cookie与session简介及操作
cookie
保存在客户端浏览器上的键值对
虽然cookie是保存在客户端浏览器上的键值对 但是是服务端设置的 浏览器有权禁止cookie的写入
django中操作cookie
# 小白必回三板斧
obj = HttpResponse()
return obj # 效果都是一样的
# 设置cookie
obj.set_cookie('key','value') # 告诉浏览器设置
# 获取cookie
request.COOKIES.get('key') # 获取浏览器携带过来的cookies
# cookie的骚操作
def login(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('username')
if username == 'long' and password == '123':
# 登陆成功 设置cookie
obj = redirect('/home/')
obj.set_cookie('k1','long')
return obj
return render(request, 'test.html', locals())
# 校验用户是否登录
def home(requset):
if request.COOKIES.get('k1'):
return HttpResponse('登录成功')
return redirect('/login/')
cookie超时时间
# 如何设置cookie超时时间
obj.set_cookie('k1','v1', max_age=5) # 秒为单位
obj.set_cookie('k1','v1', expires=5) # 秒为单位
# 都是设置超时时间 并且都是秒为单位 区别: 给ie浏览器设置cookies设置超时时间 只能用 expires参数.
# 装饰器
from functools import wraps
def login_auth(func):
@wraps(func)
def inner(request,*args, **kwargs):
# 判断当前用户是否登录
if request.COOKIES.get('k1'):
res = func(request, *args, **kwargs)
return res
else:
current_url = request.path_info
return redirect('/login/?next=%s'%current_url)
return inner
request.path_info 只拿url
reque*st.get_full_path() 拿url 加get请求的部分
删除cookie
.....
obj = redirect('/login/')
obj.delete_cookie('k1')
return obj
session
保存在服务端上面的键值对
session的工作机制是需要依赖于cookie的
session操作
# 设置session
request.session['k1'] = 'v1'
# 获取session
request.session.get('k1')
# 拿到随机字符串
request.session.session_key()
# 存在则不设置
request.session.setdefault('k1',123)
# 检查会话session的key在数据库中是否存在
request.session.exists("session_key")
# 删除
request.session.delete()
request.session.flush() # 只删客户端
这用于确保前面的会话数据不可以再次被用户的浏览器访问
例如,django.contrib.auth.logout() 函数中就会调用它。
# 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
会自动将数据存在django_session表中 默认过期时间是 14 天
为了数据的安全 数据库中不会明文暴露用户信息 所以是密文
设置 key value发生了什么?
1.django内部自动帮你调用算法生成一个随机字符串
-
在django session添加数据 (数据也是加密的) >>> 随机字符串 加密后的数据 失效时间
-
将生产的随机字符串放回给客户端浏览器,
key是sessionidvalue是随机字符串sessionid:随机字符串
get(session)发生了什么?
1.django内部会自动去请求头里面获取cookie
2. 拿着`sessionid`对应的随机字符串去`django_session`表中一一比对
3. 如果对比上了 会将随机字符串对应的数据取出来 自动反入` request.session`中供你调用 如果没有就是一个空字典
django session 在创建数据的时候 是针对浏览器的 所以只会保存一条
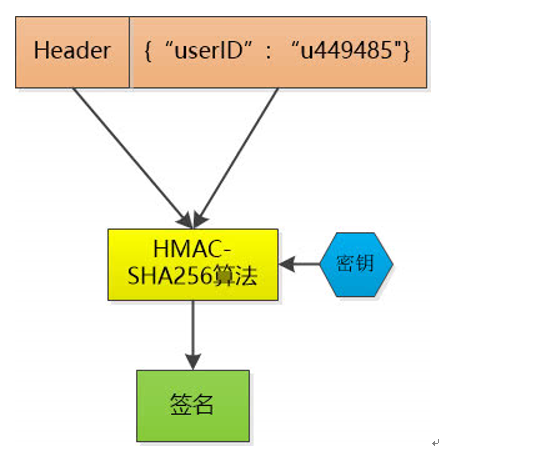
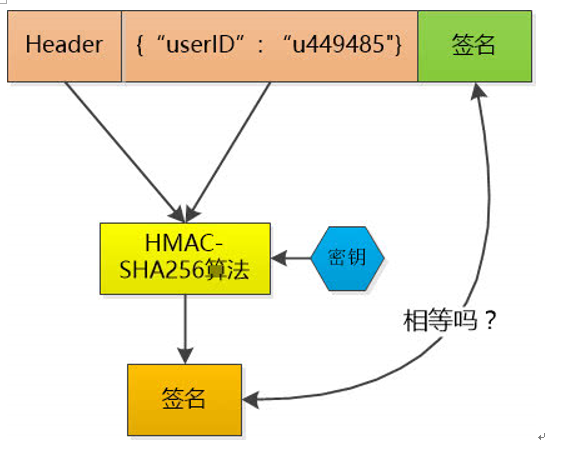
token
在计算机身份认证中是令牌(临时)的意思,在词法分析中是标记的意思。一般作为邀请、登录系统使用。
django中间件
django请求生命周期
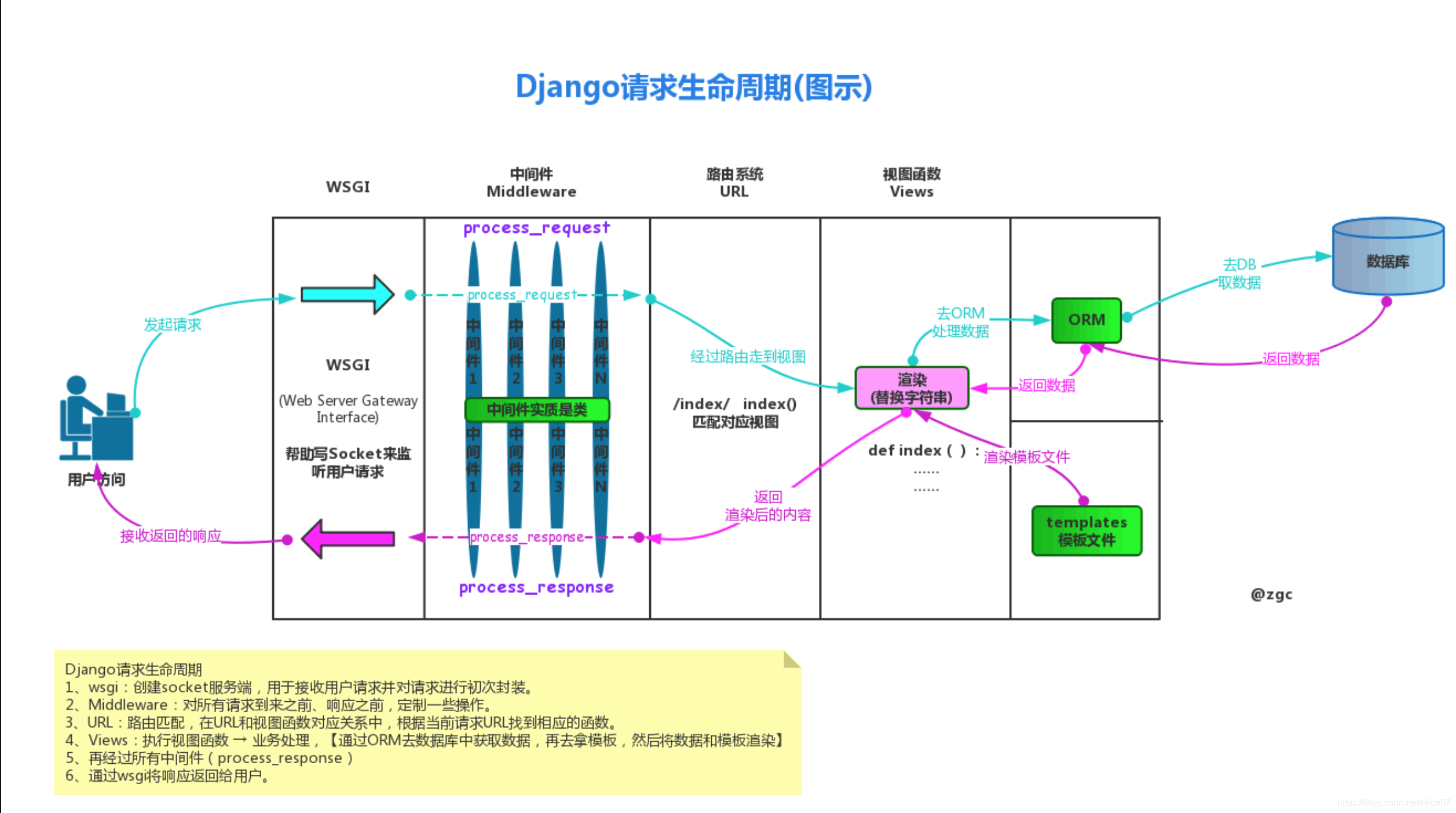
中间件
类似于django的保安 一共有 7 个中间件
并且支持用户自定义中间件 让后暴露给用户五个可以自定义的方法 随意创建一个py文件 填代码即可 写完后需要 注册 (****)
只要你想做一些网站的全局性功能 你都应该考虑使用django的中间件 比如: 全局的用户登录校验, 全局的用户访问频率校验, 全局的用户权限校验
需要掌握:
process_request 请求来的时候触发 参数 request
class SecurityMiddleware(MiddlewareMixin): # 他们都继承了 middleware
pass
from django.utils.deprecation import MiddlewareMixin # 模块的导入
# 写自己的类继承 Middleware
class MyMdd1(MiddlewareMixin):
def process_request(self, request):
print('xxx')
return HttpResponse('我是xxx的response') # 该方法一旦返回了httpresponse对象 那么请求会立刻停止往后走原路立刻返回
process_response 响应走的时候触发 参数 request response 且必须要返回response 他就是后端返回给前端的数据~
class MyMdd1(MiddlewareMixin):
def process_response(self, request, response):
print('test')
return response # 必须放回response 不返回直接报错!
# 请求来的时候是从上往下
# 响应走的时候是从下往上
需要了解:
process_views 参数: request view_name *args **kwargs 路由匹配成功之后 执行视图函数之前
def process_views(self, request, view_name, *args, **kwargs):
return HttpResponse('xx') # 如果返回 HttpResponse 会从头执行process_response
process_template_response 参数: request response 当你返回的对象中含有render属性的时候会自动触发
def process_template_response(self, request, response) # 如果形参中有response 就必须返回response
print('xxx')
return response
# 需要触发需要写个函数
def index(requset):
def render():
reutrn HttpResponse('xxx')
obj = HttpResponse('xxxx')
obj.render = render
return obj
process_exception 参数 : request exception 当视图函数有异常时会自动触发 顺序是 从下往上
def process_exception(self, requset, exception):
print(exception)