我们在上篇笔记中介绍了感知机的理论知识,讨论了感知机的由来、工作原理、求解策略、收敛性。这篇笔记中,我们亲自动手写代码,使用感知机算法解决实际问题。
先从一个最简单的问题开始,用感知机算法解决OR逻辑的分类。
import numpy as np
import matplotlib.pyplot as plt
x = [0,0,1,1]
y = [0,1,0,1]
plt.scatter(x[0],y[0], color="red",label="negative")
plt.scatter(x[1:],y[1:], color="green",label="positive")
plt.legend(loc="best")
plt.show()

下面我们来定义一个函数,用来判定一个样本点是否被正确分类了。由于此例中样本点是二维的,因此权重向量也相应的为二维,可以定义为(w = (w_1, w_2)),在Python中可以使用列表来表达,例如w = [0, 0],而样本到超平面的距离自然就是w[0] * x[0] + w[1] * x[1] +b。下面给出完整的函数。
def decide(data,label,w,b):
result = w[0] * data[0] + w[1] * data[1] - b
print("result = ",result)
if np.sign(result) * label <= 0:
w[0] += 1 * (label - result) * data[0]
w[1] += 1 * (label - result) * data[1]
b += 1 * (label - result)*(-1)
return w,b
写完核心函数后,我们还需要写一个调度函数,这个函数提供遍历每一个样本点的功能。
def run(data, label):
w,b = [0,0],0
for epoch in range(10):
for item in zip(data, label):
dataset,labelset = item[0],item[1]
w,b = decide(dataset, labelset, w, b)
print("dataset = ",dataset, ",", "w = ",w,",","b = ",b)
print(w,b)
data = [(0,0),(0,1),(1,0),(1,1)]
label = [0,1,1,1]
run(data,label)
result = 0
dataset = (0, 0) , w = [0, 0] , b = 0
result = 0
dataset = (0, 1) , w = [0, 1] , b = -1
result = 1
dataset = (1, 0) , w = [0, 1] , b = -1
result = 2
dataset = (1, 1) , w = [0, 1] , b = -1
result = 1
dataset = (0, 0) , w = [0, 1] , b = 0
result = 1
dataset = (0, 1) , w = [0, 1] , b = 0
result = 0
dataset = (1, 0) , w = [1, 1] , b = -1
result = 3
dataset = (1, 1) , w = [1, 1] , b = -1
result = 1
dataset = (0, 0) , w = [1, 1] , b = 0
result = 1
dataset = (0, 1) , w = [1, 1] , b = 0
result = 1
后面的迭代这里省略不贴,参数稳定下来,算法已经收敛
下面看一个来自UCI的数据集:PIMA糖尿病数据集,例子来自《机器学习算法视角》第三章
import os
import pylab as pl
import numpy as np
import pandas as pd
os.chdir(r"DataSetspima-indians-diabetes-database")
pima = np.loadtxt("pima.txt", delimiter=",", skiprows=1)
pima.shape
(768, 9)
indices0 = np.where(pima[:,8]==0)
indices1 = np.where(pima[:,8]==1)
pl.ion()
pl.plot(pima[indices0,0],pima[indices0,1],"go")
pl.plot(pima[indices1,0],pima[indices1,1],"rx")
pl.show()
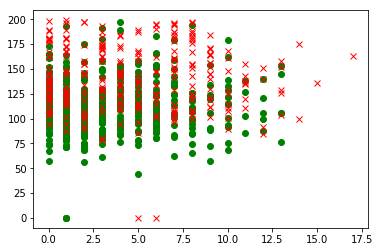
数据预处理
1.将年龄离散化
pima[np.where(pima[:,7]<=30),7] = 1
pima[np.where((pima[:,7]>30) & (pima[:,7]<=40)),7] = 2
pima[np.where((pima[:,7]>40) & (pima[:,7]<=50)),7] = 3
pima[np.where((pima[:,7]>50) & (pima[:,7]<=60)),7] = 4
pima[np.where(pima[:,7]>60),7] = 5
2.将女性的怀孕次数大于8次的统一用8次代替
pima[np.where(pima[:,0]>8),0] = 8
3.将数据标准化处理
pima[:,:8] = pima[:,:8]-pima[:,:8].mean(axis=0)
pima[:,:8] = pima[:,:8]/pima[:,:8].var(axis=0)
4.切分训练集和测试集
trainin = pima[::2,:8]
testin = pima[1::2,:8]
traintgt = pima[::2,8:9]
testtgt = pima[1::2,8:9]
定义模型
class Perceptron:
def __init__(self, inputs, targets):
# 设置网络规模
# 记录输入向量的维度,神经元的维度要和它相等
if np.ndim(inputs) > 1:
self.nIn = np.shape(inputs)[1]
else:
self.nIn = 1
# 记录目标向量的维度,神经元的个数要和它相等
if np.ndim(targets) > 1:
self.nOut = np.shape(targets)[1]
else:
self.nOut = 1
# 记录输入向量的样本个数
self.nData = np.shape(inputs)[0]
# 初始化网络,这里加1是为了包含偏置项
self.weights = np.random.rand(self.nIn + 1, self.nOut) * 0.1 - 0.05
def train(self, inputs, targets, eta, epoch):
"""训练环节"""
# 和前面处理偏置项同步地,这里对输入样本加一项-1,与W0相匹配
inputs = np.concatenate((inputs, -np.ones((self.nData,1))),axis=1)
for n in range(epoch):
self.activations = self.forward(inputs)
self.weights -= eta * np.dot(np.transpose(inputs), self.activations - targets)
return self.weights
def forward(self, inputs):
"""神经网路前向传播环节"""
# 计算
activations = np.dot(inputs, self.weights)
# 判断是否激活
return np.where(activations>0, 1, 0)
def confusion_matrix(self, inputs, targets):
# 计算混淆矩阵
inputs = np.concatenate((inputs, -np.ones((self.nData,1))),axis=1)
outputs = np.dot(inputs, self.weights)
nClasses = np.shape(targets)[1]
if nClasses == 1:
nClasses = 2
outputs = np.where(outputs<0, 1, 0)
else:
outputs = np.argmax(outputs, 1)
targets = np.argmax(targets, 1)
cm = np.zeros((nClasses, nClasses))
for i in range(nClasses):
for j in range(nClasses):
cm[i,j] = np.sum(np.where(outputs==i, 1,0) * np.where(targets==j, 1, 0))
print(cm)
print(np.trace(cm)/np.sum(cm))
print("Output after preprocessing of data")
p = Perceptron(trainin,traintgt)
p.train(trainin,traintgt,0.15,10000)
p.confusion_matrix(testin,testtgt)
Output after preprocessing of data
[[ 69. 86.]
[182. 47.]]
0.3020833333333333
这个案例使用感知机训练得到的结果比较糟糕,这里只是作为展示算法的例子。
最后看一个使用感知机算法识别MNIST手写数字的例子。代码借鉴了Kaggle上的kernel。
step 1:首先导入所需的包,并且设置好数据所在路径
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
train = pd.read_csv(r"DataSetsDigit_Recognizer rain.csv", engine="python")
test = pd.read_csv(r"DataSetsDigit_Recognizer est.csv", engine="python")
print("Training set has {0[0]} rows and {0[1]} columns".format(train.shape))
print("Test set has {0[0]} rows and {0[1]} columns".format(test.shape))
Training set has 42000 rows and 785 columns
Test set has 28000 rows and 784 columns
step 2:数据预处理
-
创建
label,它的size为 (42000, 1) -
创建
training set,size为(42000, 784) -
创建
weights,size为(10,784),这可能有点不好理解。我们知道,权重向量是描述神经元的,784是维度,表示一个输入样本有784维,相应的与它对接的神经元也要有784维。同时,要记住一个神经元只能输出一个output,而在数字识别问题中,我们期待的是输入一个样本数据,能返回10个数字,然后依概率判断这个样本是哪个数字的可能性最大。所以,我们需要10个神经元,这就是(10,784)的来历。
trainlabels = train.label
trainlabels.shape
(42000,)
traindata = np.asmatrix(train.loc[:,"pixel0":])
traindata.shape
(42000, 784)
weights = np.zeros((10,784))
weights.shape
(10, 784)
这里可以先看一个样本,找找感觉。注意原数据是压缩成了784维的数组,我们需要将它变回28*28的图片
# 从矩阵中随便取一行
samplerow = traindata[123:124]
# 重新变成28*28
samplerow = np.reshape(samplerow, (28,28))
plt.imshow(samplerow, cmap="hot")
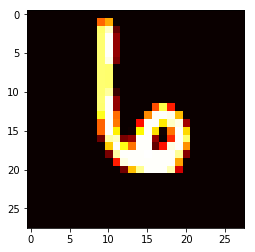
step 3:训练
这里我们对训练数据集循环若干次,然后重点关注错误率曲线
# 先创建一个列表,用来记录每一轮训练的错误率
errors = []
epoch = 20
for epoch in range(epoch):
err = 0
# 对每一个样本(亦矩阵中的每一行)
for i, data in enumerate(traindata):
# 创建一个列表,用来记录每个神经元输出的值
output = []
# 对每个神经元都做点乘操作,并记录下输出值
for w in weights:
output.append(np.dot(data, w))
# 这里简单的取输出值最大者为最有可能的
guess = np.argmax(output)
# 实际的值为标签列表中对应项
actual = trainlabels[i]
# 如果估计值和实际值不同,则分类错误,需要更新权重向量
if guess != actual:
weights[guess] = weights[guess] - data
weights[actual] = weights[actual] + data
err += 1
# 计算迭代完42000个样本之后,错误率 = 错误次数/样本个数
errors.append(err/42000)
x = list(range(20))
plt.plot(x, errors)
[<matplotlib.lines.Line2D at 0x5955c50>]

从图可以看出,达到15次迭代时,错误率已经有上升的趋势了,开始过拟合了。
感知机是一个非常简单的算法,以致于很难在真正的场景中使用感知机算法。这里举的3个例子,都旨在于动手写代码实现这个算法,找找感觉。稍有经验的读者想必会好奇:为什么没有使用Scikit-Learn这个包,这部分其实是笔者另有计划,打算结合算法写Scikit-Learn的源码解读笔记。当然,限于个人水平,不一定能解析到精髓,但勉力而为吧。下篇会写Multi-Layer-Perceptron算法的原理,在那里我们很容易看到,纵使是简单的感知机,只要加一个隐层,就能大幅提升其分类能力。另外,也会抽空写一篇感知机Sklearn源码解读的文章。有任何问题,欢迎大家留言讨论。
