

其他模式补充 r+ w+ a+ 文件内光标移动 在rt模式下read内n表示的读取字符的个数 其他情况及其他方法内n表示都是字节数 f.read(n) f.seek(offset,whence) offset:指定光标的偏移量 whence:模式 0:相对于文件开头 t和b下都可以正常使用 1:相对于光标所在的当前位置 只能在b模式下使用 2:相对于文件末尾 只能在b模式下使用 牢记:中文在utf-8中用3个bytes表示,英文用一个bytes 检测文件是否被修改 打开文件 利用f.seek(0,2)将光标移动到文件末尾 利用while循环 再利用readline()来读取末尾内容 在通过if判断看readline()是否有值,有值说明文件新增了内容 通过字符串的格式化输出将新增的文件内容输出给检测程序 查看当前光标移动了多少字节 f.tell() 截断文件内容 f.truncate() 括号内输入的数字 表示的是字节数 将内存中的文件内容直接刷到硬盘 f.flush() 硬盘删除的数据原理 文件修改 两种方式 第一种将文件内容先读取到内存在内存中完成修改,然后重新覆盖原文件 优点:硬盘上始终只有一个文件 缺点:内存很有可能会溢出 当文件内容过大的情况下 第二种重新创建一个新的文件,将老文件的内容一行行读入内存完成修改 直接写到新的文件中,利用os模块将原文件删除,将新文件的名字改为来文件的名字 优点:内存中始终只有文件的一行内容 不占用内存 缺点:硬盘上在某一时刻会出现两个文件
函数:
什么是函数?函数就是具有某个具体功能的工具。
为什么要用函数?提供开发效率,减少代码冗余,提高程序的扩展性。
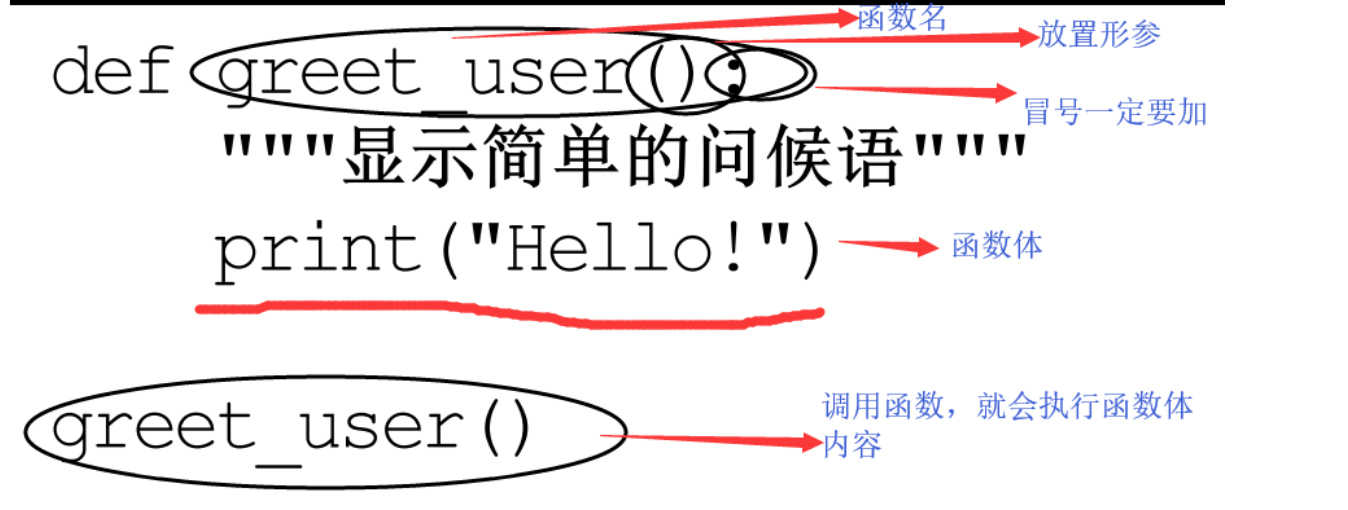
定义一个函数
def是定义函数的关键字
函数名:函数名的命名规则与变量名一致
1.不能以关键字
2.函数也应该做到见名知意
函数在定义的时候只检测函数体语法 不执行函数体代码
调用函数的固定格式
函数名+括号
函数名只要遇到括号会立即执行函数体代码
代码中遇到函数名加括号 优先级最高
先去执行函数 再看下面的代码
def func(): print('hello')
func() 调用函数
函数有么用呢 就像刚才说的那样,提供开发效率,减少代码冗余,提高程序的扩展性 就好比说你要获取一个列表的长度,可以使用len()方法是吧 但是现在要求不要用len()方法来实现这个功能可以不?可以 就像下面一样
补充:len()也是函数 它是一个内置函数 内置函数:python提前给你的写好了的函数 你直接调用即可
l=[1,2,3,4,5,6] count=0 for i in l: count+=1 print(count)
那我要是有100个列表呢 要敲100个for 循环? 这就需要用到我们的函数了
def my_len(): # 自定义函数 n = 0 for i in s: n += 1 print(n) my_len()
但是假如把my_len()绑定一个变量 res 且打印一下会发生什么?
res = my_len() print(res) >>>None
返回给我们了一个None 我们的值没给我 所以我们的写的这个函数还有点问题 没有返回值 想打印其他的列表还要重复的写 和 for循环没啥区别 !这就要学两个东西 return(返回值) 函数的参数
返回值return:函数内要想返回给调用者值 必须用关键字return
不写return:函数默认返回None
只写return: return除了可以返回值之外 还可以直接结束整个函数的运行 只写return 返回的也是None(None就表示什么都没有)
写return None:跟上面的只写return是一样的
写return返回一个值:这个值可以是python任意数据类型 写什么 返回什么
写return返回多个值:return会自动将多个值以元组的形式返回给调用者 自己手动加上你想返回的数据类型符号
# 写return 多个值 def func(): return 1,2,3,4 # 返回的是(1, 2, 3, 4) def func3(): return {'name':'jason'},{'username':'tank'},{'user_name':'egon'} # ({'name': 'jason'}, {'username': 'tank'}, {'user_name': 'egon'})
为啥呢?因为函数不希望自己处理的结果被修改
如何不返回元祖? 自己手动加上你想返回的数据类型符号
def func4(): return [[1,2,3,4],[1,2,3,4],[1,2,34]] res = func4() print(res)
返回值总结
1.所有的函数都有返回值,无论你写不写return python中所有的函数都有返回值 不写的情况下默认返回None
2.光写return 或者return None并不是为了考虑返回值 而是为了结束函数的运行
函数的参数:位置参数 默认参数 可变长参数
什么是形参?顾名思义,形参就是形式上的参数,可以理解为数学的X,没有实际的值,通过别人赋值后才有意义。相当于变量。
什么是实参?顾名思义,实参就是实际意义上的参数,是一个实际存在的参数,可以是字符串或是数字等
位置实参:
def my_max(x,y): print(x,y) if x > y: return x else: return y res = my_max(1) # 在调用函数的时候 少一个实参不行 报错 res = my_max(1,2,3) # 在调用函数的时候 多一个实参也不行 报错 res = my_max(20,10)
第一种直接按照位置传 一一对应
第二种指名道姓的传 >>>:关键字传参
my_max(y=20,x=10)
my_max(10,y=20) 位置和关键字混合使用
注意:在函数的调用阶段 位置参数和关键字参数可以混合使用
但是必须保证
1.位置参数必须在关键字参数的前面(越短的越靠前,越长的越复杂的越靠后)
2.同一个形参不能被多次赋值
默认参数:
在函数的定义阶段,形参(变量名)就已经被赋值了
在调用的时候可以不为默认值形参传值,默认使用定义阶段就已经绑定的值
在调用的时候如果可以给默认值形参传值 传了那么就使用你传的值
在定义阶段 默认值形参必须放在位置形参的后面
默认值参数的应用场景 当形参接收的到值比较单一的情况下 通常可以考虑用默认值形参
def register(username,age,gender='male'): 例如这里的gender 默认就是男性 print(username,age,gender) register('jason',18) register('tank',28) register('egon',84) register('kevin',58) register('xiaohou',17,'female') 只有一个女性所以 所以第三个参数就需要写
def info(username,hobby,l=[]): l.append(hobby) print('%s 的爱好是 %s'%(username,l)) info('jason','study') info('tank','生蚝') info('kevin','喝腰子汤') info('egon','女教练') 方法1 def info(username,hobby,l=[]): l.append(hobby) print('%s 的爱好是 %s'%(username,l)) info('jason','study',[]) info('tank','生蚝',[]) info('kevin','喝腰子汤',[]) info('egon','女教练',[]) 方法2 def info(username,hobby,l=None): if l == None: l = [] l.append(hobby) print('%s 的爱好是 %s'%(username,l)) info('jason','study') info('tank','生蚝') info('kevin','喝腰子汤') info('egon','女教练')
可变长参数(* 和 **)
站在调用函数传递实参的角度 实参的个数不固定的情况也就意味形参也不固定站在形参的角度 可以用*和**来接收多余的(溢出的)位置参数和关键字参数
站在形参的角度 看 *
形参中的*会将多余的(溢出的)位置实参 统一用元组的形式处理 传递给*后面的形参名
def func(x,y,*z): print(x,y,z) func(1,2,3,4,5,6,7,8,54,43,4,5,6,6,7,8,) z = (3, 4, 5, 6, 7, 8, 54, 43, 4, 5, 6, 6, 7, 8)
站在实参的角度 看 *
def func(x,y,z): print(x,y,z) l = [1,2,3] a,b,c = l func(a,b,c) func(*[1,2,3]) # *会将列表打散成位置实参一一传入等价于func(1,2,3,4,5,6) def func(x,*z): print(x,z) func(1,*{1,2,3}) # *在形参中只能接收多余的位置实参 不能接收关键字实参 # *只能将列表 元组 集合 字符串 # *的内部你可以看成是for循环
站在形参的角度 看 **
**会接收所有多余的关键字参数 并将关键字参数 转换成字典的形式
字典的key就是关键字的名字字典的value就是关键字的名字指向的值 将字典交给**后面的变量名
def func(x,y,**z): print(x,y,z) # z = {'z': 1, 'a': 1, 'b': 2, 'c': 3} func(x=1,y=2,z=1,a=1,b=2,c=3) >>>:1 2 {'z': 1, 'a': 1, 'b': 2, 'c': 3}
站在实参的角度 看 **
def func(x,y,z): print(x,y,z) func(x=1,y=2,z=3) d = {'x':1,'y':2,'z':333} func(x=1,y=2,z=3) func(**d) # 等价于func(x=1,y=2,z=333) # **会将字典拆封成 key = value的形式
总结 * 与 **
*在形参中能够接受多余的位置参数 组织成一个元祖赋值给*后面的变量名
**在形参中能够接受多余的关键字参数 组织成一个字典赋值给**后面的变量名
*:在实参中 *能够将列表 元祖 集合 字符串 打散成位置实参的形式传递给函数
(*就看成是for循环取值)
**:在实参中 能将字典打散成key = value的形式 按照关键字参数传递给函数
注意python推荐形参*和**通用的写法
def func2(*args,**kwargs): print(args,kwargs) func2(1,2,3,4,5,6,x=1,y=2,z = 3)