配置前先把域名映射配好哈 详情参考我的其他随笔(已对随笔分类)
下载好hdfs.tar.gz 后
在/home/ldy下
mkdir apps/
tar -xzvf hdfs.tar.gz -C /home/ldy/apps/ #专门用来安装hdfs 和jdk的
修改环境变量:vim /etc/profile
在最后的fi上面添加
export HDP_HOME=/home/ldy/apps/hadoop-2.8.5/etc/hadoop #路径因人而定
export PATH=$PATH:$HDP_HOME/sbin : $HDP_HOME/bin
hadoop-daemon.sh 等命令在sbin目录下(旧版的在bin下) 最好两个都配。jdk的配置也是一样的道理
当出现命令not found 时:source /etc/profile 即可
配置文件:
在/home/ldy/apps/hadoop-2.8.5/etc/hadoop下
vim hadoop-env.sh #告诉它java_home即可

Vim core-site.xml
如果你只有一个namenode的话,得将fs.defaultFS改成fs.default.name
<configuration> <property> <name>fs.default.name</name> <value>hdfs://ubuntu-00:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/hdpdata/hadoopdata</value> </property> </configuration>
Vim hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/hdpdata/hadoopdata/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hdpdata/hadoopdata/data</value> </property> <property> <name>dfs.http.address</name> <value>ubuntu-00:50070</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>ubuntu-00:50090</value> </property> </configuration>
vim slaves
这里记录了datenode服务器的主机名,域名映射配好后,启动集群后各服务器就可以互相连通了
注:core-site.xml配置错误会导致 incorrect namenode addr
name标签的值不可以修改
以上目录不存在会自动创建
9000端口负责客户端与服务端的交互
50070端口是一个外部服务器,可以通过该端口在浏览器访问namenode
域名映射后value值可以写主机名,且所有服务器的core-site.xml的地址必须一致,确保使用同一个文件系统
建议大家先配好一个服务器然后直接复制粘贴文件到其他服务器,省得麻烦
复制本地文件到其他服务器需要远程连接,开启ssh服务以及使用scp远程连接命令
注:需要连接的主机也要开通ssh以及安装scp
开启ssh:
运行 ps -e | grep ssh,查看是否有sshd进程
如果没有,说明server没启动,通过 /etc/init.d/ssh -start 启动server进程
如果提示ssh不存在 那么就是没安装server
安装server
1.sudo apt-get update
2.sudo apt-get install openssh-server
apt-get过程中可能出现:
E: Could not get lock /var/lib/dpkg/lock-frontend - open (11: Resource temporarly unavailable)
E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), is an other process using it?
当出现这个报错时直接:
sudo rm /var/lib/dpkg/lock-frontend
sudo rm /var/lib/dpkg/lock
sudo rm /var/lib/apt/lists/lock
然后 apt-get update
(scp属于ssh,开了ssh也就安装好了scp)
Scp :
scp -r /home/ldy/apps/hadoop-2.8.5 ubuntu-01:/home/ldy/apps/
#将本地的hadoop文件复制到ubuntu-01主机的apps目录下
报错: ssh连接The authenticity of host can't be established
修改/etc/ssh/ssh_config文件的配置
修改:(没有就在最后面添加)
StrictHostKeyChecking no
注:一般是禁止root用户登录的,切换到普通用户可正常使用
当出现这个错误时:
Permisson denied ,please try again
出现这个错误是因为请求被拒绝,是ssh的权限问题,需要修改ssh权限,切换root, 直接vim /etc/ssh/sshd_config

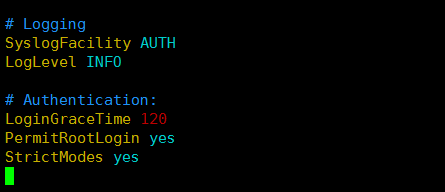
将PermitRootLogin no 改为 PermitRootLogin yes
记得重启ssh:sudo service ssh restart
在namenode服务器上:
vim etc/hadoop/slaves (加上所有服务器名)
hadoop namenode -format (一次就够了)
start-dfs.sh (开启namenode和datanode服务)
使用这个命令每次都要输密码,这里可以设一个免密登录,在namenode服务器上设、
当namenode访问其他服务器时,就不用输入密码了
免密登录:
ssh-keygen(一直回车就行)
ssh-copy-id 服务器名(有多少个服务器执行多少次这个命令, 这里需要输入yes,不能一直回车)
注意:虚拟机重启后得重新执行 start-dfs.sh,namenode和datanode才启动(其本质是软件)
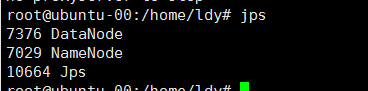
这样就成功了