1. 什么是 Elasticsearch
Elastic是一个实时的分布式搜索分析引擎, 它能让你以一个之前从未有过的速度和规模,去探索你的数据。 它被用作全文检索、结构化搜索、分析以及这三个功能的组合。
2. 安装
- Elasticsearch 需要 Java 8 环境
2.1. Windows上运行ElasticSearch
下载安装包 elasticsearch-6.2.4.zip https://www.elastic.co/downloads/elasticsearch
解压压缩包,其目录结构如下:

从命令窗口运行位于bin文件夹中的elasticsearch.bat,可以使用CTRL + C停止或关闭它

见到xxxx started,那么就是启动完成了,打开浏览器输入http:\localhost:9200或http:\127.0.0.1:9200,如果出现以下文本证明启动成功了。
{ "name" : "ubH8NDf", "cluster_name" : "elasticsearch", "cluster_uuid" : "sJfrIwlVRBmAArbWRLWyEA", "version" : { "number" : "6.2.4", "build_hash" : "ccec39f", "build_date" : "2018-04-12T20:37:28.497551Z", "build_snapshot" : false, "lucene_version" : "7.2.1", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }
默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elastic。
network.host: 0.0.0.0
上面代码中,设成0.0.0.0让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
2.2. 集群搭建
- 准备好三个文件夹

- 修改配置文件:进入到其中某个节点文件中config文件夹中,打开elasticsearch.yml进行配置
- 具体的配置信息参考如下:
 View Code
View Code节点1的配置信息: http.cors.enabled: true #是否允许跨域 http.cors.allow-origin: "*" cluster.name: my-esLearn #集群名称,保证唯一 node.name: node-1 #节点名称,必须不一样 network.host: 10.118.16.83 #必须为本机的ip地址 http.port: 9200 #服务端口号,在同一机器下必须不一样 transport.tcpport: 9300 #集群间通信端口号,在同一机器下必须不一样 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["10.118.16.83:9300", "10.118.16.83:9301", "10.118.16.83:9302"] 节点2的配置信息: http.cors.enabled: true #是否允许跨域 http.cors.allow-origin: "*" cluster.name: my-esLearn #集群名称,保证唯一 node.name: node-2 #节点名称,必须不一样 network.host: 10.118.16.83 #必须为本机的ip地址 http.port: 9201 #服务端口号,在同一机器下必须不一样 transport.tcpport: 9301 #集群间通信端口号,在同一机器下必须不一样 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["10.118.16.83:9300", "10.118.16.83:9301", "10.118.16.83:9302"] 节点3的配置信息: http.cors.enabled: true #是否允许跨域 http.cors.allow-origin: "*" cluster.name: my-esLearn #集群名称,保证唯一 node.name: node-3 #节点名称,必须不一样 network.host: 10.118.16.83 #必须为本机的ip地址 http.port: 9202 #服务端口号,在同一机器下必须不一样 transport.tcpport: 9302 #集群间通信端口号,在同一机器下必须不一样 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["10.118.16.83:9300", "10.118.16.83:9301", "10.118.16.83:9302"] `

2.3. elasticsearch-head的搭建
解压已经下载 elasticsearch-head-master.zip,同时确认本机已经安装好nodejs,cmd->node -v确认nodejs是否安全成功。
解压压缩包,切换到elasticsearch-head-master已解压好的文件夹下。
c:elasticsearch-head-master>npm install c:elasticsearch-head-master>npm start
用浏览器打开,http://10.118.16.83:9100/, 只要出现下图界面就证明成功了。

3. 基本概念
-
集群(Cluster)
ES集群是一个或多个节点的集合,它们共同存储了整个数据集,并提供了联合索引以及可跨所有节点的搜索能力。多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。集群靠其独有的名称进行标识,默认名称为“elasticsearch”。节点靠其集群名称来决定加入哪个ES集群,一个节点只能属一个集群。
-
节点(node)
一个节点是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能, 一个节点也有唯一的名字,群集通过节点名称进行管理和通信.
-
主节点
主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
-
数据节点
持有数据和倒排索引。
-
客户端节点
它既不能保持数据也不能成为主节点,该节点可以响应用户的情况,把相关操作发送到其他节点;客户端节点会将客户端请求路由到集群中合适的分片上。对于读请求来说,协调节点每次会选择不同的分片处理请求,以实现负载均衡。
-
索引Index
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index
$ curl -X GET 'http://10.118.16.83:9200/_cat/indices?v'
-
文档类型(Type)
索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”
-
文档Document
Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。相当于数据库的“记录”,例如:
{ "user": "张三", "title": "工程师", "desc": "数据库管理" }
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
-
Mapping
相当于数据库中的schema,用来约束字段的类型,不过 Elastic的 mapping 可以自动根据数据创建
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。
分片(shard) :ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个
4. 数据操作
4.1. 文档更新
4.1.1. 新增
向指定的 /Index/Type 发送 PUT 请求,就可以在 Index 里面新增一条记录。
$ curl -H "Content-Type:application/json" -X PUT '10.118.16.83:9200/megacorp/employee/1' -d '
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'
返回:
{ "_index": "megacorp", "_type": "employee", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
若不指定id, 则改为Post请求 。id字段就是一个随机字符串。
再新增两条:
$ curl -H "Content-Type:application/json" -X PUT '10.118.16.83:9200/megacorp/employee/2' -d ' { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] }' $ curl -H "Content-Type:application/json" -X PUT '10.118.16.83:9200/megacorp/employee/3' -d ' { "first_name" : "Douglas", "last_name" : "Fir", "age" : 35, "about": "I like to build cabinets", "interests": [ "forestry" ] }'
4.1.2. 更新
更新记录就是使用 PUT 请求,重新发送一次数据。
$ curl -H "Content-Type:application/json" -X PUT '10.118.16.83:9200/megacorp/employee/1' -d '
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 26,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'
返回:{ "_index": "megacorp", "_type": "employee", "_id": "3", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 }
记录的 Id 没变,但是版本(version)从1变成2,操作类型(result)从created变成updated,created字段变成false,因为这次不是新建记录
4.1.3. 检索文档
$ curl '10.118.16.83:9200/megacorp/employee/1'
删除
删除记录就是发出 DELETE 请求
$ curl -X DELETE '10.118.16.83:9200/megacorp/employee/1'
4.2. 返回所有记录
使用 GET 方法,直接请求/Index/Type/_search,就会返回所有记录。
- http://10.118.16.83:9200/_search - 搜索所有索引和所有类型。
- http://10.118.16.83:9200/megacorp/_search - 在megacorp索引中搜索所有类型
- http://10.118.16.83:9200/megacorp/employee/_search - 在megacorp索引中显式搜索employee类型的文档。
$ curl '10.118.16.83:9200/accounts/person/_search' { "took": 4, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1, "hits": [ { "_index": "megacorp", "_type": "employee", "_id": "2", "_score": 1, "_source": { "first_name": "John", "last_name": "Smith", "age": 25, "about": "I love to go rock climbing", "interests": [ "sports", "music" ] } }, …//此处省略 ] } }
上面代码中,返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录,里面子字段的含义如下。
total:返回记录数,本例是3条。
max_score:最高的匹配程度,本例是1.0。
hits:返回的记录组成的数组。
返回的记录中,每条记录都有一个_score字段,表示匹配的程序,默认是按照这个字段降序排列。
4.3. 匹配查询
Elastic提供两种方式:
l Query-string 搜索通过命令非常方便地进行临时性的即席搜索 ,但它有自身的局限性。
$ curl '10.118.16.83:9200/megacorp/employee/_search?q=last_name:Smith'l 提供一个丰富灵活的查询语言叫做 查询表达式 , 它支持构建更加复杂和健壮的查询。领域特定语言 (DSL), 指定了使用一个 JSON 请求
$ curl -H "Content-Type:application/json" '10.118.16.83:9200/megacorp/employee/_search' -d '
{
"query" : { "match" : { "last_name" : " Smith" }}
}'
4.4. 过滤查询
同样搜索姓氏为 Smith 的雇员,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter [range ],它支持高效地执行一个结构化查询。
$ curl -H "Content-Type:application/json" '10.118.16.83:9200/megacorp/employee/_search' -d '
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}'
4.5. 全文搜索
截止目前的搜索相对都很简单:单个姓名,通过年龄过滤。现在尝试下稍微高级点儿的全文搜索——一项 传统数据库确实很难搞定的任务。搜索下所有喜欢攀岩(rock climbing)的雇员。
$ curl -H "Content-Type:application/json" '10.118.16.83:9200/megacorp/employee/_search' -d '
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}'
得到两个匹配的文档
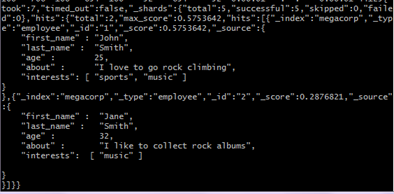
这是一个很好的案例,阐明了 Elasticsearch 如何 在 全文属性上搜索并返回相关性最强的结果。Elasticsearch中的 相关性 概念非常重要,也是完全区别于传统关系型数据库的一个概念,数据库中的一条记录要么匹配要么不匹配。
4.6. 短语搜索
找出一个属性中的独立单词是没有问题的,但有时候想要精确匹配一系列单词或者短语 。 比如, 我们想执行这样一个查询,仅匹配同时包含 “rock” 和 “climbing” ,并且 二者以短语 “rock climbing” 的形式紧挨着的雇员记录。
为此对 match 查询稍作调整,使用一个叫做 match_phrase 的查询:
$ curl -H "Content-Type:application/json" '10.118.16.83:9200/megacorp/employee/_search' -d '
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}'
4.7. 高亮搜索
许多应用都倾向于在每个搜索结果中 高亮 部分文本片段,以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。
再次执行前面的查询,并增加一个新的 highlight 参数:
$ curl -H "Content-Type:application/json" '10.118.16.83:9200/megacorp/employee/_search' -d '
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}'
查询结果:
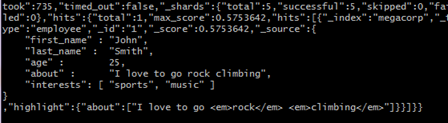
4.8. 聚合
Elasticsearch 有一个功能叫聚合(aggregations),允许我们基于数据生成一些精细的分析结果。聚合与 SQL 中的 GROUP BY 类似但更强大。
举个例子,挖掘出雇员中最受欢迎的兴趣爱好:
$ curl -H "Content-Type:application/json" '10.118.16.83:9200/megacorp/employee/_search' -d ' { "aggs": { "all_interests": { "terms": { "field": "interests" }, "aggs": { //为指标新增aggs层 "avg_age": { //指定指标的名字,在返回的结果中也是用这个变量名来储存数值的 "avg": {//指标参数:平均值 "field": "age" //明确求平均值的字段为'age' } } } } } }'
执行失败:
{ "error": { "root_cause": [ { "type": "illegal_argument_exception", "reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [interests] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory." } ], "type": "search_phase_execution_exception", "reason": "all shards failed", "phase": "query", "grouped": true, "failed_shards": [ { "shard": 0, "index": "megacorp", "node": "-Md3f007Q3G6HtdnkXoRiA", "reason": { "type": "illegal_argument_exception", "reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [interests] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory." } } ], "caused_by": { "type": "illegal_argument_exception", "reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [interests] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory." } }, "status": 400 }
排序,聚合这些操作用单独的数据结构(fielddata)缓存到内存里了,需要单独开启,官方解释在此fielddata
$ curl -H "Content-Type:application/json" -X POST '10.118.16.83:9200/megacorp/_mapping/employee' -d '
{
"properties":{
"interests":{
"type":"text",
"fielddata":true
}
}
}'
切记,这里一旦类型错误,以后可就麻烦咯
查询结果:
{"took":40,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":4,"max_score":1.0,"hits":[{"_index":"megacorp","_type":"employee","_id":"_cat","_score":1.0,"_source":{
"properties":{
"age":{
"type":"integer",
"fielddata":true
}
}
}
},{"_index":"megacorp","_type":"employee","_id":"2","_score":1.0,"_source":{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
},{"_index":"megacorp","_type":"employee","_id":"1","_score":1.0,"_source":{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
},{"_index":"megacorp","_type":"employee","_id":"3","_score":1.0,"_source":{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
}]},"aggregations":{"all_interests":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"music","doc_count":2,"avg_age":{"value":28.5}},{"key":"forestry","doc_count":1,"avg_age":{"value":35.0}},{"key":"sports","doc_count":1,"avg_age":{"value":25.0}}]}}}
Java实现
@Test public void aggsTermsQuery() { SearchResponse response = client.prepareSearch("cars") .setTypes("transactions") .addAggregation(AggregationBuilders.terms("all_interests").field("interests") .subAggregation(AggregationBuilders.avg("avg_price") .field("price"))) .setSize(0) .get(); Map<String, Aggregation> aggMap = response.getAggregations().asMap(); StringTerms teamAgg= (StringTerms) aggMap.get("popular_colors"); Iterator<Bucket> teamBucketIt = teamAgg.getBuckets().iterator(); while (teamBucketIt .hasNext()) { Bucket buck = teamBucketIt .next(); //max/min以此类推 logger.info(buck.getKeyAsString() + ", " + buck.getDocCount()); Map<String, Aggregation> subAggMap = buck.getAggregations().asMap(); long avgAgg= (long) ((InternalAvg)subAggMap.get("avg_price")).getValue(); logger.info("avg:{}", avgAgg); } }
4.9. 排序与分页
Elastic使用sort进行排序,默认一次返回10条结果,可以通过size字段改变这个设置。还可以通过from字段,指定位移。
GET /_search { "query" : { "bool" : { "filter" : { "term" : { "user_id" : 1 }} } }, "sort": { "date": { "order": "desc" }}, "from": 1, "size": 1 }
5. 中文分词设置
5.1. 安装分词插件
注意:安装对应版本的插件。
下载插件https://github.com/medcl/elasticsearch-analysis-ik/releases
5.2. 使用 IK Analysis
要使用 IK Analysis,需要在文档类里面,指定相应的分词器。
ik_max_word 和 ik_smart 区别
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
具体使用可参考https://github.com/medcl/elasticsearch-analysis-ik
public void highlighter() throws UnknownHostException { String preTags = "<strong>"; String postTags = "</strong>"; HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.preTags(preTags);//设置前缀 highlightBuilder.postTags(postTags);//设置后缀 highlightBuilder.field("content"); SearchResponse response = client.prepareSearch("msg") .setTypes("tweet") .setSearchType(SearchType.DFS_QUERY_THEN_FETCH) .setQuery(QueryBuilders.matchQuery("content", "中国")) .highlighter(highlightBuilder) .setFrom(0).setSize(60).setExplain(true) .get(); logger.info("search response is:total=[{}]",response.getHits().getTotalHits()); SearchHits hits = response.getHits(); for (SearchHit hit : hits) { logger.info("{} -- {} -- {}", hit.getId(), hit.getSourceAsString(), hit.getHighlightFields()); } SearchRequestBuilder builder = client.prepareSearch("msg") .setTypes("tweet") .setSearchType(SearchType.DFS_QUERY_THEN_FETCH) .setQuery(QueryBuilders.matchQuery("content", "中国")); }
6. 通过Java程序连接Elasticsearch
需要注意的是,我们通过浏览器 http://10.118.16.83:9200 访问可以正常访问,这里需要知晓,9200端口是用于Http协议访问的,如果通过客户端访问需要通过9300端口才可以访问
pom.xml添加依赖
<!-- Elasticsearch核心依赖包 --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>6.2.4</version> </dependency> <!-- 日志依赖 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.21</version> <scope>test</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency>
6.1. 单点
import java.net.InetAddress; import java.net.UnknownHostException; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.TransportAddress; import org.elasticsearch.transport.client.PreBuiltTransportClient; import org.junit.Test; public class ElasticsearchTest1 { public static final String HOST = "127.0.0.1"; public static final int PORT = 9200; //http请求的端口是9200,客户端是9300 @SuppressWarnings("resource") @Test public void test1() throws UnknownHostException { TransportClient client = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress( new TransportAddress(InetAddress.getByName(HOST), PORT)); System.out.println("Elasticssearch connect info:" + client.toString()); client.close(); } }
6.2. 集群
import java.io.IOException; import java.net.InetAddress; import java.net.UnknownHostException; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.action.search.SearchType; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.TransportAddress; import org.elasticsearch.common.xcontent.XContentFactory; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.transport.client.PreBuiltTransportClient; import org.junit.After; import org.junit.Before; import org.junit.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class ElasticsearchTest2 { public static final String HOST = "10.118.16.83"; public static final int PORT = 9300; //http请求的端口是9200,客户端是9300 private TransportClient client = null; private Logger logger = LoggerFactory.getLogger(ElasticsearchTest2.class); public static final String CLUSTER_NAME = "my-esLearn"; //实例名称 //1.设置集群名称:默认是elasticsearch,并设置client.transport.sniff为true,使客户端嗅探整个集群状态,把集群中的其他机器IP加入到客户端中 private static Settings settings = Settings.builder() .put("cluster.name",CLUSTER_NAME) .put("client.transport.sniff", true) .build(); /** * 获取客户端连接信息 * @Title: getConnect * @author ld * @date 2018-05-03 * @return void * @throws UnknownHostException */ @SuppressWarnings("resource") @Before public void getConnect() throws UnknownHostException { client = new PreBuiltTransportClient(settings).addTransportAddress( new TransportAddress(InetAddress.getByName(HOST), PORT)); logger.info("连接信息:" + client.toString()); } @After public void closeConnect() { if (client != null) { client.close(); } } @Test public void test1() throws UnknownHostException { logger.info("Elasticssearch connect info:" + client.toString()); } @Test public void addIndex() throws IOException { IndexResponse response = client.prepareIndex("msg", "tweet", "2").setSource( XContentFactory.jsonBuilder() .startObject() .field("userName", "es") .field("msg", "Hello,Elasticsearch") .field("age", 14) .endObject()).get(); } @Test public void search() { SearchResponse response = client.prepareSearch("msg") .setTypes("tweet") .setSearchType(SearchType.DFS_QUERY_THEN_FETCH) .setQuery(QueryBuilders.matchPhraseQuery("user_name", "es")) .setFrom(0).setSize(60).setExplain(true) .get(); logger.info("search response is:total=[{}]",response.getHits().getTotalHits()); SearchHits hits = response.getHits(); for (SearchHit hit : hits) { logger.info(hit.getId()); logger.info(hit.getSourceAsString()); } } }
7. mysql与elasticsearch同步
可参考elasticsearch与数据库同步工具Logstash-input-jdbc
8. 与solr的比较
|
solr |
Elastic |
|
|
功能 |
官方提供的功能更多 |
官方功能少,但是第三方插件很丰富,扩展能力更强 |
|
建立索引和查询效率 |
建立索引的速度和Es差不多,索引建立完成后的检索速度也很快,但是一边建立索引一边搜索会很慢(建立索引时会造成IO阻塞) |
建立索引速度和solr差不多,第一次检索会比solr慢,之后就快了。一边建立索引一边搜索的速度不影响( 索引会先存在内存中,内存不足再写入磁盘,还有队列空闲时把索引写入硬盘) |
|
支持的数据格式 |
Xml等多种格式 |
json |
|
分布式管理 |
zookeeper |
自己维护 |
|
Sharding |
没有自动shard rebalancing的功能 |
Shard必须一次设置好,之后不能修改,如果要修改则需要重新建立索引 |
|
高级查询 |
没有Query DSL |
有Query DSL,能够支持更加高级和复杂的查询语法,而且还可以以此扩展实现类sql语法的查询 |
|
搜索 |
传统搜索应用 |
实时搜索应用(1s的延迟) |
|
插件 |
不支持插件式开发 |
支持插件式开发,丰富的插件库 |