What’s Your Next Move: User Activity Prediction in Location-based Social Networks
这篇文章来自于SDM’13年(SIAM InternationalConference on Data Mining 2013)的录用论文集,是关于在基于位置社交网络里面(LBSN)进行用户签到预測的。
本文解决这个问题的角度非常创新,并没有直接入手于用户签到预測问题。而是先预測用户的下一个签到活动类型,然后在此基础上。再预測用户的下一个签到位置。
1.1 论文总结
为了预測用户的下一个签到活动类型,作者利用隐含马尔可夫模型(HMM)对用户的活动转移进行建模,例如以下图所看到的:
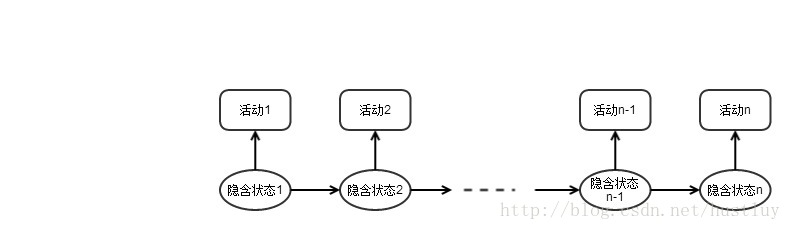
图1:HMM建模用户活动转移
这里面的解释是觉得用户从事某个活动的意愿是由其本身隐含的一个状态所决定的。
所以,依据观察到的用户活动序列,即活动1->活动2->...->活动n,能够採用保姆-韦尔奇训练算法(Baum-Welch Algorithm)来对HMM模型的參数进行训练,即各个隐含状态之间相互转化的概率,以及由某个隐含状态输出特定活动类型的概率。在获得这些參数之后。作者通过计算在已知模型參数和观察活动序列的情况下,最有可能达到的隐含状态n+1,然后通过隐含状态n+1来进一步计算活动n+1。
可是。这个模型只利用了活动的序列信息,没有考虑到地理位置、时间等因素。所以作者对模型进行改进,採用了混合的隐含马尔可夫模型(Mixed HMM)。添加了时空状态对输出活动类型的影响(如图2)。
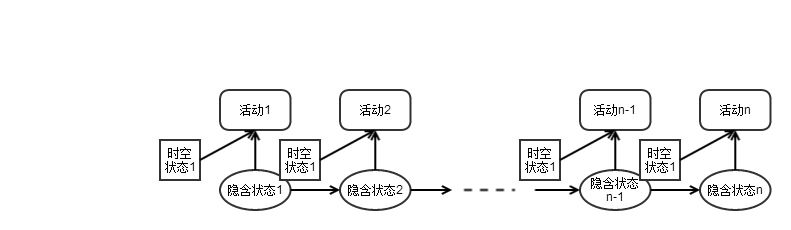
图2:Mixed HMM建模用户活动转移
因为用户签到数据的极大稀疏性,假设对每一个用户的活动序列都分别训练出一个个性化的Mixed HMM。所预计的模型參数势必是不准确的。可是,假设集合了全部用户的活动序列,训练一个公共的Mixed HMM来统一表示用户的活动转移。也是不大可能的。
因为用户间的活动转移有可能存在非常大差别。根本不可能採用一个模型来统一表示。作者在文中採用了一个折中的办法,首先依据每一个用户签到记录统计,对全部用户採用K-means方法进行聚类。然后,对每一类的用户的活动转移来分别用一个Mixed HMM来进行建模。这在文中被作者称为是考虑到了用户活动偏好来进行用户签到活动预測。
在预測得到用户的下一个签到活动类型之后,作者通过搜索以用户当前签到位置为中心的方圆400m×400m的区域范围内,签到类型为所预測类型的位置场所。将这些场所为候选集。作者提出了四种策略来对其进行排序:(1)签到数目。(2)签到用户数。(3)签到数与签到用户数的乘积。(4)单个用户的最大签到数。
对于top-k的预測方式。就选取前k个位置场所作为签到预測的结果。
1.2 读后感
长处:
(1)为了避免预測的不平衡性问题,即在庞大的位置候选集中选取某一个位置作为预測的下一个位置,作者将原问题分解为了两个子问题:预測用户的下一个签到活动类型;在预測的签到活动类型的基础上来预測用户的下一个签到位置。因为签到活动类型的数目是极其有限的,从而规避了预測的不平衡性问题。
(2)採用Mixed HMM来对用户的活动转移进行建模。从而包括了用户签到的时空信息。
缺点:
(1)在利用训练好的Mixed HMM来对用户的下一个签到活动类型进行预測的时候。不过通过预測最可能的下一个隐含状态n+1,然后依据输出概率矩阵,得到由这个隐含状态n+1最有可能输出的活动类型n+1。其实,没有必要确定下一个隐含状态n+1,直接通过计算输出每一个可能的活动类型n+1的概率,选取概率最大的活动类型就可以。这在时间复杂度上并没有添加额外的负担。
(2)在做签到位置预測的时候。作者并没有考虑到用户本身的历史签到位置。而是只选取用户当前位置附近的签到场所作为候选集,而且附近场所的范围选定为400m×400m。这个參数怎么确定的也没给个明白说法。而且依据文中提供的数据统计情况,用户的下一个签到位置距离其当前的位置有40%的情况是大于1km的。
所以,在做签到位置预測的时候,只考虑到用户附近的签到场所作为候选集是不是显得不大合理。
1.3 总结
关于签到位置预測的候选集问题。一般有两种决策。一是简单地把用户的历史签到位置作为候选集。这就假设用户往往在其签到位置反复签到。其实。对LBSN用户而言。这样的情况还是比較少见的。
第二种决策是将用户所在城市的全部签到场所作为候选集。
这个时候,因为候选集的过于庞大。而且须要从庞大的候选集中只选取一个位置作为预測结果。预測的不平衡性问题就要面对了。这篇文章给我们提供了一种解法。即将问题转移到活动预測。
因为在活动预測问题中,即使是将全部活动类型都作为候选集,也不会遭遇预測的不平衡性问题。