知道原理的同学这部分可以略过直接看实践部分
什么是TD-IDF?
构造文档模型
我们这里使用空间向量模型来数据化文档内容:向量空间模型中将文档表达为一个矢量。
用特征向量(T1,W1;T2,W2;T3, W3;…;Tn,Wn)表示文档。
Ti是词条项,Wi是Ti在文档中的重要程度, 即将文档看作是由一组相互独立的词条组构成,把T1,T2 …,Tn看成一个n 维坐标系中的坐标轴,对于每一词条,根据其重要程度赋以一定的权值Wi,作为对应坐标轴的坐标值。
权重Wi用词频表示,词频分为绝对词频和相对词频。
绝对词频,即用词在文本中出现的频率表示文本。
相对词频,即为归一化的词频,目前使用 最为频繁的是TF*IDF(Term Frequency * Inverse Document Frequency)TF乘IDF
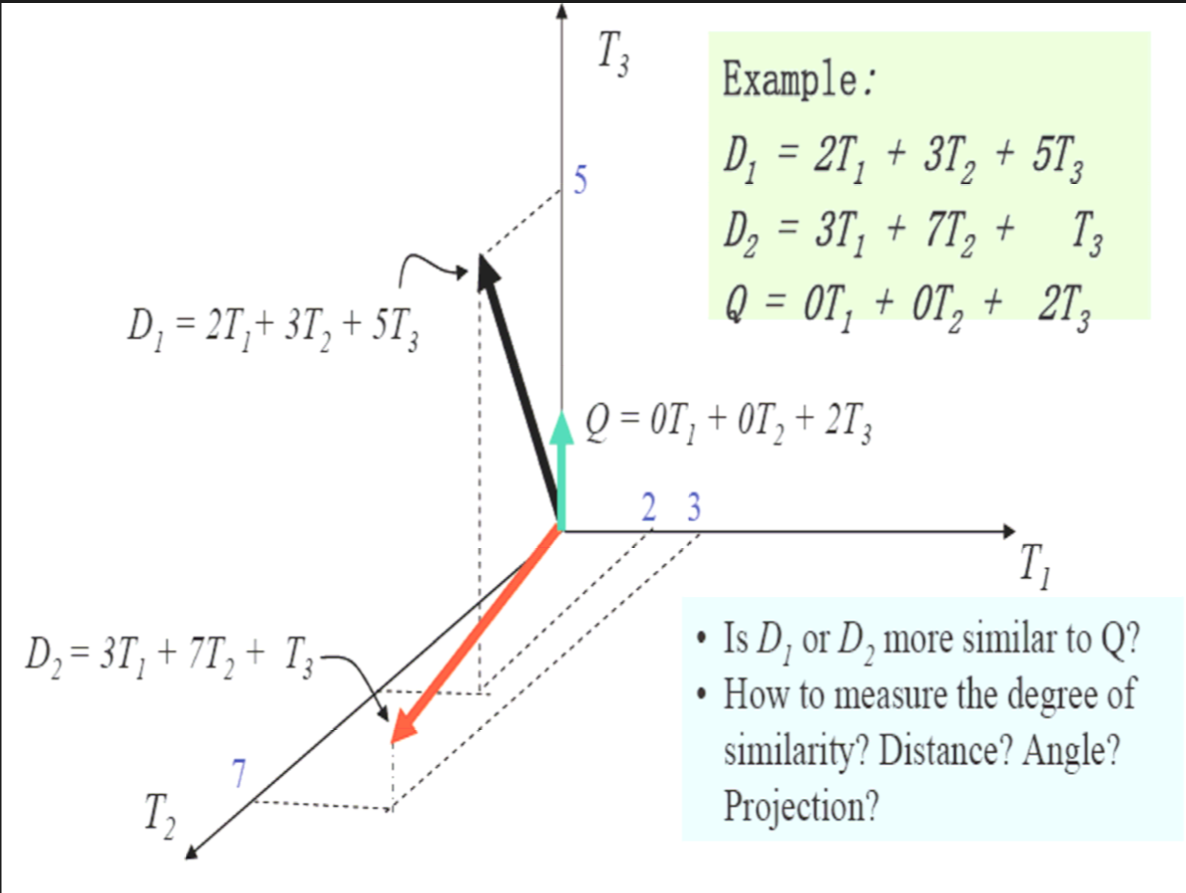
将文档量化了之后我们很容易看出D1与Q更相似~因为D1与Q的夹角小,我们可以用余弦cos表示
分析一下这个例子:
有三个文档D1,D2,Q
这三个文档一共出现了三个词条,我们分别用T1,T2,T3表示
在文档D1中词条T1的权重为2,T2权重为3,T3权重为5
在文档D2中词条T1权重为0,T2权重为7,T3权重为1
在文档Q中词条T1权重为0,T2权重为0,T3权重为2
| D1 | D2 | Q | |
| T1 | 2 | 3 | 0 |
| T2 | 3 | 7 | 0 |
| T3 | 3 | 1 | 2 |
接下来我们看tf*idf的公式:
tf:tf(d,t) 表示词条t 在文档d 中的出现次数
idf:idf(t)=log N/df(t)
-
df(t) 表示词条t 在文本集合中出现过的文本数目(词条t在哪些文档出现过) Inverse Document Frequency
-
N 表示文本总数
对于词条t和某一文本d来说,词条在该文本d的权重计算公式:
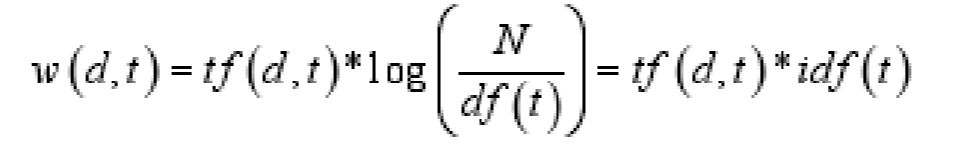
特征向量(T1,W1;T2,W2;T3, W3;…;Tn,Wn)就可以求出了!
是不是很简单呢~
进一步思考:
如果说一个词条t几乎在每一个文档中都出现过那么:
idf(t)=log N/df(t)
趋近于0,此时w(t)也趋近于0,从而使得该词条在文本中的权重很小,所以词 条对文本的区分度很低。
停用词:在英文中如a,of,is,in.....这样的词称为停用词,它们都区分文档的效果几乎没有,但是又几乎在每个文档中都出现,此时idf的好处就出来了
我们通常根据w(d,t)值的大小,选择 指定数目的词条作为文本的特征项,生 成文本的特征向量(去掉停用词)
这种算法一方面突 出了文档中用户需要的词,另一方面, 又消除了在文本中出现频率较高但与文本语义无关的词条的影响
文本间相似性 :
基于向量空间模型的常用方法,刚才我们提到过可以用余弦值来计算,下面我讲一下具体步骤
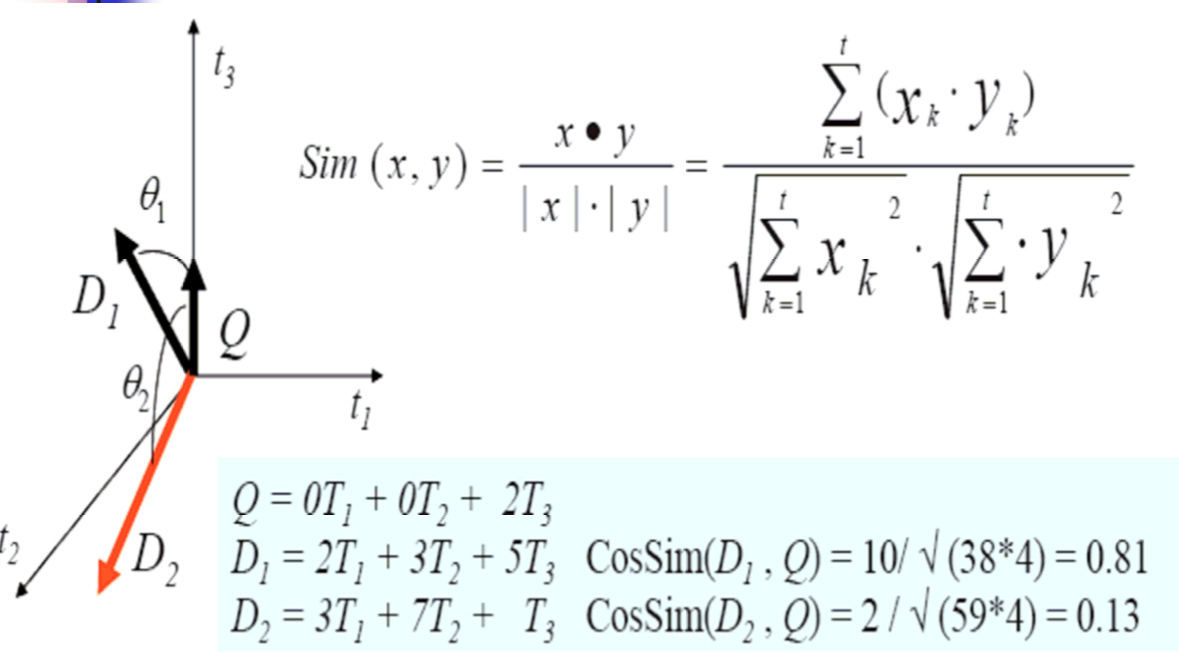
内积不会求得自行百度。。。。
为了提高计算效率:可以先算x^'=x/|x|,y^'=y/|y|;大量计算两两文档间相似度时,为降低计算量,先对文档进行向量进行单位化。
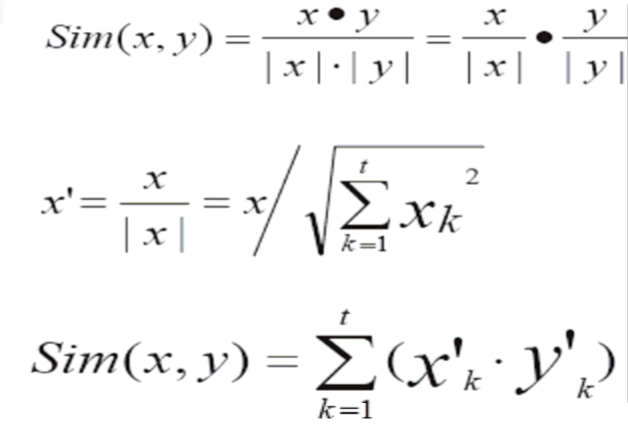
ok~tf*idf就先到这里
总结:
我们可以通过计算tf*idf的值来作为特征向量的权重,把权重为0的词去掉
然后通过计算特征向量之间的余弦值来判断相似性。