今天开始,研读下jdk的常用类的一些源码,下面是jdk中HashMap的研究。诚然,网上已经很多这方面的总结了,但是,个人只是想单纯地把自己的理解过程进行记录,大牛们就绕路吧,当然,欢迎扔砖头。下面是大体的内容如下:
一、哈希的概述
1、哈希的概念
2、哈希要解决的问题
二、java中哈希的实现过程
1、java中实现哈希的关键步骤
2、关于resize过程的分析
三、java中HashMap在并发时存在链表死循环问题。
一、哈希的概述
1、数组和哈希
在说哈希这个数据结构前,先用数组这个耳闻能详的数据结构进行引出:我们知道,访问数组的常用方法是通过数组游标进行访问,我只要持有数组某个元素对应的游标,我就能在O(1)时间内获取该元素。数组的这个性质让它在查询的时候速度非常快,而究其原因,其实是因为数组中元素位置和游标时一一对应的,确定游标即确定元素。这里的游标,就是哈希结构中的key,元素就是value。
2、哈希是什么
上面说到了哈希的key以及value,那到底他们是什么?可以这样理解哈希结构:key就是数组的游标,value就是我们要存储的元素,哈希结构可以理解为数组结构的一种扩展,而数组则是特殊的哈希结构,在哈希结构中,我们通过key可以在O(1)时间内定位value。而哈希结构与数组的区别在于:哈希结构中,key不仅仅是数字,它更可以是对象;哈希结构中元素个数不像数组一样不变,而是可以动态变化的。
3、如何实现哈希
所以,其实实现哈希主要是要解决这些问题:首先,我要把对象进行值映射,这样解决了key可以是不同对象的问题;然后,把映射值进行压缩,这样保证对象映射的值集中在某个有限的区间内,内存上才能有效利用这些值进行映射表的建立;最后,我们需要在适当的时候扩展映射表的结构,这样可以解决元素个数动态的问题。
然后,下面我们就研读下java中的HashMap是如何解决上面提到的这些问题的
二、java 中的HashMap实现原理
1、映射的解决方法
在java中,最顶层的类Object 有一个方法:hashCode,下面是api截图的说明:

hashCode方法,就是把普通java 对象映射为一个哈希吗的方法,其实在算法底层来说,哈希码是通过对象以及内存地址、对象创建当前时间等等数值来进行运算得出的一个数字,基本上,某段时间内的某个对象,哈希码是独一无二的。
当然,上面的API说到,一个对象,如果通过equals 比较的结果是相等的话,应该保证hashCode也是相等的,这就要求我们如果重写equals 方法必须重写hashCode方法。java API中这样要求的原因其实是和哈希结构在插入数据时如何确定要插入的key是否存在有关,具体后面说到map的put方法时再展开。
2、hashCode的压缩问题
显然,hashCode的范围是很大的,不同对象组对应的hashCode对应的范围可能会很大,例如对象一的hashCode是3,然后对象2的hashCode是30000,如果我们直接用一个30000 + 1(假设游标从0开始)大的数组来映射对应的元素(hashCode为3的放到数组对应游标为3的地方,为30000的放到游标对应为30000位置处),这样,显然中间很多位置是没有元素的,这样那部分空间就拜拜浪费了。所以,我们需要一种算法,把各个对象的hashCode压缩在一个一定的范围内,然后,把hashCode压缩之后的数字作为数组的游标,对应着原来的对象,这样就解决了空间浪费的问题,同时又以数组来实现了哈希的结构。
在java 中,其实它压缩算法是下面这段代码:
static int indexFor(int h, int length) { return h & (length-1); }
至于为什么h & (length-1) 这个算法可以有效保证把元素压缩在一个范围内而且可以很大程度地避免发生哈希碰撞,更具体的原因,可以参开这篇博客:http://blog.csdn.net/qq_27093465/article/details/52207152,这里不累赘展开。
3、哈希冲突问题
上面提到了一个概念叫做哈希冲突问题:当我们在进行数据压缩的时候,理想的哈希压缩算法当然是,n个元素的hashCode刚好都压缩在0-n-1的范围,这样就能最大程度地保证数组中的空间都被用到了,然而,对象之间的hashCode是毫无规律的,这种压缩算法是不存在的。就是说,所有不同哈希码并不能保证压缩之后的映射压缩值都不相等,并没有找到一种算法可以吧值都压缩在一个恰当的范围而且恰好都不相等,压缩数据的范围越小,冲突的几率越大,反之,几率越小,这种由于压缩hashCode之后造成的对应值相等的情况就是哈希冲突问题。
哈希冲突问题解决方案挺多,但是最常用的一种叫做拉链法,也是java 中的哈希结构所用的方法,它是一种链表数组的结构,看下面示意图:
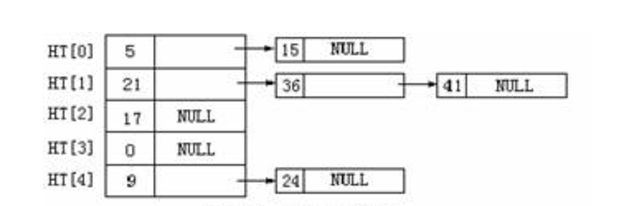
上面就是利用一个数组长度为5的链表数组来表示hashCode压缩之后值分别为15,36,41,24这个四个值。显然,这种结构中,查找元素速度肯定是没有数组元素中利用游标进行元素查找那么快的,但是,只要对应的压缩算法能够较好地分散元素,哈希冲突不严重时,查找某个元素还是可以保持为O(1)的复杂度的,同时,也能保证空间较大的利用率。
三、java中put方法的具体执行过程
有了上面这么多的铺垫,下面再对java的哈希结构中添加元素的过程进行简单的总结。在java的HashMap中,执行添加算法大体要经历以下步骤:首先进行对象与哈希值的映射,然后进行哈希码的压缩操作,再根据压缩得到的结果,找到链表数组的对应链表,看该位置是否存在了元素(不为null),如果该游标元素还没有聊表元素,直接插入;否则,遍历该结果值对应的游标的链表元素,进行链表的遍历,利用eauql方法判断元素是否存在,如果存在,则覆盖旧值;否则,直接添加。 当然,在添加新元素前,需要进行元素个数的判断,当元素个数超过负载因子*数组长度时,就要进行resize操作了。
下面,对这个过程的更多细节的地方,我们进行一一展开。
1、put方法的源码分析。先看看put这个方法是如何执行的:
public V put(K key, V value) { //如果key是null,直接调用特殊的putForNullKey方法进行元素添加 if (key == null) return putForNullKey(value); //利用hash函数,计算哈希码 int hash = hash(key); //进行哈希码的压缩映射 int i = indexFor(hash, table.length); //遍历压缩之后的映射值对应的游标的链表元素,查看是否包含了新添加的key值。 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果存在 了key,直接替换旧value,并返回旧的value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; //否则,进行add元素的操作 addEntry(hash, key, value, i); return null; }
put操作的主要操作步骤在注释里面也说了,下面就详细针对put这个方法的addEntry方法进行详细的总结。
2、addEntry的过程。先看源码和对应的注释:
void addEntry(int hash, K key, V value, int bucketIndex) { //首先,判断当前map中元素的个数是否超过了threshold这个临界值,这个临界值的计算方式是:负载因子*链表数组长度 //如果超过了,则进行resize(扩容)操作,否则,直接执行createEntry操作(就是直接在链表末端插入新链表节点即可) if ((size >= threshold) && (null != table[bucketIndex])) { //执行扩容操作 resize(2 * table.length); //扩容操作执行之后,为什么要重新计算hash值?这个希望有大牛懂的话可以告知下 hash = (null != key) ? hash(key) : 0; //扩容之后,length发生了变化,所以bucketIndex需要重新计算 bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
这里的addEntry操作,主要就是先判断当前元素个数是否超过了一个临界值,这个临界值是链表数组*负载因子(默认是0.75),超过了的话就要执行扩容操作。不过本人有点不明白的地方是:为什么resize之后,要重新计算对象的hash值的?按道理,hashCode与扩容与否应该无直接关系吧?
3、resize方法的执行过程。那么resize又是怎么执行的呢?还是先看代码吧:
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; //先判断当前的数组容量是否超过了最大容量允许值,如果超过了,直接设置threshold位Integer.MAX_VALUE并不执行扩容操作 if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } //创建扩容新数组 Entry[] newTable = new Entry[newCapacity]; //下面这段代码其实我也查了好久资料,发现网上并没有相关的资料讲解, //就是oldAltHashing和useAltHashing两个值到底是干嘛的,有大佬知道非常希望可以告知下 boolean oldAltHashing = useAltHashing; useAltHashing |= sun.misc.VM.isBooted() && (newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD); boolean rehash = oldAltHashing ^ useAltHashing; //transfer把旧元素统一移动到新的链表数组上去 transfer(newTable, rehash); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
这段代码总体不难看懂,不过本人其实也有一点疑问:就是oldAltHashing 和useAltHashing 的含义是什么?这个希望有大牛懂的留言告知下,本人查了挺久也没得到相关的解释。
总体来说,resize过程就是创建一个双倍大的新链表数组,并重新计算已有所有元素的压缩哈希值,根据新的结果,重新调整哈希表。这个过程,其实是挺耗费性能的。而具体的transfer方法执行过程,还是看源码吧:
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; //遍历旧的链表数组 for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } //重新计算对应的数组链表值 int i = indexFor(e.hash, newCapacity); //把该节点插入到新数组的对应节点 e.next = newTable[i]; newTable[i] = e; e = next; } } }
上面的transfer 过程,主要就是理解e.next = newTable[i];newTable[i] = e;e=next这三个语句:首先是把旧的元素的下一个节点指向新的链表数组的对应元素(一开始为null),当然,旧元素的next元素需要一个next变量进行存储;当下一个新元素也插入同一个位置时,重复上面这个过程的效果是:在旧数组中在后面的元素,在新扩容后数组对应每个链表中,反而在前面了,相当于反转了。如果还不好理解,看下面的示意图:

三、关于HashMap中多线程下的安全问题
在了解了HashMap的机制之后,顺便提一个问题:HashMap是非线程安全的,这不仅仅是因为它无法保证数据的一致性,更会有可能形成聊表死循环,造成性能的极度浪费。出现这个问题的根本原因其实是:在transfer 中,执行了旧的链表节点指向新的数组元素时,其他线程刚好执行到next = e.next时,此时,这个线程的next就会存储了新的数组中对应的链表而不是旧的数组的原有链表了,当前线程继续往下执行时,便会出现 节点的next指向自身的情况,参考下面的图进行理解:
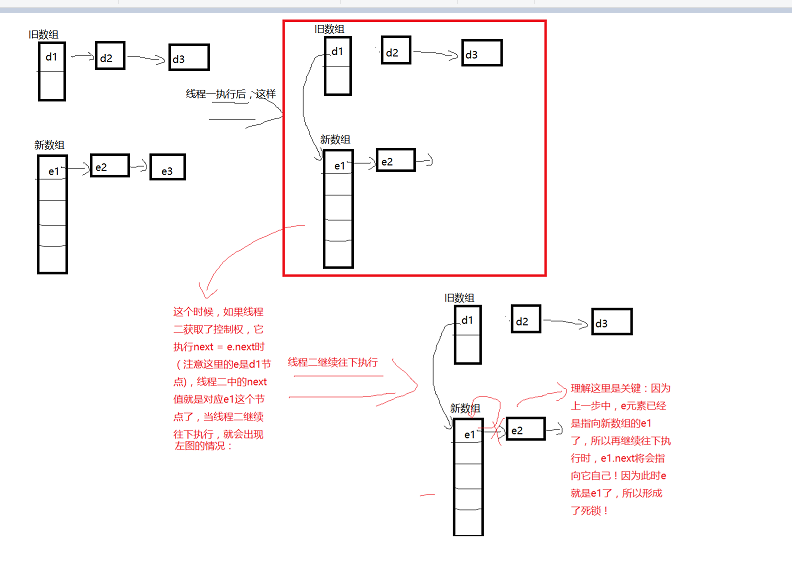
所以,HashMap是不能在多线程下使用的,它 不仅会发生数据不一致的问题,而且会造成死循环!