之前一直在实习,博客停写了一段时间,现在秋招开始了,所以辞职回来专心看书,同时将每天的收获以博客的形式记录下来。最近在看jvm相关的书籍,下面对面试中问得最多的部分--java 内存模型进行简单总结。
本篇博客大概由一下几个部分组成:
1、程序在真实物理世界的内存模型
2、java的内存模型
3、java中的volatile与线程安全
4、happen-before原则与加锁。
一、程序在物理世界中是怎样运行的
所有的程序,无论什么语言编写,最后都会变为一串机器码,而cpu的运算过程,就是将这些机器码转换为电信号给相应的运算电路进行逻辑或者算术运算,然后将结果返回。在这个过程,底层的电路如何进行运算并非讨论范畴,我们主要从更加宏观的角度理解程序怎么运行:程序从加载到内存到cpu得出结果返回到内存中,这个过程具体到底是如何进行的。
1、程序在物理中的执行过程
我们以前一直知道,cpu从内存中读取数据远远快于从磁盘或者网络流中读取数据,所以为了提高响应速度,我们很多时候会提前把读取频繁的数据预先加载到内存中以提高性能;其实类似的,由于cpu的运算速度真的太快了,从内存加载数据到cpu的时间和cpu运算速度相比也是太慢了,所以为了提高程序执行效率,在cpu和内存之间,还有一个缓存区,叫cpu高速缓存区,cpu从高速缓存中读取数据的速度远远快于从主存中读取数据(当然,高速缓存的物理制造成本也比主内存物理成本高得多)所以,为了提高速率,真实的程序是按照下面这张示意图的路径进行运行的:
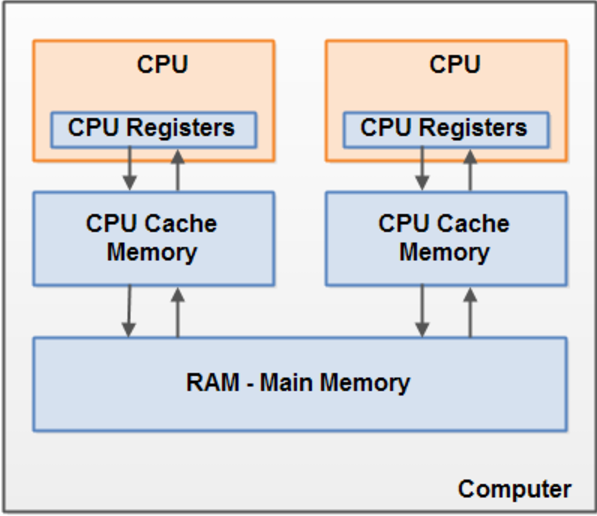
总的来说:程序加载到主存之后,当cpu运算需要读或写数据的时候,它不会直接对主存进行操作,因为这样速度实在太慢了,它从位于cpu和主存之间的高速缓存读取数据/写入数据,当运算完成时,高速缓存会将结果自动更新到主存中。
2、缓存带来的问题
和所有缓存机制面临的问题一样,cpu高速缓存也面临这样的问题:多线程下数据同步问题。现代的cpu,基本都是以多核cpu为主,所以,再多核(多线程)下,不同cpu之间的数据同步问题是高速缓存缓存需要解决的。真实物理世界中,在有必要的情况下,为了保证数据同步,可以通过对内存中的数据进行加锁操作来保证数据的一致性,这和我们平常理解的多线程加锁操作是一致的,不过本人对硬件层面如何实现加锁不太了解,当然也不是这次的重点,所以就不展开了。
二、java的内存模型
我们知道,java程序是运行在jvm上面的,jvm本身有它自己的一套内存模型,当然,很多时候,jvm的内存模型和真实的物理中程序运行的内存模型是一致的。
1、jvm的高速缓存
和真实的硬件内存模型类似,jvm内存模型中,每个线程都有自己独立的工作空间,可以类比为前面cpu的高速缓存区域,它也是位于jvm主存和cpu之间,所以,当我们在多线程的环境下对共享数据进行操作的时候,也会有真实的cpu内存模型面临的数据一致性的问题,当然,在讨论数据一致性问题之前,我们先讨论下再java内存模型中操作原子性的问题。
2、操作指令的原子性
程序指令的原子性就是说这个指令在cpu运算中是最小的不可分割的了,它要不就执行成功,要不就没执行。而数据的同步问题,就是在多个原子操作之间出现的,当多个线程下多个原子指令对共享数据进行操作时,便会面临数据同步的问题,所以解决同步问题之前我们要先知道在java内存模型中,哪些指令或者说操作是原子性的;
java的jvm中的原子指令主要有一下:lock(锁),unlock(解锁),read(读)和load(加载),use(使用),store(存储)和write(写), assign(赋值)。下面详细解释下各个指令;
lock 和unlock操作:对数据进行加锁/解锁操作,这组指令从直观上理解也是一致性的,因为不可能对数据lock/unlock到一半又失败了,这是不合理的;
read和load:这两个指令很容易混淆,我们可以这样理解:load操作,是从主内存中将数据加载到告诉缓存中,而read操作是数据从高速缓存中加载到cpu中。所以,我们可以看到,数据从主内存到cpu的这个过程,涉及到了两个原则性的动作。
use:user指令可以理解为数据被jvm进行某个运算;
strore/write:分别是read和load的反过程。
assign:赋值操作,将某个常量或者变量赋值给某个变量。
举个例子进行上面指令的理解:i=i+1,在这个程序段中,jvm首先进行load操作,将i的值加载到告诉缓存中,然后进行read操作,将i值加载到cpu的对应寄存器中,当变量read完毕之后,进行use操作,将i变量的值加1,加完1之后,执行assign操作将新的值赋值给i,然后,cpu执行store操作,将数据的运算结果写进高速缓存中,最后,cpu将i的新值刷新进内存中。注意,在这个过程中,如果是在多线程环境下的,所有的操作,都有可能中途被打断。
另外,我们要知道,什么时候会进行相应的指令操作,这对后面我们理解数据一致性和可见性有很大帮助。read/write动作只会发生在use动作或者assign动作之前/后,对于连续的use和assign操作,只有一开始的use和assign进行read操作(这也很合理,对于一个变量的多个运算连,在续进行时,当前的运算依赖上一步的运算结果而不是在高速缓存或者内存中的值,所以,对于同一个变量,不会每次执行use指令和assign指令都进行read操作);而同样的,进行store操作时,也不是没执行use或者assign指令一次就直接将当前结果写进高速缓存的,jvm仅仅将最终运算结果写到高速缓存。
上面这段话比较抽象,举个具体的例子:i=i+1,这个操作步骤是这样的:load i值--> read i值--> use i值-->assign i值--> store i值-->write i 值;在执行这段代码的时候,i的read操作只会执行一次,jvm不会再在use和assign之间执行read或者write操作,毕竟这样做的话jvm太累了。
3、数据同步问题与volatile关键字
在进行数据同步问题讨论之前,先看以下简单的代码:

public class Demo1 implements Runnable {
static volatile int i=0;
public static void main(String[] args) {
for(int j=0;j<10000;j++){
Runnable runnable = new Demo1();
new Thread(runnable).start();
}
Thread.yield();
System.out.println(Demo1.i);
}
public void run() {
i++;
}
}
读者可能以为上面的例子打印结果一定是9999,但是事实并不是,当然,将j的值设置更大一点效果会更明显。所以,在多线程环境下对变量进行操作,需要进行加锁操作,volatile并不保证变量的线程安全,至于为什么,后面会对这里例子出现的情况进行详细的说明。
很多人都以为volatile关键字的意思就是同步数据,在使用volatile关键字修饰变量之后变量会变得线程安全起来,但是,事实上volatile关键字并不是保证数据同步的,类似上面这种情况,只有通过加锁进行同步操作才能保证i值的正常增加,而volatile关键字的作用仅仅是保证变量在修改之后立即可见,这就引出了java内存模型中的另外一个问题:数据可见性问题。
4、java内存模型中的数据可见性问题
可能读者看到这里会有很强烈的疑问了:数据的一致性和指令原子性、可见性之间有什么关系?它和前面说的高速缓存又有什么关系?在阐述这些问题的时候,我们先要理解java中数据可见性是什么意思:在前面介绍java内存模型的时候,我们有提到java内存模型中的高速缓存区以及java原子操作的八个指令,数据可见性的意思可以理解为,在进行数据操作时,java程序的read和load以及store和write操作变为了一个原子动作,对于读数据,jvm不再用高速缓存上的缓存副本数据而是直接读取内存中最新的数据,对于写数据jvm将运算结果立即写入内存,而要实现这种操作,只需要将变量修饰为volatile变量即可。
所以,可见性是保证各个线程读取到的数据是其他线程最新修改的,那么,为什么可见性不能保证数据的一致性呢?
以上面的i++例子为例,i++实际上是i=i+1,在jvm运算中,这个代码段包含了两个操作:将i的值加1以及将新值赋值给i,这两个动作对应两个原子指令,多线程环境下,这两个指令并不一定是连续,有可能线程1进行了i+1操作之后还没进行赋值操作,线程2也进行了同样的操作并且成功将加1后的最新值写进了内存,但是,线程1中的i值已经处于运算状态了,不可能再重新读取内存中的值,所以线程在线程1进行了赋值操作之后再将新i值刷新到内存中时,内存原来的线程2的值就被覆盖掉了。
所以,由上面的例子可见,可见性并不能保证数据的一致性,要保证数据一致性,还要有一个互斥条件:一个线程在操作数据的时候,另外一条线程不能进行同样的操作,这就是为什么上面的计数例子,即使计数的变量被volatile修饰也不能保证是线程安全的原因了:volatile仅仅保证了变量的可见性,而没有保证变量操作是互斥的。在对某个变量进行操作时,对于线程之间的操作结果是相互依赖的过程,只有对变量进行加锁才能保证数据的一致性。
三、java 的volatile关键字和线程安全。
1、volatile和线程安全
由上面的讨论之后,读者可能觉得volatile关键字显得有点鸡肋:它并不能保证线程安全,只能保证数据可见性。其实,volatile很多时候是用在初始化变量的时候,保证其他线程对最新赋值可见,在这点上,它比加锁的开销小,看下面的代码例子:
volatile int i = 0;
volatile int j = 1;
//下面这条语句时线程1执行的
j=1;
//线面这条语句是线程2执行的
i = j;
volatile 可以保证变量对各个线程都是可见的,例如上面的例子,被volatile修饰之后的变量,可以保证线程之间用到的i值都是最新的,当然,其实volatile在配合java并发下的其他工具使用会可以实现并发下更多的其他功能,这里不展开讨论
2、指令重排序问题与volatile关键字
什么是指令的重排序?在cpu实际执行程序时,为了提高速度,cpu会将“允许被打乱”的指令打乱后再执行,而编译器在编译的时候,也会对指令进行重排序以进行优化,这变导致了,程序执行的顺序,并不一定和我们编码顺序一样的,具体可看下面代码:
//指令重排序
int n = 0;
int m = 1;
上面的n和m的初始化顺序并不一定是先n在m,因为上面代码有可能会被编译器以及cpu进行指令的重排序。那么,代码什么时候会允许被重排序呢?其实我们可以这样理解:只要重排序之后的结果和非重排序结果在单线程环境下是一样的,代码便可以被重排序。也就是说,代码的前后再单线程环境下没有依赖关系时,便可进行重排序操作。例如上面这段代码,再单线程环境中,先初始化n或者先初始化m对程序的最终结果并没有影响,那么重排序边有可能发生,但是,诸如下面的代码,重排序是不会发生的:
int k = 0; int l = k;
因为上面的代码之间,l的值依赖k的值,所以这时,重排序条件并不满足,不会进行重排序。
要注意的是,重排序只是保证在单线程的环境下和非重排序前一致,所以,在多线程环境下,重排序会带来意向不到的结果,请看下面例子:
public class Demo2 extends Thread {
static int x = 0, y = 0, a = 0, b = 0;
public static void main(String[] args) throws Exception {
for (int i = 0; i < 1000; i++) {
x = y = a = b = 0;
Thread one = new Thread() {
public void run() {
a = 1;
x = b;
}
};
Thread two = new Thread() {
public void run() {
b = 1;
y = a;
}
};
one.start();
two.start();
one.join();
two.join();
System.out.println(x + " " + y);
}
}
}
上面的代码,分析之后,有可能出现10,01,但是其实在现代jvm内存模型中更是有可能出现00的,因为赋值操作之间在不同线程之间交换顺序是对在该线程下最终结果没有影响的,所以重排序有可能出现,不过由于程序复杂度问题,可能读者测试的该例子时候jvm不一定进行了指令重排序。但是,当程序复杂度提高之后,重排序效果会很明显的。
经过上面的举例子,相信读者对重排序的问题理解也更深刻了,那么重排序和volatile关键字又有什么关系呢?
其实,volatile关键字还有一个作用:被它修饰之后的变量,不会进行指令重排序,更具体地说,被volatile修饰之后变量,该变量之后的代码块,不会因为重排序而出现在该变量之前,该变量之前的代码块,也不会因为重排序而出现在该变量之后。所以,我们看到很多开源框架包括jdk源码,在设置某些阈值的时候,都会用volatile进行修饰,其目的就是防止指令重排序在多线程环境下导致意想不到的结果,比如下面的例子:
int k = 1; volatile boolean flag = false; int j = 0; int h = 2;
比如上面的例子,k=1的代码不可能在重排序之后位于flag=false之后,j=0和h=2也不可能在重排序之后出现在flag=false之前,当然,j=0和h=2之间是可以发生重排序的。总的来说,volatile关键字就像一堵墙,墙内和墙外之间的代码不能在重排序之后互相交换位置,但是墙的同一端还是可以进行指令重排序的。
那么,除了volatile关键字之外,jvm中,还有没有其他办法可以防止或者说有必要避免指令重排序呢?在jvm的内存模型中,有著名的happen-before原则,满足这些原则的指令都不可能进行指令重排序,下面详细讨论happen-before原则以及与之相关的多线程知识。
四、happen-before和线程安全
1、什么是happen-before?
前面说了,编译器以及cpu为了提高执行速率,会对代码编译后的指令进行重新优化排序。但是,当代码符合happen-before时,jvm规定不能进行重排序的,因为这会影响程序得出正确的结果;
原则一:对用一个lock ,unlock happen-before于lock操作。
原则二:线程启动动作必须happen-before于线程中所有动作。
原则三:一个线程对另一个线程的interrupt动作必须happen-before 与该线程感知到它被interrupt。
原则四:对象的构造函数运行完成happen-before 于finalizer的开始
原则五:单线程环境中,动作a出现在动作b之前,则a happen-before于b之前。
原则六:传递性,a happen-before b,b happen-before c,则a happen-before c。
下面对这些原则进行简单的说明:
原则1,可能读者会感到疑惑:解锁为什么会发生于加锁之前呢?不应该是先有加锁,然后才会有解锁吗?其实一开始我也有这样的疑惑,后来才知道,happen-before的意思不完全是描述程序动作的发生先后发生动作,它表示的意思是:如果a happen-before于b,则线程1进行a操作后,线程1的整个a操作过程以及造成的影响都是立即能被线程2接下来进行的b动作看到的(更多时候,我们仅仅理解了a和b是同一个线程的情况,没有深入理解a动作和b动作有可能发生在不同线程之间)。
然后,原则1就好理解了:它实际是这个意思,某个线程(线程1)对变量加锁动作必须要在另外一个线程(线程2)对该变量解锁后才能发生,并且线程1的解锁前的所有操作对线程2都是立即可见的,这期间不会有指令重排序造成的影响--指令重排序不可能将线程1解锁前的动作重排序到线程2加锁的动作之后。
按照常理以及上面的思路,原则2,3,4,6很好理解,这里不累赘了,下面再简单提提原则5,原则5什么意思?a书写在b前面,则a happen-before于b前面?不是说有可能发生指令重排序吗?其实,原则5的意思是说单线程环境下,程序可以在重排序之后保证和重排序结果一样,其实就是说jvm能保证程序正常逻辑不会变,但是该重排序的还是会重排序......(这尼玛不是在将废话吗,其实我也觉得)
2、线程安全
水了那么多,其实讨论上面那些的所有东西,都是为了让我们更好地理解线程安全。从java内存模型进行对线程安全的理解,你会发现很多模糊的东西瞬间就开窍了不少,所以,对于jvm的研究,是研究多线程必不可少的关键步骤,只有正确理解了java的内存模型,才能更好地理解java中的多线程工作机制。好了,就不说废话了,码了这么多字手好累。
学生党秋招干巴爹。