参考:http://blog.csdn.net/augusdi/article/details/12833235 第二节
新建NVIDIA项目:
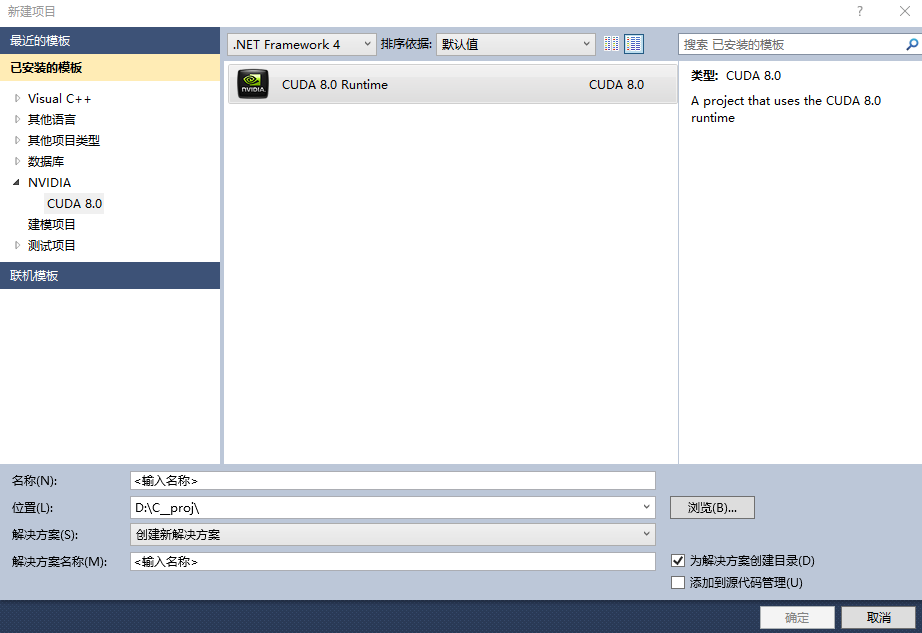
新建项目及会生成一个简单的代码demo,计算矩阵的加法,如下(main中加了一些显示显卡性能的打印):
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size); __global__ void addKernel(int *c, const int *a, const int *b) { int i = threadIdx.x; c[i] = a[i] + b[i]; } int main() { const int arraySize = 5; const int a[arraySize] = { 1, 2, 3, 4, 5 }; const int b[arraySize] = { 10, 20, 30, 40, 50 }; int c[arraySize] = { 0 }; // Add vectors in parallel. cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize); if (cudaStatus != cudaSuccess) { fprintf(stderr, "addWithCuda failed!"); return 1; } printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d} ", c[0], c[1], c[2], c[3], c[4]); // cudaDeviceReset must be called before exiting in order for profiling and // tracing tools such as Nsight and Visual Profiler to show complete traces. cudaStatus = cudaDeviceReset(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceReset failed!"); return 1; } int deviceCount; cudaGetDeviceCount(&deviceCount); int dev; for (dev = 0; dev < deviceCount; dev++) { cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); if (dev == 0) { if (/*deviceProp.major==9999 && */deviceProp.minor = 9999&&deviceProp.major==9999) printf(" "); } printf(" Device%d:"%s" ", dev, deviceProp.name); printf("Total amount of global memory %u bytes ", deviceProp.totalGlobalMem); printf("Number of mltiprocessors %d ", deviceProp.multiProcessorCount); printf("Total amount of constant memory: %u bytes ", deviceProp.totalConstMem); printf("Total amount of shared memory per block %u bytes ", deviceProp.sharedMemPerBlock); printf("Total number of registers available per block: %d ", deviceProp.regsPerBlock); printf("Warp size %d ", deviceProp.warpSize); printf("Maximum number of threada per block: %d ", deviceProp.maxThreadsPerBlock); printf("Maximum sizes of each dimension of a block: %d x %d x %d ", deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]); printf("Maximum size of each dimension of a grid: %d x %d x %d ", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]); printf("Maximum memory pitch : %u bytes ", deviceProp.memPitch); printf("Texture alignmemt %u bytes ", deviceProp.texturePitchAlignment); printf("Clock rate %.2f GHz ", deviceProp.clockRate*1e-6f); } printf(" Test PASSED "); getchar(); return 0; } // Helper function for using CUDA to add vectors in parallel. cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size) { int *dev_a = 0; int *dev_b = 0; int *dev_c = 0; cudaError_t cudaStatus; // Choose which GPU to run on, change this on a multi-GPU system. cudaStatus = cudaSetDevice(0); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); goto Error; } // Allocate GPU buffers for three vectors (two input, one output) . cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } // Copy input vectors from host memory to GPU buffers. cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } // Launch a kernel on the GPU with one thread for each element. addKernel<<<1, size>>>(dev_c, dev_a, dev_b); // Check for any errors launching the kernel cudaStatus = cudaGetLastError(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "addKernel launch failed: %s ", cudaGetErrorString(cudaStatus)); goto Error; } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. cudaStatus = cudaDeviceSynchronize(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel! ", cudaStatus); goto Error; } // Copy output vector from GPU buffer to host memory. cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } Error: cudaFree(dev_c); cudaFree(dev_a); cudaFree(dev_b); return cudaStatus; }