager(TaskExecutor)在接收到提交Task的请求后,会经过一些初始化(如从BlobServer拉取文件,反序列化作业和Task信息、LibaryCacheManager等),然后这些初始化的信息会用于生成Task(Runnable对象),然后启动该Task,其代码调用路径如下 Task#startTaskThread(启动Task线程)-> Task#run(将ExecutionVertex状态变更为RUNNING状态,此时在FLINK web前台查看顶点状态会变更为RUNNING状态,另外还会生成了一个AbstractInvokable对象,该对象是FLINK衔接执行用户代码的关键,而后会经过如下调用
- AbstractInvokable#invoke(AbstractInvokable有几个关键的子类实现, BatchTask/BoundedStreamTask/DataSinkTask/DataSourceTask/StreamTask/SourceStreamTask。对于streaming类型的Source,会调用StreamTask#invoke)
- StreamTask#invoke
- StreamTask#beforeInvoke
- StreamTask#initializeStateAndOpen(初始化状态和进行初始化,这里会调用用户的open方法(如自定义实现的source))-> StreamTask#runMailboxLoop,便开始处理Source端消费的数据,并流入下游算子处理。
至此作业从提交到资源分配及调度运行整体流程就已经分析完毕,对于流式作业而言,正常情况下其会一直运行,不会结束。
3. 总结
对于作业的运行,会先提交至Dispatcher,由Dispatcher拉起JobManagerRunner,在JobManagerRunner成为Leader后,便开始处理作业,首先会根据JobGraph生成对应的ExecutionGraph,然后开始调度,作业的状态首先会变更为RUNNING,然后对各ExecutionVertex申请slot,申请slot会涉及JM与RM、TM之间的通信,当在TM上分配完slot后,便可将Task提交至TaskManager,然后TaskManager会为每个提交的Task生成一个单独的线程处理。